

文档简介:



当我们苦于听到一段熟悉的旋律而不得其名,看到一段电影片段而不知其出处,心中不免颇有遗憾。在另外一些场景,我们偶然间在某些音乐平台、视频平台的推荐页面找到了心仪的音乐、电影,内心却是极其激动的。这些背后往往离不开推荐系统的影子。
那究竟什么是推荐系统呢?
在此之前,我们先了解一下推荐系统产生的背景。
推荐系统的产生背景
互联网和信息计算的快速发展,衍生了海量的数据,我们已经进入了一个信息爆炸的时代,每时每刻都有海量信息产生,然而这些信息并不全是个人所关心的,用户从大量的信息中寻找对自己有用的信息也变得越来越困难。另一方面,信息的生产方也在绞尽脑汁的把用户感兴趣的信息送到用户面前,每个人的兴趣又不尽相同,所以可以实现千人千面的推荐系统应运而生。简单来说,推荐系统是根据用户的浏览习惯,确定用户的兴趣,通过发掘用户的行为,将合适的信息推荐给用户,满足用户的个性化需求,帮助用户找到对他胃口但是不易找到的信息或商品。
推荐系统在互联网和传统行业中都有着大量的应用。在互联网行业,几乎所有的互联网平台都应用了推荐系统,如资讯新闻/影视剧/知识社区的内容推荐、电商平台的商品推荐等;在传统行业中,有些用于企业的营销环节,如银行的金融产品推荐、保险公司的保险产品推荐等。根据QM报告,以推荐系统技术为核心的短视频行业在2019年的用户规模已超8.2亿,市场规模达2千亿,由此可见这项技术在现代社会的经济价值。
图1:随处可见的推荐系统
推荐系统的经济学本质
随着现代工业和互联网的兴起,长尾经济变得越来越流行。在男耕女织的农业时代,人们以“个性化”的模式生产“个性化”的产品;在流水线模式的工业化时代,人们以“规模化”的模式生产“标准化”的产品;而在互联网和智能制造业不断发展的今天,人们以“规模化”的模式生产“个性化”的产品,极大地丰富了商品种类。在此情况下,用户的注意力和消费力变成极为匮乏的资源。如何从海量的产品和服务中选择自己需要的,成为用户第一关心的事,这就是推荐系统的价值所在。但每个人的喜好极具个性化,例如年轻人偏爱健身的内容,而父母一代偏爱做菜的内容,如果推荐内容相反,用户会非常不满。正所谓此之甘露,彼之砒霜,基于个性化需求进行推荐是推荐系统的关键目标。
图2:长尾经济
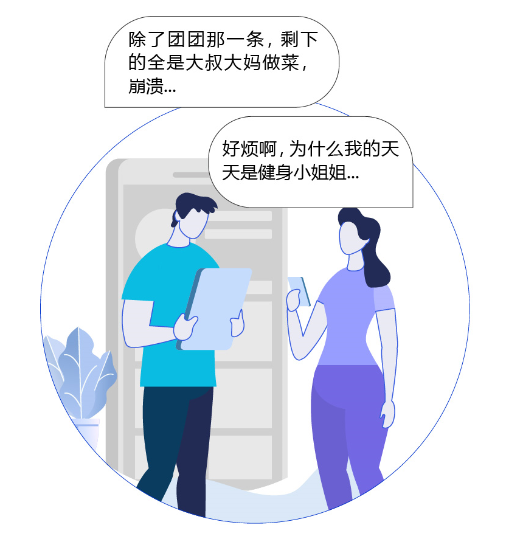
图3:此之甘露,彼之砒霜
推荐系统的基本概念
构建推荐系统本质上是要解决“5W”的问题。如下图示例,当用户在晚间上网阅读军事小说时,系统在小说的底部向他推荐三国志游戏,并给出了推荐理由“纸上谈兵不如亲身实践”。
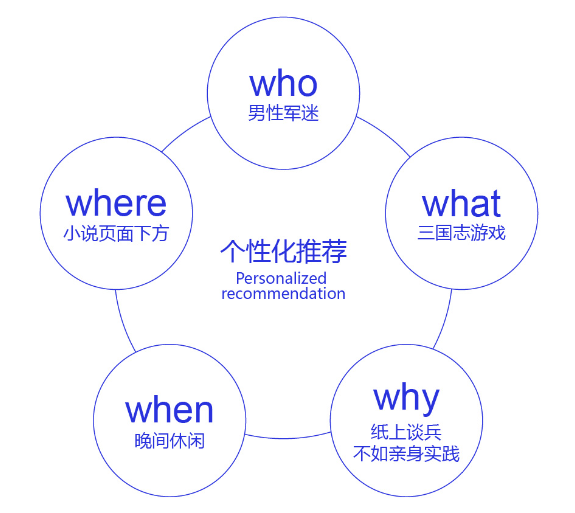
图4:个性化推荐解决5W问题
