

腾讯云高性能计算集群 - TI-Deepspeed NLP 大模型训练概述
文档简介:
背景信息:
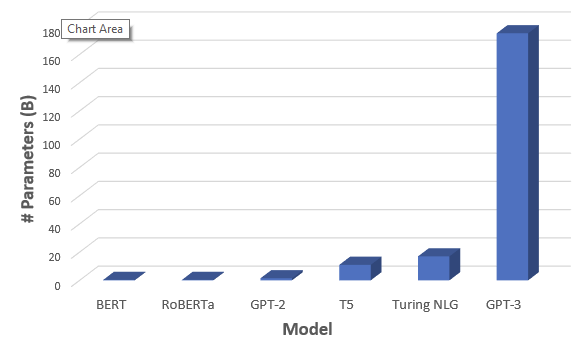
在当前人工智能趋势下,自然语言模型越大则提供的准确性越高。但由于成本、时间及代码无优化集成等问题,导致较大的模型难以训练。目前 GPT-3 的模型参数已经达到175B,模型参数的增长速度远超 GPU 显存的增长速度,数据并行和模型并行等传统优化方法在超大模型和过千亿参数面前也显现出了诸多瓶颈。



背景信息
在当前人工智能趋势下,自然语言模型越大则提供的准确性越高。但由于成本、时间及代码无优化集成等问题,导致较大的模型难以训练。目前 GPT-3 的模型参数已经达到175B,模型参数的增长速度远超 GPU 显存的增长速度,数据并行和模型并行等传统优化方法在超大模型和过千亿参数面前也显现出了诸多瓶颈。如下图所示:
为了使这些超大模型能够使用已有的硬件服务器训练,对应的解决方案需要在计算,通信和开发效率之间进行优化和权衡。Deepspeed 是微软开源的深度学习训练优化库,Deepspeed 通过 transformer kernel 性能优化、ZeRO(The Zero Redundancy Optimizer)显存优化及节省、提升模型 scale 能力等多个层面,对大模型训练做了详细的分析以及极致的性能优化,已经成为了超大 NLP 模型预训练的“利器”。
优化方案
TI-Deepspeed 是腾讯云 TI 平台团队在对 Deepspeed 调研和实践的基础上,从性能和易用性两方面对 Deepspeed 框架进行了相关优化的分布式训练框架。通过 TI-Deepspeed 显存节省技术、TI-Deepspeed 单机性能优化、TI-Deepspeed 多机可拓展性优化,并根据 NLP 大模型不同的参数规模沉淀出了完整且高性能的分布式训练方案。腾讯云 TI 平台团队旨在通过“一套框架“+”三套最佳实践”更好的服务有 NLP 预训练需求的客户。
训练平台
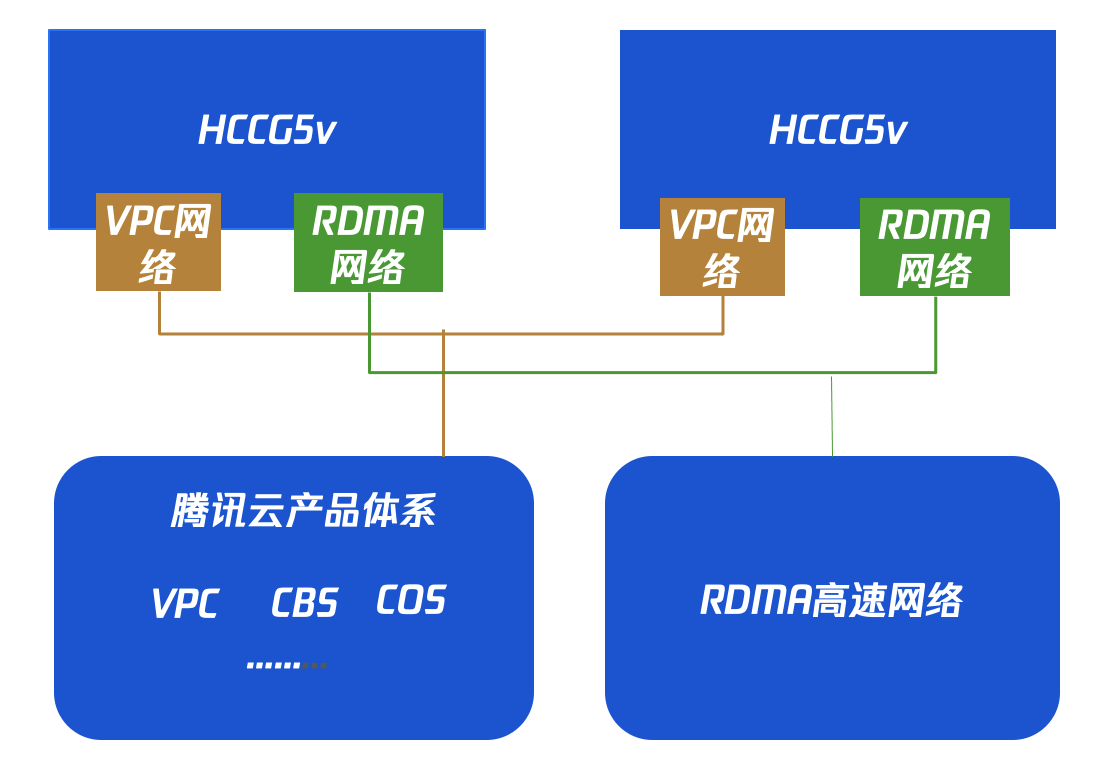
面向大规模机器学习训练场景,腾讯云推出了搭载 NVIDIA® Tesla® V100 GPU 和 100G 标准 RDMA 网卡的高性能裸金属云服务器 HCCG5v 实例,TI-Deepspeed 最佳实践选用该机型实例作为底层物理硬件平台。
