

腾讯云高性能计算集群 - TI-Deepspeed NLP 大模型训练部署及实践
文档简介:
本文介绍在裸金属云服务器 HCCG5v 实例上训练 TI-Deepspeed 大模型的具体步骤。
示例操作环境:
本文中 TI-Deepspeed 大模型训练操作环境说明如下:
硬件平台:8台 HCCG5v 实例高性能计算集群、
操作系统版本:CentOS 7.6、
GPU 驱动版本:418.67、
CUDA 版本:10.1、
文件存储 CFS:创建文件系统及挂载点。



本文介绍在裸金属云服务器 HCCG5v 实例上训练 TI-Deepspeed 大模型的具体步骤。
示例操作环境
本文中 TI-Deepspeed 大模型训练操作环境说明如下:
硬件平台:8台 HCCG5v 实例高性能计算集群
操作系统版本:CentOS 7.6
GPU 驱动版本:418.67
CUDA 版本:10.1
文件存储 CFS:创建文件系统及挂载点
说明事项
使用 HCCG5v 实例需通过申请,请前往 高性能计算集群申请 完成申请。
操作步骤
创建高性能计算集群
创建集群
1. 登录云服务器控制台,选择左侧导航栏中的高性能计算集群。
2. 在高性能计算集群页面上方,选择上海地域,并单击新建。
目前 HCCG5v 实例仅支持在上海地域使用。
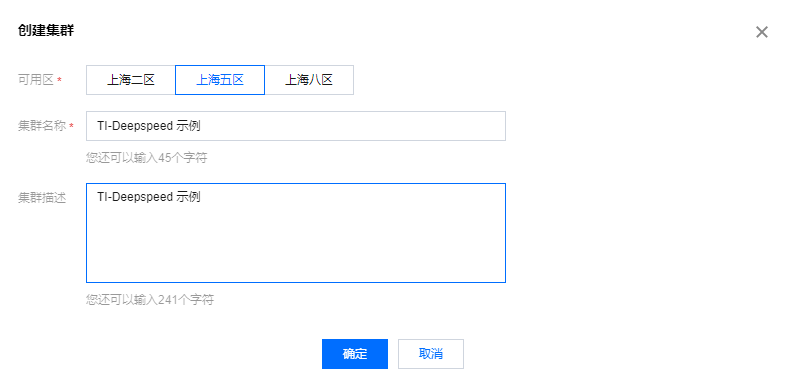
3. 在弹出的创建集群页面中,按需选择可用区、输入集群名及描述,单击确定创建集群。
本文创建集群可用区、集群名、描述如下图所示:
创建 HCCG5v 实例
参见 自定义配置 Linux 云服务器 进行创建。其中,实例需选择高性能计算集群 > GPU型高性能计算实例HCCG5v。
创建 CFS
注意
CFS 需与高性能计算集群在同一可用区。
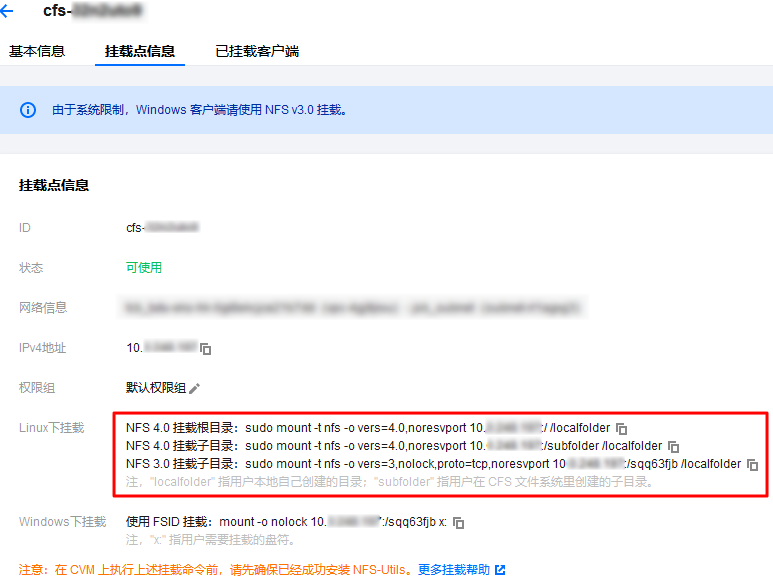
参见 创建文件系统及挂载点,创建 CFS 并获取挂载命令。本文以创建名称为 TI-Deepspeed示例的 CFS 为例,获取挂载命令如下图所示:
挂载 CFS
1. 参见 使用标准登录方式登录 Linux 实例(推荐),登录实例。
2. 执行以下命令,安装 nfs-utils。
sudo yum install nfs-utils
3. 执行以下命令,创建待挂载目标目录 /cfs。
mkdir /cfs
4. 执行以下命令,将本地目录挂载到 CFS 根目录下。命令中 IP 为示例 IP,请您以 CFS 挂载点信息获取的 IP 为准。
sudo mount -t nfs -o vers=4.0,noresvport 10.0.0.7:/ /cfs
5. 执行以下命令,创建个人文件夹 ti-deepspeed-demo。
由于最佳实践均为多机运行程序,运行 demo 需要存储在不同机器上同一位置,建议将运行 demo 数据集都存储在 cfs 的个人文件夹中。
mkdir /cfs/ti-deepspeed-demo
更多挂载 CFS 信息,请参见 在 Linux 客户端上使用 CFS 文件系统。