这是一个较好的推荐案例,很多军迷用户会下载游戏试玩。但反之,如果在用户白天开会投屏时,弹出提示框向用户推荐“巴厘岛旅游”,会给在场的同事留下不认真工作的印象,用户也会非常的恼火。可见,除了向谁(Who)推荐什么(What)之外,承载推荐的产品形式(Where)和推荐时机(When)也非常重要。
另外给出推荐理由(Why)会对推荐效果产生帮助吗? 答案是肯定的。心理学家艾伦·兰格做过一个“合理化行为”的实验,发现在提供行动理由的情况下,更容易说服人们采取行动,因为人们会认为自己是“合乎逻辑”的人。
艾伦设计了排队打印的场景,一个实验者想要插队,通过不同的请求方式,观测插队成功的概率。他做了三组实验:
- 第一组:请求话术“打搅了,我有5页资料要复印,能否让我先来?” — 有60%的成功概率。
- 第二组:请求话术中加入合理的理由“因为……(如赶时间)” — 成功率上升到94%。
- 第三组:请求话术变成无厘头的理由“我能先用下复印机吗?因为我有东西要印。” — 成功率仅略有下降,达到93%。
由此可见,哪怕我们提供一个不太靠谱的推荐理由,用户接受推荐的概率都会大大提高。
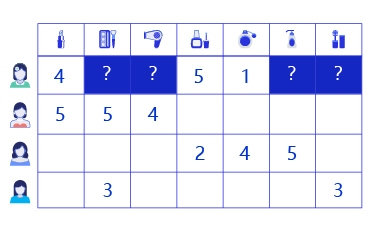
虽然完整的推荐系统需要考虑“5w”问题,但向谁(who)推荐什么(what)是问题的核心。所以,本章我们介绍一个解决这两个核心问题的推荐系统。使用的数据和推荐任务如下图所示,已知用户对部分内容的评分(分数范围1~5分,分数越高代表越喜欢),推测他们对未评分内容的评分,并据此进行推荐。
图5:只保留两个核心问题的推荐任务
思考有哪些信息可以用于推荐
观察只保留两个核心问题的推荐任务示例,思考有哪些信息可以用于推荐? 图中蕴含的数据可以分为三种:
- 每个用户的不同特征,如性别、年龄;
- 物品的各种描述属性,如品牌、品类;
- 用户对部分物品的兴趣表达,即用户与物品的关联数据,如历史上的评分、评价、点击行为和购买行为。
结合这三种信息可以形成类似“女性A 喜欢 LV包”这样的表达。

图6:推荐任务的思考
基于3的关联信息,人们设计了“协同过滤的推荐算法”。基于2的内容信息,设计出“基于内容的推荐算法”。现在的推荐系统普遍同时利用这三种信息,下面我们就来看看这些方法的原理。
常用的推荐系统算法
常用的推荐系统算法实现方案有三种:
-
协同过滤推荐(Collaborative Filtering Recommendation):该算法的核心是分析用户的兴趣和行为,利用共同行为习惯的群体有相似喜好的原则,推荐用户感兴趣的信息。兴趣有高有低,算法会根据用户对信息的反馈(如评分)进行排序,这种方式在学术上称为协同过滤。协同过滤算法是经典的推荐算法,经典意味着简单、好用。协同过滤算法又可以简单分为两种:
a)基于用户的协同过滤:根据用户的历史喜好分析出相似兴趣的人,然后给用户推荐其他人喜欢的物品。假如小李,小张对物品A、B都给了十分好评,那么可以认为小李、小张具有相似的兴趣爱好,如果小李给物品C十分好评,那么可以把C推荐给小张,可简单理解为“人以类聚”。
b)基于物品的协同过滤:根据用户的历史喜好分析出相似物品,然后给用户推荐同类物品。比如小李对物品A、B、C给了十分好评,小王对物品A、C给了十分好评,从这些用户的喜好中分析出喜欢A的人都喜欢C,物品A、C是相似的,如果小张给了A好评,那么可以把C也推荐给小张,可简单理解为“物以群分”。
-
基于内容过滤推荐(Content-based Filtering Recommendation):基于内容的过滤是信息检索领域的重要研究内容,是更为简单直接的算法,该算法的核心是衡量出两个物品的相似度。首先对物品或内容的特征作出描述,发现其相关性,然后基于用户以往的喜好记录,推荐给用户相似的物品。比如,小张对物品A感兴趣,而物品A和物品C是同类物品(从物品的内容描述上判断),可以把物品C也推荐给小张。
-
组合推荐(Hybrid Recommendation):以上算法各有优缺点,比如基于内容的过滤推荐是基于物品建模,在系统启动初期往往有较好的推荐效果,但是没有考虑用户群体的关联属性;协同过滤推荐考虑了用户群体喜好信息,可以推荐内容上不相似的新物品,发现用户潜在的兴趣偏好,但是这依赖于足够多且准确的用户历史信息。所以,实际应用中往往不只采用某一种推荐方法,而是通过一定的组合方法将多个算法混合在一起,以实现更好的推荐效果,比如加权混合、分层混合等。具体选择哪种方式和应用场景有很大关系。
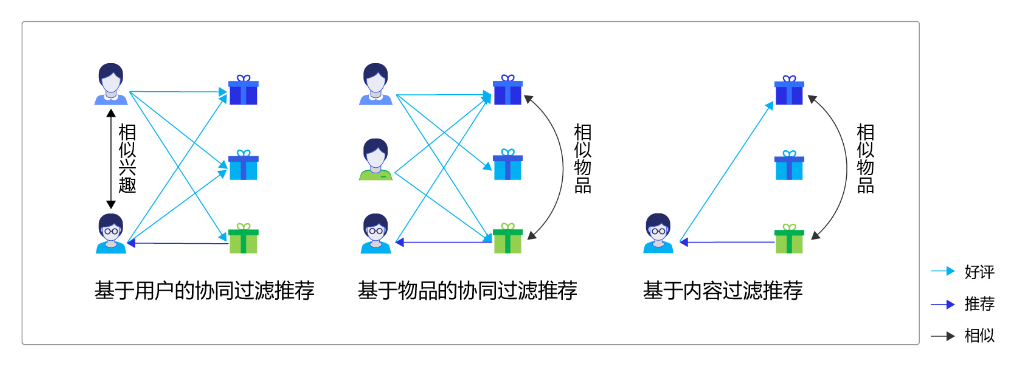
图7:常见的推荐系统算法
数据集介绍
个性化推荐算法的数据大多是文本和图像。比如网易云音乐推荐中,数据是音乐的名字、歌手、音乐类型等文本数据;抖音视频推荐中,数据是视频或图像数据;也有可能同时使用图像和文本数据,比如YouTube的视频推荐算法中,会同时考虑用户信息和视频类别、视频内容信息。
本次实践我们采用ml-1m电影推荐数据集,它是GroupLens Research从MovieLens网站上收集并提供的电影评分数据集。包含了6000多位用户对近3900个电影的共100万条评分数据,评分均为1~5的整数,其中每个电影的评分数据至少有20条。该数据集包含三个数据文件,分别是:
- users.dat:存储用户属性信息的文本格式文件。
- movies.dat:存储电影属性信息的文本格式文件。
