

腾讯云容器服务实战教程 - TKE Serverless 运行 ChatGLM-6B 微调
文档简介:
背景说明:
ChatGLM-6B 是一款拥有 62 亿参数的中英双语语言模型,专注于提供强大的对话和问答能力。通过对1:1中英语料进行 1T token 的预训练,使得模型具备双语应用的能力。借助模型量化技术,ChatGLM-6B 可以高效地在消费级显卡上部署。其最大序列长度达到2048,以应对更复杂的对话和应用需求。总体而言,ChatGLM-6B 是一款功能强大、适用广泛的语言模型。



背景说明
ChatGLM-6B 是一款拥有 62 亿参数的中英双语语言模型,专注于提供强大的对话和问答能力。通过对1:1中英语料进行 1T token 的预训练,使得模型具备双语应用的能力。借助模型量化技术,ChatGLM-6B 可以高效地在消费级显卡上部署。其最大序列长度达到2048,以应对更复杂的对话和应用需求。总体而言,ChatGLM-6B 是一款功能强大、适用广泛的语言模型。
ChatGLM-6B 也支持微调,针对特定任务或领域进行进一步训练,使得在特定任务上可以达到更好的性能。在本文中,我们将介绍下如何基于 TKE Serverless 集群,利用官方示例中提供的 P-Tuning v2 方法进行微调。
部署步骤
本文所展示的部署方案基于单张 V100显卡进行。
部署前提
创建 TKE Serverless 集群,操作详情请参见 创建 Serverless 集群。
创建 TCR 镜像仓库(个人版或者企业版),操作详情请参见 个人版快速入门。
开通 CFS 文件存储,操作详情请参见 创建文件系统及挂载点。
镜像准备
以 TCR 个人版镜像为例,并且使用的示例镜像命名为 ccr.ccs.tencentyun.com/chatglm/chatglm-6b-ptv2:v1.0。