安装相关依赖
安装 NVIDIA Tesla 驱动
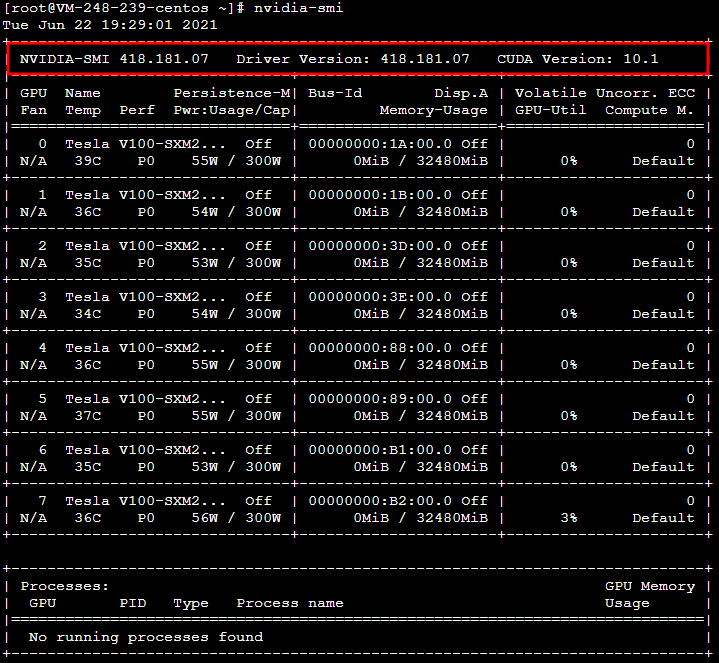
参见 安装 NVIDIA Tesla 驱动 进行 NVIDIA GPU V100 显卡驱动安装。安装成功后结果如下图所示:
安装 CUDA 驱动
参见 安装 CUDA 驱动 进行 cuda tookit 安装。其中,cuda 版本建议选择 CUDA Toolkit 10.1 update2,该版本解决了部分 gcc 编译问题。
注意
重启实例后需重新挂载 CFS,挂载步骤请参见 挂载 CFS。
安装成功后结果如下图所示:

安装 conda 环境
1. 执行以下命令,下载安装脚本。
wget -c https://repo.continuum.io/miniconda/Miniconda3-latest-Linux-x86_64.sh
2. 执行以下命令,授予脚本权限。
chmod 777 Miniconda3-latest-Linux-x86_64.sh
3. 执行以下命令,运行脚本,安装 conda。
bash Miniconda3-latest-Linux-x86_64.sh
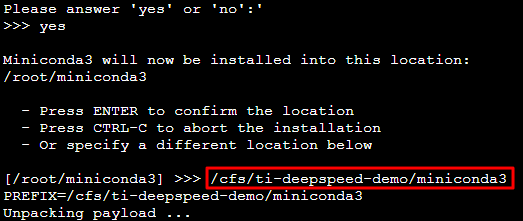
按照界面提示输入提示信息及 conda 安装目录。请将 conda 安装在 /cfs/ti-deepspeed-demo 目录下,安装至该目录则仅需安装一次软件依赖,不需要在每个节点上重复安装。
如下图所示,本文以安装至 /cfs/ti-deepspeed-demo/miniconda3 目录为例:
4. 执行以下命令,配置 torch1.7 环境。
conda create --name torch1.7 python=3.8
在每个节点的 ~/.bashrc 里面添加如下命令,确保每个节点使用同样的 conda 环境。
conda activate torch1.7
配置机器免密登录及安装 openmpi
由于百亿/千亿模型最佳实践均为8机64卡训练,按照一般分布式训练要求,机器需要提前做好免密登录,并安装好 openmpi。步骤如下:
1. 执行以下命令,下载 openmpi 安装包。
wget https://download.open-mpi.org/release/open-mpi/v4.1/openmpi-4.1.1.tar.gz
2. 执行以下命令,解压 openmpi 安装包。
tar -zxvf openmpi-4.1.1.tar.gz
3. 依次执行以下命令,安装 openmpi。
cd openmpi-4.1.1/
./configure
make && sudo make install
4. 执行以下命令,验证 openmpi 是否安装成功。
which mpicc
返回结果如下图所示,则表明已成功安装。

安装 pytorch
执行以下命令,安装 pytorch。需要安装 pytorch gpu 版本,推荐使用 torch1.7 版本。
