

文档简介:



概述
上一节我们使用“横纵式”教学法中的纵向极简方案快速完成手写数字识别任务的建模,但模型测试效果并未达成预期。我们换个思路,从横向展开,如 图1 所示,逐个环节优化,以达到最优训练效果。本节主要介绍手写数字识别模型中,数据处理的优化方法。
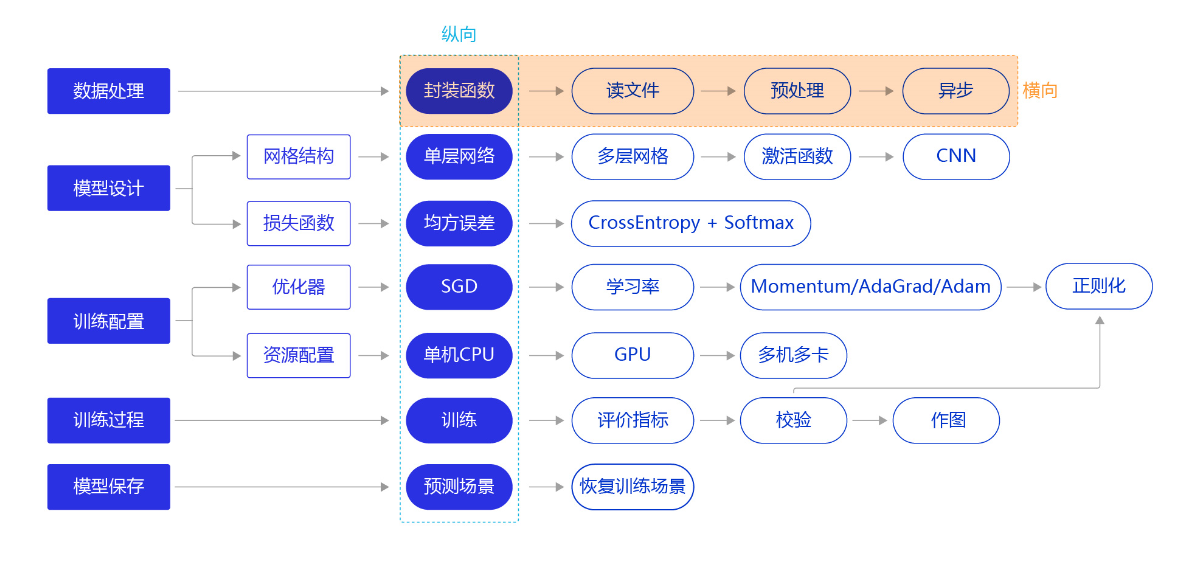
图1:“横纵式”教学法 — 数据处理优化
上一节,我们通过调用飞桨提供的paddle.vision.datasets.MNIST API加载MNIST数据集。但在工业实践中,我们面临的任务和数据环境千差万别,通常需要自己编写适合当前任务的数据处理程序,一般涉及如下五个环节:
- 读入数据
- 划分数据集
- 生成批次数据
- 训练样本集乱序
- 校验数据有效性
前提条件
在数据读取与处理前,首先要加载飞桨平台和数据处理库,代码如下。
#数据处理部分之前的代码,加入部分数据处理的库 import paddle from paddle.nn import Linear
import paddle.nn.functional as F import os import gzip import json import random import numpy as np
读入数据并划分数据集
在实际应用中,保存到本地的数据存储格式多种多样,如MNIST数据集以json格式存储在本地,其数据存储结构如 图2 所示。
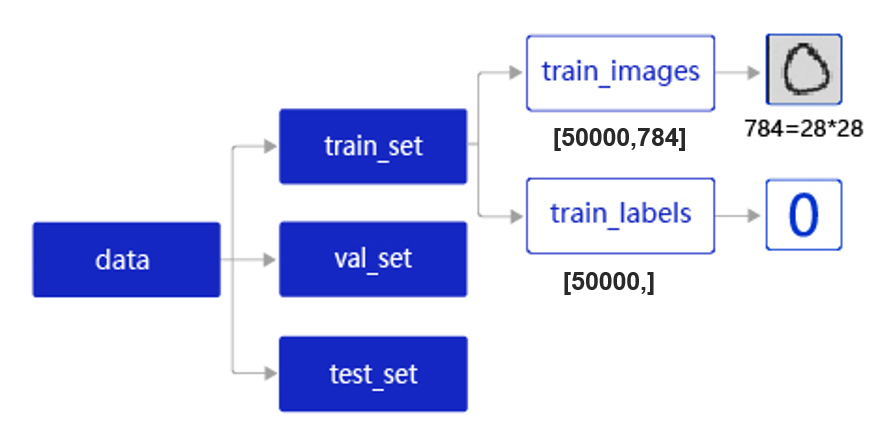
图2:MNIST数据集的存储结构
data包含三个元素的列表:train_set、val_set、 test_set,包括50 000条训练样本、10 000条验证样本、10 000条测试样本。每个样本包含手写数字图片和对应的标签。
- train_set(训练集):用于确定模型参数。
- val_set(验证集):用于调节模型超参数(如多个网络结构、正则化权重的最优选择)。
- test_set(测试集):用于估计应用效果(没有在模型中应用过的数据,更贴近模型在真实场景应用的效果)。
train_set包含两个元素的列表:train_images、train_labels。
- train_images:[50 000, 784]的二维列表,包含50 000张图片。每张图片用一个长度为784的向量表示,内容是28*28尺寸的像素灰度值(黑白图片)。
- train_labels:[50 000, ]的列表,表示这些图片对应的分类标签,即0~9之间的一个数字。
在本地./work/目录下读取文件名称为mnist.json.gz的MNIST数据,并拆分成训练集、验证集和测试集,实现方法如下所示。
# 声明数据集文件位置 datafile = './work/mnist.json.gz' print('loading mnist dataset from
{} ......'.format(datafile)) # 加载json数据文件 data = json.load(gzip.open(datafile))