注意:
在实际操作中,请将其替换为您自己的镜像名称。
接下来,我们将详细说明如何配置镜像的操作示例。
1. 代码下载
通过 Git 下载示例代码。执行以下命令:
git clone $ git clone https://github.com/coderwangke/tke-run-chatglm.githttps://github.com/coderwangke/tke-run-chatglm.git
2. 制作镜像
进入 tke-run-chatglm/finetune 目录,并使用 docker 命令制作镜像。执行以下命令:
cd tke-run-chatglm/finetunedocker build -f Dockerfile.V100 -t ccr.ccs.tencentyun.com/chatglm/chatglm-6b-ptv2:v1.0 .
该镜像将基于示例中的 Dockerfile.V100 文件创建。
3. 上传镜像
登录 容器镜像服务控制台 个人版镜像仓库,并将制作的镜像推送到仓库中。执行以下命令:
# 登录 TCR 个人版镜像仓库,请根据提示输入用户名和密码docker login ccr.ccs.tencentyun.comdocker push ccr.ccs.tencentyun.com/chatglm/chatglm-6b-ptv2:v1.0
注意:
在运行 docker login 时,请根据提示输入您的用户名和密码。
通过以上步骤,您将能够下载示例代码、制作镜像,并将镜像上传至个人版 TCR 镜像仓库。
存储准备
为了存储模型、数据、checkpoint 等文件,本文将使用腾讯云文件存储 CFS 作为示例。