pip install torch==1.7.1+cu101 torchvision==0.8.2+cu101 torchaudio==0.7.2 -f https://download.pytorch.org/whl/torch_stable.html
说明
如因网络超时导致 torch 安装失败,建议下载离线包上传到服务器进行安装。
下载地址:https://download.pytorch.org/whl/torch_stable.html
torch 版本:cu101/torch-1.7.1%2Bcu101-cp38-cp38-linux_x86_64.whl
安装 apex
百亿/千亿模型通过混合精度加速训练,需安装 apex。步骤如下:
1. 执行以下命令,确认 gcc 版本。
gcc --version
apex 安装需要依赖 gcc 5.0 以上版本,如需升级 gcc,请依次执行以下命令。
yum install centos-release-scl -y
yum install devtoolset-7 -y
scl enable devtoolset-7 bash
gcc --version
source /opt/rh/devtoolset-7/enable
2. 依次执行以下命令,下载并安装 apex。
yum install git -y
git clone https://github.com/NVIDIA/apex
cd apex
pip install -v --disable-pip-version-check --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" ./
安装 ti-deepspeed 框架
依次执行以下命令,通过 whl 包安装 ti-deepspeed 框架,该框架仅支持在腾讯云裸金属机器上使用。
wget https://tids-1259675134.cos.ap-nanjing.myqcloud.com/deepspeed-0.3.14%2Bunknown-cp38-cp38-linux_x86_64.whl
pip install deepspeed-0.3.14+unknown-cp38-cp38-linux_x86_64.whl
检查依赖环境
完成依赖软件配置步骤后,请查看依赖软件及版本是否符合下表:
|
依赖软件
|
版本
|
|
cuda toolkit
|
10.1
|
|
openmpi
|
版本不限制
|
|
torch
|
1.7.1+cu101
|
|
apex
|
github master 分支
|
检查运行环境
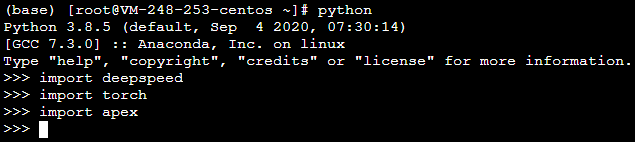
1. 切换至 python 环境并执行以下命令,检查运行环境是否正常。
import deepspeed
import torch
import apex
返回结果如下图所示,则表明运行环境正常。
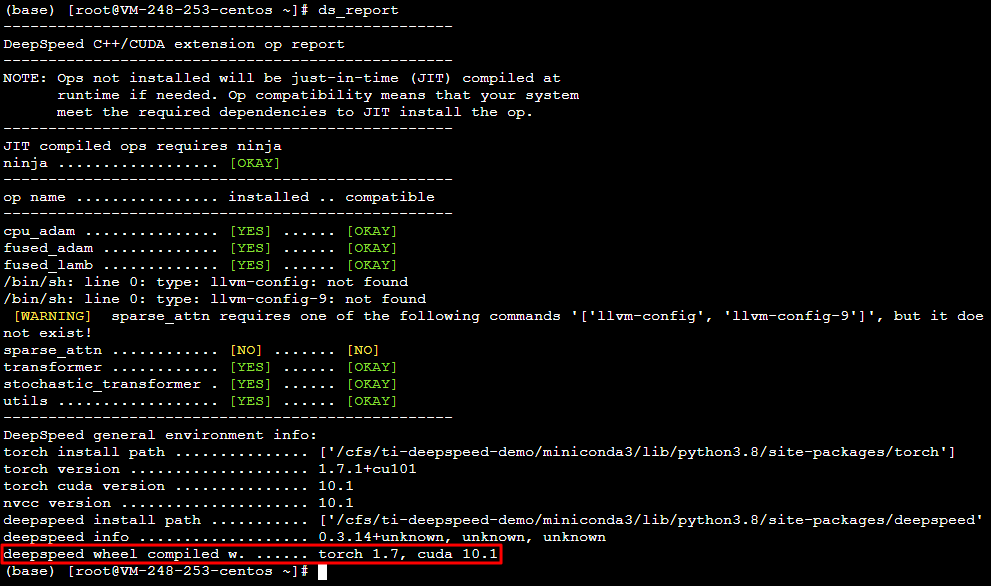