print('mnist dataset load done') # 读取到的数据区分训练集,验证集,测试集 train_set, val_set,
eval_set = data # 观察训练集数据 imgs, labels = train_set[0], train_set[1]
print("训练数据集数量: ", len(imgs)) # 观察验证集数量 imgs, labels = val_set[0], val_set[1]
print("验证数据集数量: ", len(imgs)) # 观察测试集数量 imgs, labels = val= eval_set[0], eval_set[1]
print("测试数据集数量: ", len(imgs))
loading mnist dataset from ./work/mnist.json.gz ...... mnist dataset load done 训练数据集数量: 50000 验证数据集数量: 10000 测试数据集数量: 10000
扩展阅读:为什么针对固定数据集的模型总在不断精进呢?
通常某组织发布一个新任务的训练集和测试集数据后,全世界的科学家都针对该数据集进行创新研究,随后大量针对该数据集的论文会陆续发表。论文1的A模型声称在测试集的准确率70%,论文2的B模型声称在测试集的准确率提高到72%,论文N的X模型声称在测试集的准确率提高到90% …
然而这些论文中的模型在测试集上准确率提升真实有效么?我们不妨大胆猜测一下。
假设所有论文共产生1000个模型,这些模型使用的是测试数据集来评判模型效果,并最终选出效果最优的模型。这相当于把原始的测试集当作了验证集,使得测试集失去了真实评判模型效果的能力,正如机器学习领域非常流行的一句话:“拷问数据足够久,它终究会招供”。
图3:拷问数据足够久,它总会招供
那么当我们需要将各种论文中模型复用于工业项目时,应该如何选择呢?给读者一个小建议:当几个模型的准确率在测试集上差距不大时,尽量选择网络结构相对简单的模型。往往越精巧设计的模型和方法,越不容易在不同的数据集之间迁移。
训练样本乱序、生成批次数据
- 训练样本乱序: 先将样本按顺序进行编号,建立ID集合index_list。然后将index_list乱序,最后按乱序后的顺序读取数据。
说明:
通过大量实验发现,模型对最后出现的数据印象更加深刻。训练数据导入后,越接近模型训练结束,最后几个批次数据对模型参数的影响越大。为了避免模型记忆影响训练效果,需要进行样本乱序操作。
- 生成批次数据: 先设置合理的batch_size,再将数据转变成符合模型输入要求的np.array格式返回。同时,在返回数据时将Python生成器设置为yield模式,以减少内存占用。
在执行如上两个操作之前,需要先将数据处理代码封装成load_data函数,方便后续调用。load_data有三种模型:train、valid、eval,分为对应返回的数据是训练集、验证集、测试集。
imgs, labels = train_set[0], train_set[1]
print("训练数据集数量: ", len(imgs)) # 获得数据集长度 imgs_length = len(imgs)