- ratings.dat:存储电影评分信息的文本格式文件。
另外,为了验证电影推荐的影响因素,我们还从网上获取到了部分电影的海报图像。现实生活中,相似风格的电影在海报设计上也有一定的相似性,比如暗黑系列和喜剧系列的电影海报风格是迥异的。所以在进行推荐时,可以验证一下加入海报后,对推荐结果的影响。 电影海报图像在posters文件夹下,海报图像的名字以"mov_id" + 电影ID + ".png"的方式命名。由于这里的电影海报图像有缺失,我们整理了一个新的评分数据文件,新的文件中包含的电影均是有海报数据的,因此,本次实践使用的数据集在ml-1m基础上增加了两份数据:
- posters:包含电影海报图像。
- new_rating.txt:存储包含海报图像的新评分数据文件。
用户信息、电影信息和评分信息包含的内容如下表所示。
| 用户信息 | UserID | Gender | Age | Occupation |
|---|---|---|---|---|
| 样例 | 1 | F【M/F】 | 1 | 10 |
| 电影信息 | MovieID | Title | Genres | PosterID |
|---|---|---|---|---|
| 样例 | 1 | Toy Story | Animation| Children’s|Comedy | 1 |
| 评分信息 | UserID | MovieID | Rating |
|---|---|---|---|
| 样例 | 1 | 1193 | 5【1~5】 |
其中部分数据并不具有真实的含义,而是编号。年龄编号和部分职业编号的含义如下表所示。
| 年龄编号 | 职业编号 |
|---|---|
|
|
海报对应着尺寸大约为180*270的图片,每张图片尺寸稍有差别。

图8:1号海报的图片
从样例的特征数据中,我们可以分析出特征一共有四类:
- ID类特征:UserID、MovieID、Gender、Age、Occupation,内容为ID值,前两个ID映射到具体用户和电影,后三个ID会映射到具体分档。
- 列表类特征:Genres,每个电影有多个类别标签。如果将电影类别编号,使用数字ID替换原始类别,特征内容是对应几个ID值的列表。
- 图像类特征:Poster,内容是一张180×270的图片。
- 文本类特征:Title,内容是一段英文文本。
因为特征数据有四种不同类型,所以构建模型网络的输入层预计也会有四种子结构。
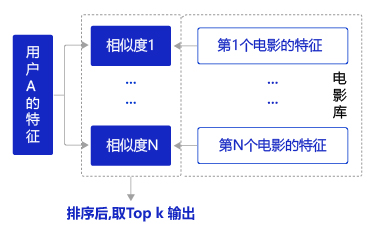
如何获得有效特征
如何获取两种有效代表用户和电影的特征向量?首先,需要明确什么是“有效”?