2. 执行 ds_report 命令,返回如下图所示结果,则表明运行环境正常。
下载 demo 数据及脚本
运行百亿/千亿模型最佳实践,需下载以下内容:
|
下载内容
|
COS 存储名称
|
|
ti-ds 框架 whl 包
|
deepspeed-0.3.14+unknown-cp38-cp38-linux_x86_64.whl
|
|
百亿/千亿模型最佳实践
|
ti-deepspeed-examples.zip
|
|
百亿模型训练集
|
webtext.tgz
|
|
千亿模型训练集
|
100B.tar.gz
|
1. 依次执行以下命令,将 ti-deepspeed 百亿/千亿最佳实践 demo 下载至已创建的 CFS 中。本文以下载至 /cfs/ti-deepspeed-demo 目录为例:
cd /cfs/ti-deepspeed-demo
wget https://tids-1259675134.cos.ap-nanjing.myqcloud.com/ti-deepspeed-examples.zip
2. 执行以下命令,解压 demo。
unzip ti-deepspeed-examples.zip
运行 demo 程序
百亿模型实践
1. 依次执行以下命令,下载百亿模型训练集至已创建的 CFS 中。本文以下载至 /cfs/ti-deepspeed-demo 目录下为例:
cd /cfs/ti-deepspeed-demo
wget https://tids-1259675134.cos.ap-nanjing.myqcloud.com/webtext.tgz
2. 执行以下命令,解压百亿模型训练集。
tar xvf webtext.tgz
3. 执行以下命令,进入 demo 目录。
cd ti-deepspeed-examples/Megatron-LM
4. 根据实际情况修改启动脚本 scripts/multirun-10B.sh,启动脚本介绍如下图所示:
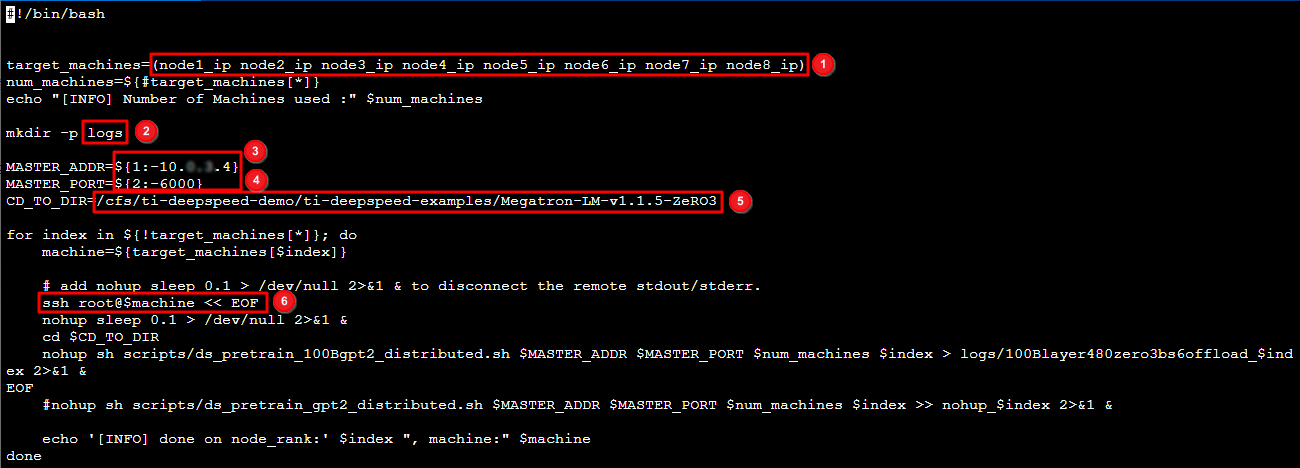
4.1 8台机器的内网 IP 地址,可前往 实例 列表页面获取。
4.2 创建日志文件夹 logs。
4.3 launch job 的 IP 信息。
4.4 torch ddp 连接的端口信息,需确保该端口未被占用。
4.5 运行目录。
4.6 表示依次 ssh 到各个节点,启动 ddp。
5. 执行以下命令,启动脚本。
sh scripts/multirun-10B.sh
启动脚本在每台机器节点上运行实际训练脚本。脚本位置为 scripts/ds_pretrain_10Bgpt2_distributed.sh。内容如下:
#数据集位置,从cos上拉取获得DATA_PATH=/cfs/ti-deepspeed-demo/webtext/data.json#模型输出CHECKPOINT_PATH=./outputDISTRIBUTED_ARGS="--nproc_per_node $GPUS_PER_NODE --nnodes $NNODES --node_rank $NODE_RANK