大规模训练集群以 HCCG5v 实例为节点,通过 RDMA 互联,提供了高带宽和极低延迟的网络服务,能满足大规模高性能计算、人工智能、大数据推荐等应用的并行计算需求。如下图所示:
优化成果
百亿参数模型优化结果
腾讯云 TI 平台使用8台 HCCG5v 实例(共64卡 V100)训练83亿和100亿参数规模 GPT-2, 通过使用 zero-2 纯数据并行,每卡可以达到近 40TFLOPs 的性能。如下表所示:
|
参数
|
layers=50
hidden size=4096
attention head=32
sequence_length=1024
max-position-embeddings=1024
|
|
|
|
|
|
|
|
|
优化结果
|
global_bsz
|
bsz
|
model_parallel_size
|
forward
|
backward
|
step
|
iteration(ms)
|
TFlops/GPU
|
|
64*6=384
|
6
|
1
|
2464.89
|
9288.21
|
2400
|
13200
|
520/13.2 = 39.3
|
|
千亿参数模型训练优化结果
腾讯云 TI 平台使用 zero-stage3 结合 cpu offload,在8台 HCCG5v 实例(共64卡 V100)的有限资源下训练千亿模型,通过增大 batchsize,隐藏通信开销,提升训练效率。如下表所示:
|
参数
|
layers=480
hidden size=4096
attention head=32
sequence_length=1024
vocabulary_size= 50258→50304
|
|
|
|
|
|
|
|
|
|
优化结果
|
bsz
|
zero
|
cpu-offload
|
mp
|
dp
|
globsz
|
iteration
|
TFlops/GPU
|
gpu/cpu 内存占用
|
|
1
|
stage3
|
no
|
8
|
8
|
8
|
83s
|
1.2
|
-
|
|
|
0
|
stage3
|
yes
|
8
|
8
|
48
|
85.7s
|
6.8 - 7
|
显存接近极致,内存220G
|
|
实践步骤
实践具体操作步骤请参见 部署及实践。