目录划分
我们将使用以下目录结构进行存储:
models:用于存放模型数据,例如 ChatGLM-6B。
datasets:用于存储训练数据。
output:用于存放 checkpoint 等输出。
下载模型
在微调过程中,可以从 Hugging Face 仓库自动下载模型,但下载过程可能较慢,造成 GPU 资源的浪费。因此,建议预先将模型下载至 CFS 文件存储中的 /models 目录下。以下步骤基于 CVM 服务器执行:
1. 安装依赖。
以 TencentOS 为例,执行以下命令来安装依赖:
# 以 TencentOS 为例yum update && yum install git git-lfs -y
2. 挂载CFS文件存储(假设挂载点为 /data)。
执行以下命令来挂载 CFS 文件存储到 /data 目录:
sudo mount -t nfs -o vers=3,nolock,proto=tcp,noresvport xxx.xxx.xxx.xxx:/xxxx/ /data
3. 创建 models 子目录并下载模型。
执行以下命令来创建 /data/models 子目录并下载模型:
cd /data && mkdir -p modelscd modelsgit lfs installgit clone https://huggingface.co/THUDM/chatglm-6b
上传训练数据
本文使用 ADGEN(广告生成)数据集进行微调,数据集包括训练数据集 train.json 和验证数据集 dev.json,需要提前存放到 CFS 文件存储中的 /datasets 目录下。
说明:
您可以从 Tsinghua Cloud 下载处理好的 ADGEN 数据集。
创建存储