对于用户评分较高的电影,电影的特征向量和用户的特征向量应该高度相似,反之则相异。
我们已经获得大量评分样本,因此可以构建一个训练模型如下图所示,根据用户对电影的评分样本,学习出用户特征向量和电影特征向量的计算方案(灰色箭头)。
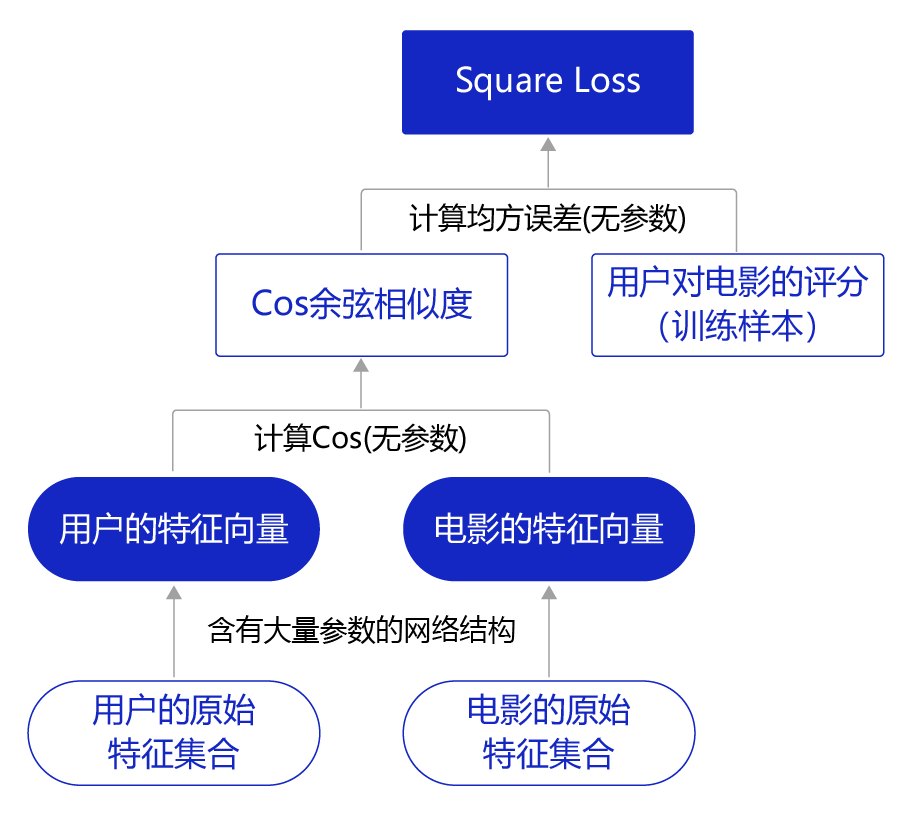
图10:训练模型
-
第一层结构:特征变换,原始特征集合变换为两个特征向量。
-
第二层结构:计算向量相似度。为确保结果与电影评分可比较,两个特征向量的相似度从【0~1】缩放5倍到【0~5】。
-
第三层结构:计算Loss,计算缩放后的相似度与用户对电影的真实评分的“均方误差”。
以在训练样本上的Loss最小化为目标,即可学习出模型的网络参数,这些网络参数本质上就是从原始特征集合到特征向量的计算方法,如灰色箭头所示。根据训练好的网络,我们可以计算任意用户和电影向量的相似度,进一步完成推荐。
从原始特征到特征向量之间的网络如何设计?
基于上面的分析,推荐模型的网络结构初步设想如下。
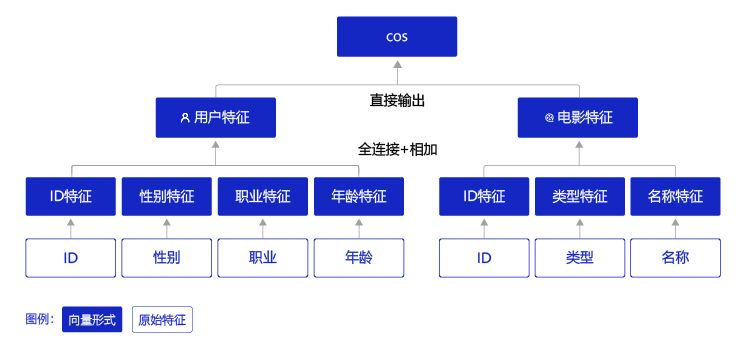
图11:推荐模型的网络结构设想
将每个原始特征转变成Embedding表示,再合并成一个用户特征向量和一个电影特征向量。计算两个特征向量的相似度后,再与训练样本(已知的用户对电影的评分)做损失计算。
但不同类型的原始特征应该如何变换?有哪些网络设计细节需要考虑?我们将在后续几节结合代码实现逐一探讨,包括四个小节:
- 数据处理,将MovieLens的数据处理成神经网络理解的形式。
- 模型设计,设计神经网络模型,将离散的文字数据映射为向量。
- 配置训练参数并完成训练,提取并保存训练后的数据特征。
- 利用保存的特征构建相似度矩阵完成推荐。