--master_addr $MASTER_ADDR --master_port $MASTER_PORT"
#超参数设置python -m torch.distributed.launch $DISTRIBUTED_ARGS \pretrain_gpt2.py \--deepspeed \--deepspeed_config ./scripts/debug-10B.json \--model-parallel-size 1 \--num-layers 50 \--hidden-size 4096 \--num-attention-heads 32 \--batch-size 6 \--seq-length 1024 \--max-position-embeddings 1024 \--train-iters 500000 \--save $CHECKPOINT_PATH \--train-data $DATA_PATH \--lazy-loader \--tokenizer-type GPT2BPETokenizer \--split 949,50,1 \--distributed-backend nccl \--lr 0.00015 \--lr-decay-style cosine \--weight-decay 1e-2 \--clip-grad 1.0 \--warmup .01 \--checkpoint-activations \--log-interval 1 \--save-interval 10000 \--eval-interval 1000 \--eval-iters 10 \--fp16
6. 根据实际情况修改暂停脚本 scripts/all-kill.sh,并根据实际需要执行。
sh scripts/all-kill.sh
训练日志如下:

千亿模型实践
1. 依次执行以下命令,下载千亿模型训练集至已创建的 CFS 中。本文以下载至 /cfs/ti-deepspeed-demo/datasets 目录下为例:
mkdir /cfs/ti-deepspeed-demo/datasets
wget https://tids-1259675134.cos.ap-nanjing.myqcloud.com/100B.tar.gz
2. 执行以下命令,解压迁移模型训练集。
tar xvf 100B.tar.gz
3. 执行以下命令,进入 demo 目录。
cd ti-deepspeed-examples/Megatron-LM-v1.1.5-ZeRO3
4. 根据实际情况修改启动脚本 scripts/multirun100Boffload.sh,启动脚本介绍如下图所示:
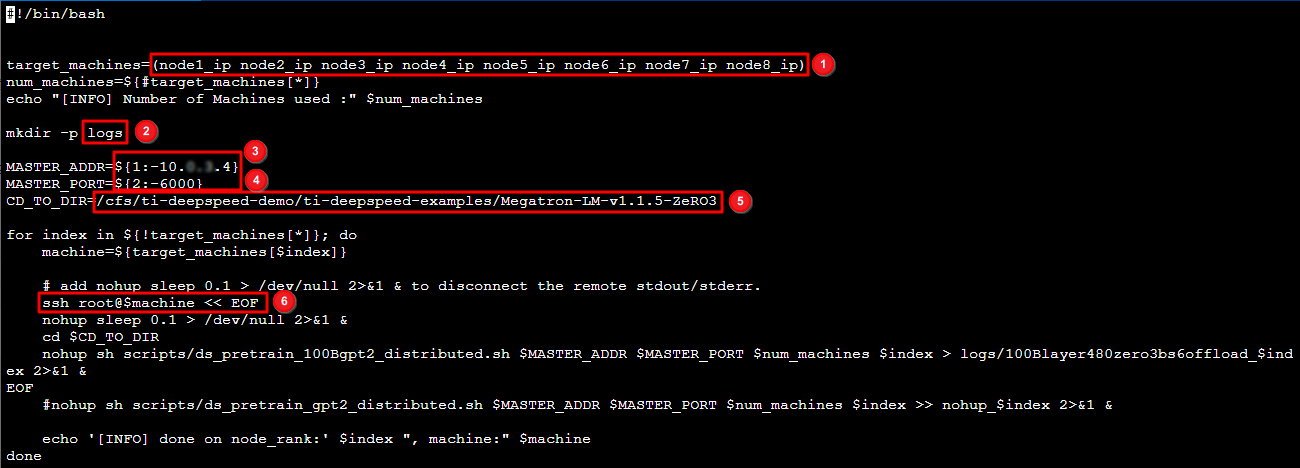
4.1 8台机器的内网 IP 地址,可前往 实例 列表页面获取。
4.2 创建日志文件夹 logs。
4.3 launch job 的 IP 信息。
4.4 torch ddp 连接的端口信息,需确保该端口未被占用。