# 定义数据集每个数据的序号,根据序号读取数据 index_list = list(range(imgs_length))
# 读入数据时用到的批次大小 BATCHSIZE = 100 # 随机打乱训练数据的索引序号 random.
shuffle(index_list) # 定义数据生成器,返回批次数据 def data_generator(): imgs_list = []
labels_list = [] for i in index_list: # 将数据处理成希望的类型 img = np.array(imgs[i]).astype('float32')
label = np.array(labels[i]).astype('float32')
imgs_list.append(img)
labels_list.append(label) if len(imgs_list) == BATCHSIZE: # 获得一个batchsize的数据,
并返回 yield np.array(imgs_list), np.array(labels_list) # 清空数据读取列表 imgs_list = []
labels_list = [] # 如果剩余数据的数目小于BATCHSIZE, # 则剩余数据一起构成一个
大小为len(imgs_list)的mini-batch if len(imgs_list) > 0: yield np.array(imgs_list),
np.array(labels_list) return data_generator
训练数据集数量: 50000
# 声明数据读取函数,从训练集中读取数据 train_loader = data_generator # 以迭代的形式读取数据 for
batch_id, data in enumerate(train_loader()):
image_data, label_data = data if batch_id == 0: # 打印数据shape和类型 print("打印第一个batch数据的维度:")
print("图像维度: {}, 标签维度: {}".format(image_data.shape, label_data.shape)) break
打印第一个batch数据的维度: 图像维度: (100, 784), 标签维度: (100,)
imgs_length = len(imgs) assert len(imgs) == len(labels), \ "length of train_imgs({})
should be the same as train_labels({})".format(len(imgs), len(label))
# 声明数据读取函数,从训练集中读取数据 train_loader = data_generator
# 以迭代的形式读取数据 for batch_id, data in enumerate(train_loader()):
image_data, label_data = data if batch_id == 0: # 打印数据shape和类型
print("打印第一个batch数据的维度,以及数据的类型:")
print("图像维度: {}, 标签维度: {}, 图像数据类型: {}, 标签数据类型:
{}".format(image_data.shape, label_data.shape, type(image_data), type(label_data))) break
打印第一个batch数据的维度,以及数据的类型: 图像维度: (100, 784), 标签维度: (100,), 图像数据类型:, 标签数据类型:
def load_data(mode='train'): datafile = './work/mnist.json.gz' print('loading mnist dataset
from {} ......'.format(datafile)) # 加载json数据文件 data = json.load(gzip.open(datafile))
print('mnist dataset load done') # 读取到的数据区分训练集,验证集,测试集 train_set, val
_set, eval_set = data if mode=='train': # 获得训练数据集 imgs, labels = train_set[0],
train_set[1] elif mode=='valid': # 获得验证数据集 imgs, labels = val_set[0], val_set[1]
elif mode=='eval': # 获得测试数据集 imgs, labels = eval_set[0], eval_set[1] else: raise
Exception("mode can only be one of ['train', 'valid', 'eval']")
print("训练数据集数量: ", len(imgs)) # 校验数据 imgs_length = len(imgs) assert
len(imgs) == len(labels), \ "length of train_imgs({}) should be the same as train_labels({})
".format(len(imgs), len(labels)) # 获得数据集长度 imgs_length = len(imgs)
# 定义数据集每个数据的序号,根据序号读取数据 index_list = list(range(imgs_length))
# 读入数据时用到的批次大小 BATCHSIZE = 100 # 定义数据生成器 def data_generator():
if mode == 'train': # 训练模式下打乱数据 random.shuffle(index_list)
imgs_list = []
labels_list = [] for i in index_list: # 将数据处理成希望的类型 img = np.array(imgs[i]).astype('float32')
label = np.array(labels[i]).astype('float32')
imgs_list.append(img)
labels_list.append(label) if len(imgs_list) == BATCHSIZE: # 获得一个batchsize的数据,
并返回 yield np.array(imgs_list), np.array(labels_list) # 清空数据读取列表 imgs_list = []
labels_list = [] # 如果剩余数据的数目小于BATCHSIZE, # 则剩余数据一起构成一