CFS 文件存储通过 PV/PVC 的方式挂载使用。以下示例以 CFS 标准型为例。
安装组件
1. 登录 容器服务控制台,在左侧导航栏中选择集群。
2. 在集群列表中,单击目标集群 ID,进入集群详情页。
3. 选择左侧菜单栏中的组件管理,在组件管理页面单击新建。
4. 在新建组件管理页面中勾选 CFS(腾讯云文件存储)。
5. 单击完成。
创建 PV
1. 在集群列表中,单击集群 ID,进入集群详情页。
2. 选择左侧菜单栏中的存储 > PersistentVolume,在 PersistentVolume 页面单击新建。
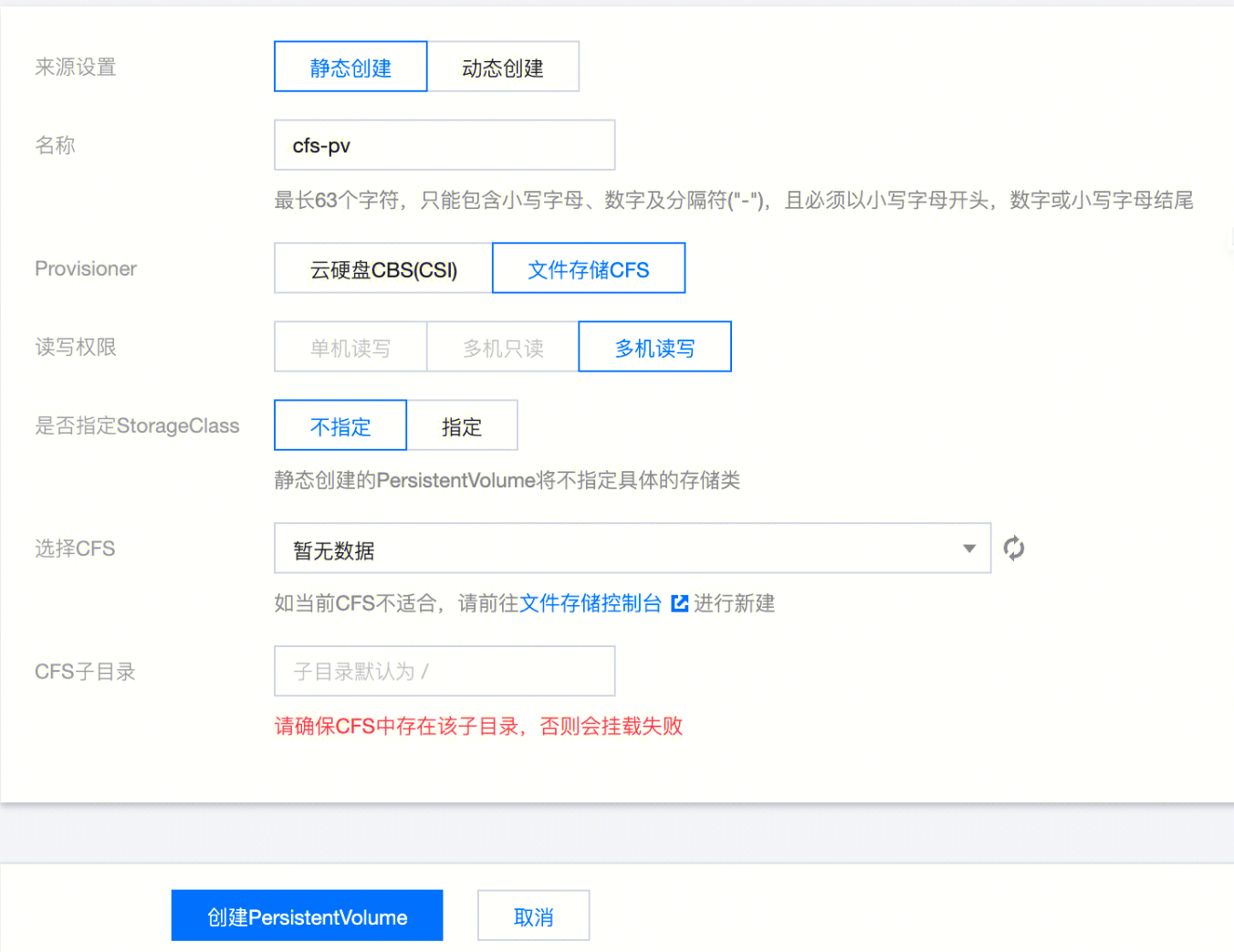
3. 在新建 PersistentVolume 页面中,配置 PV 关键参数。如下图所示:
|
配置项
|
描述
|
|
来源设置
|
选择静态创建。
|
|
名称
|
填写 cfs-pv。
|
|
Provisioner
|
选择文件存储 CFS。
|
|
读写权限
|
文件存储仅支持多机读写。
|
|
是否指定 StorageClass
|
选择不指定 StorageClass。
|
|
选择 CFS
|
请选择要挂载的 CFS ID。
|
|
CFS 子目录
|
请根据实际情况填写,默认是 /。
|
4. 单击创建 PersistentVolume。
创建 PVC
1. 在集群列表中,单击集群 ID,进入集群详情页。
2. 选择左侧菜单栏中的存储 > PersistentVolumeClaim,在 PersistentVolumeClaim 页面单击新建。
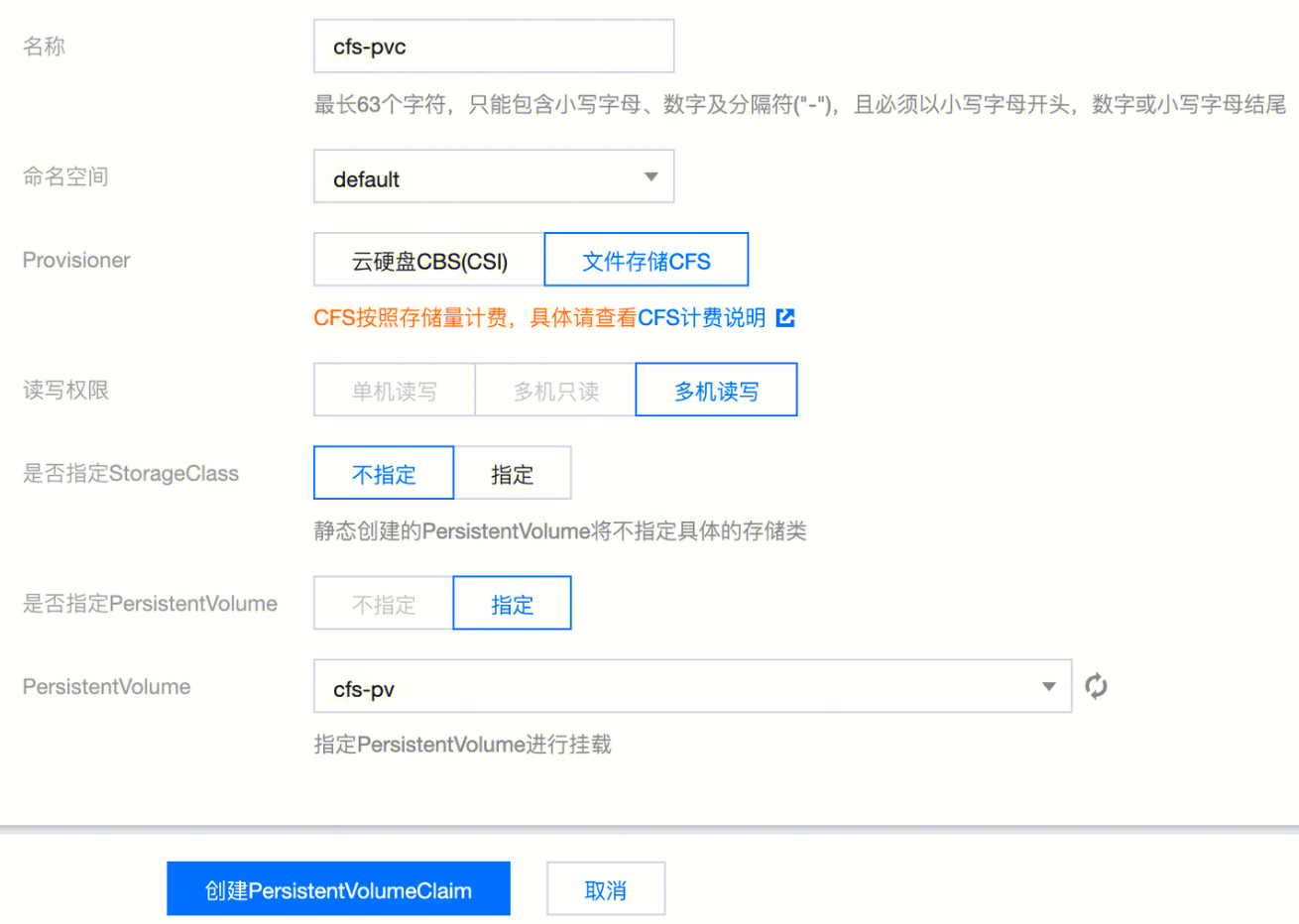
3. 在新建 PersistentVolumeClaim 页面中,配置 PVC 关键参数。如下图所示:
|
配置项
|
描述
|
|
名称
|
填写 cfs-pvc。
|
|
命名空间
|
请选择微调任务运行的命名空间。
|
|
Provisioner
|
选择文件存储 CFS。
|
|
读写权限
|
文件存储仅支持多机读写。
|
|
是否指定 StorageClass
|
选择不指定 StorageClass。
|
|
是否指定 PersistVolume
|
选择指定。
|
|
PersistentVolume
|
选择 创建 PV 步骤中创建的 PV。
|
4. 单击创建 PersistentVolumeClaim。
创建微调应用
1. 登录 容器服务控制台,在左侧导航栏中选择集群。
2. 在集群列表中,单击目标集群 ID,进入集群详情页。
3. 选择左侧菜单栏中的工作负载 > Job,在 Job 页面单击新建。
4. 在新建 Job 页面,设置 Job 参数。关键参数信息如下:
|
配置项
|
描述
|
|
实例类型
|
选择 GPU,和 V100。
|
|
系统盘大小
|
推荐调大到 50GiB。
|
|
数据卷
|
选择 创建 PVC 步骤中创建的 PVC。
|
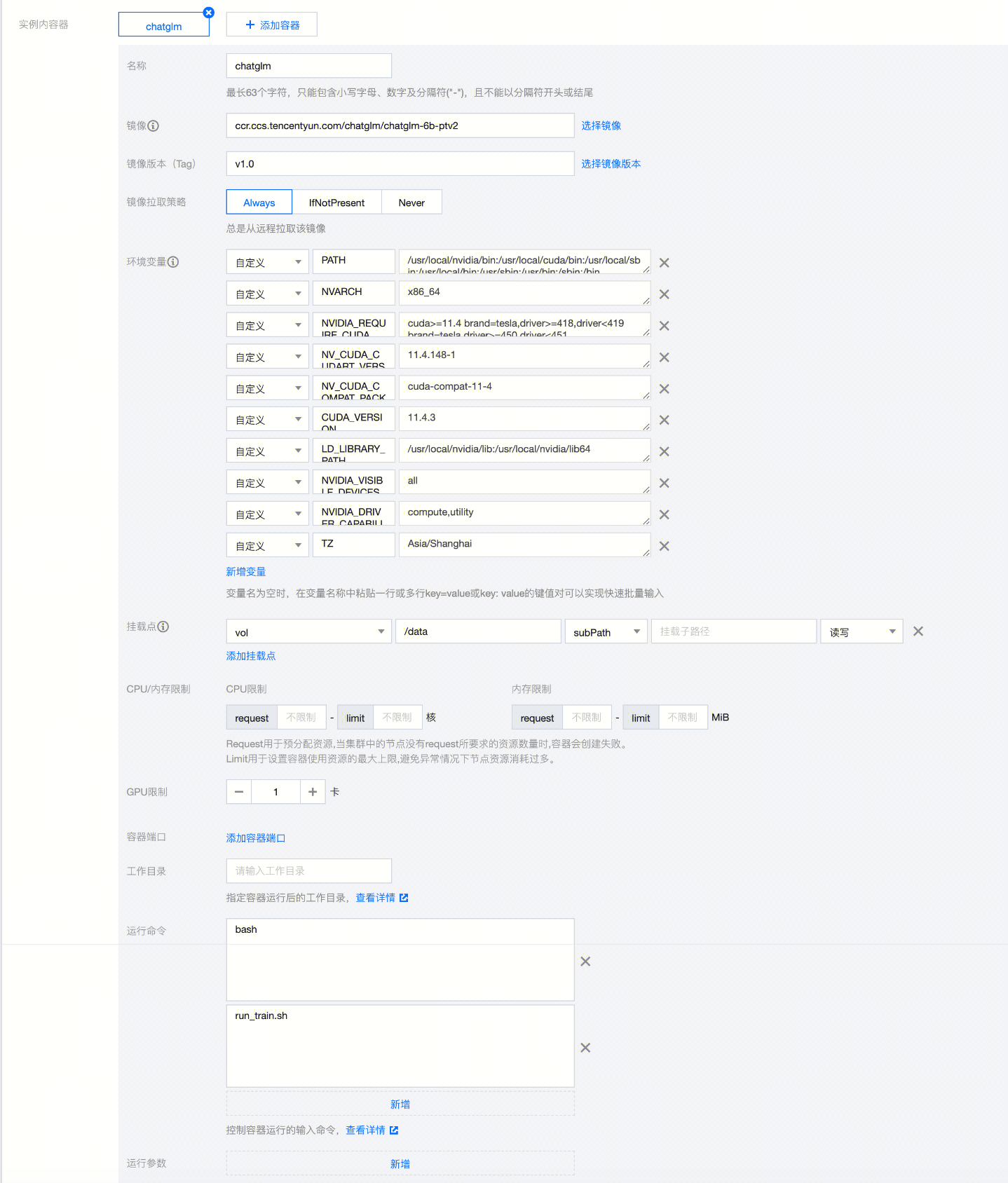
在实例内容器中,设置参数信息,如下图所示:
|
配置项
|
描述
|
|
名称
|
自定义名称。
|
|
镜像
|
填写 镜像准备 阶段制作的 docker 镜像名称。
|
|
挂载点
|
设置挂载的目标路径为 /data。
|
|
CPU/内存限制
|
由于微调的资源需要主要是 GPU,因此 CPU 和内存可以按需设置,示例设置为空。
|
|
GPU 限制
|
设置为1个。
|
|
运行命令
|
分别填写 bash、run_train.sh。
|