4.5 运行目录。
4.6 表示依次 ssh 到各个节点,启动 ddp。
5. 执行以下命令,启动脚本。
sh scripts/multirun100Boffload.sh
启动脚本在每台机器节点上运行实际训练脚本。脚本位置为 scripts/ds_pretrain_100Bgpt2_distributed.sh。内容如下:
#! /bin/bash# Runs the "345M" parameter modelGPUS_PER_NODE=8MASTER_ADDR=${1:-localhost}MASTER_PORT=${2:-6000}NNODES=${3:-1}NODE_RANK=${4:-0}WORLD_SIZE=$(($GPUS_PER_NODE*$NNODES))#数据集位置,从cos上拉取获得DATA_PATH=/cfs/ti-deepspeed-demo/datasets/db_text_documentVOCAB_PATH=./gpt2-vocab.jsonMERGE_PATH=./gpt2-merges.txtCHECKPOINT_PATH=./outputDISTRIBUTED_ARGS="--nproc_per_node $GPUS_PER_NODE --nnodes $NNODES --node_rank $NODE_RANK
--master_addr $MASTER_ADDR --master_port $MASTER_PORT"
python -m torch.distributed.launch $DISTRIBUTED_ARGS \pretrain_gpt2.py \--deepspeed \--deepspeed_config ./scripts/100B.json \--model-parallel-size 8 \--num-layers 480 \--hidden-size 4096 \--num-attention-heads 32 \--batch-size 6 \--seq-length 1024 \--max-position-embeddings 1024 \--train-iters 500000 \--save $CHECKPOINT_PATH \--data-path $DATA_PATH \--vocab-file $VOCAB_PATH \--merge-file $MERGE_PATH \--tokenizer-type GPT2BPETokenizer \--split 949,50,1 \--distributed-backend nccl \--lr 0.00015 \--lr-decay-style cosine \--weight-decay 1e-2 \--clip-grad 1.0 \--warmup .01 \--log-interval 1 \--save-interval 10000 \--eval-interval 1000 \--eval-iters 10 \--fp16 \--cpu-optimizer \