个大小为len(imgs_list)的mini-batch if len(imgs_list) > 0: yield np.array(imgs_list),
np.array(labels_list) return data_generator
下面定义一层神经网络,利用定义好的数据处理函数,完成神经网络的训练。
#数据处理部分之后的代码,数据读取的部分调用Load_data函数 # 定义网络结构,
同上一节所使用的网络结构 class MNIST(paddle.nn.Layer): def __init__(self): super(MNIST,
self).__init__() # 定义一层全连接层,输出维度是1 self.fc = paddle.nn.Linear(in_features=784,
out_features=1) def forward(self, inputs): outputs = self.fc(inputs) return outputs #
训练配置,并启动训练过程 def train(model): model = MNIST()
model.train() #调用加载数据的函数 train_loader = load_data('train')
opt = paddle.optimizer.SGD(learning_rate=0.001, parameters=model.parameters())
EPOCH_NUM = 10 for epoch_id in range(EPOCH_NUM): for batch_id, data in enumerate
(train_loader()): #准备数据,变得更加简洁 images, labels = data
images = paddle.to_tensor(images)
labels = paddle.to_tensor(labels) #前向计算的过程 predits = model(images)
#计算损失,取一个批次样本损失的平均值 loss = F.square_error_cost(predits, labels)
avg_loss = paddle.mean(loss) #每训练了200批次的数据,打印下当前Loss的情况
if batch_id % 200 == 0:
print("epoch: {}, batch: {}, loss is: {}".format(epoch_id, batch_id,
avg_loss.numpy())) #后向传播,更新参数的过程 avg_loss.backward()
opt.step()
opt.clear_grad() # 保存模型 paddle.save(model.state_dict(), './mnist.pdparams')
# 创建模型 model = MNIST() # 启动训练过程 train(model)
W0505 16:59:15.496356 102 gpu_context.cc:244] Please NOTE: device: 0, GPU Compute
Capability: 8.0, Driver API Version: 11.2, Runtime API Version: 11.2 W0505 16:59:15.499550 102 gpu_context.cc:272] device: 0, cuDNN Version: 8.2.
loading mnist dataset from ./work/mnist.json.gz ...... mnist dataset load done 训练数据集数量: 50000 epoch: 0, batch: 0, loss is: [38.171707] epoch: 0, batch: 200, loss is: [8.34922] epoch: 0, batch: 400, loss is: [8.892158] epoch: 1, batch: 0, loss is: [8.551595] epoch: 1, batch: 200, loss is: [7.403319] epoch: 1, batch: 400, loss is: [8.533718] epoch: 2, batch: 0, loss is: [8.136135] epoch: 2, batch: 200, loss is: [8.649864] epoch: 2, batch: 400, loss is: [8.989861] epoch: 3, batch: 0, loss is: [9.510458] epoch: 3, batch: 200, loss is: [8.081308] epoch: 3, batch: 400, loss is: [9.124348] epoch: 4, batch: 0, loss is: [8.867871] epoch: 4, batch: 200, loss is: [8.526175] epoch: 4, batch: 400, loss is: [8.750117] epoch: 5, batch: 0, loss is: [7.1789145] epoch: 5, batch: 200, loss is: [8.392652] epoch: 5, batch: 400, loss is: [9.816529] epoch: 6, batch: 0, loss is: [7.6606464] epoch: 6, batch: 200, loss is: [8.146049] epoch: 6, batch: 400, loss is: [9.013026] epoch: 7, batch: 0, loss is: [8.135386] epoch: 7, batch: 200, loss is: [8.254238] epoch: 7, batch: 400, loss is: [8.50532] epoch: 8, batch: 0, loss is: [8.372891] epoch: 8, batch: 200, loss is: [7.9623914] epoch: 8, batch: 400, loss is: [7.814556] epoch: 9, batch: 0, loss is: [8.264876] epoch: 9, batch: 200, loss is: [7.993459] epoch: 9, batch: 400, loss is: [9.785951]
异步数据读取
上面提到的数据读取采用的是同步数据读取方式。对于样本量较大、数据读取较慢的场景,建议采用异步数据读取方式。异步读取数据时,数据读取和模型训练并行执行,从而加快了数据读取速度,牺牲一小部分内存换取数据读取效率的提升,二者关系如 图4 所示。
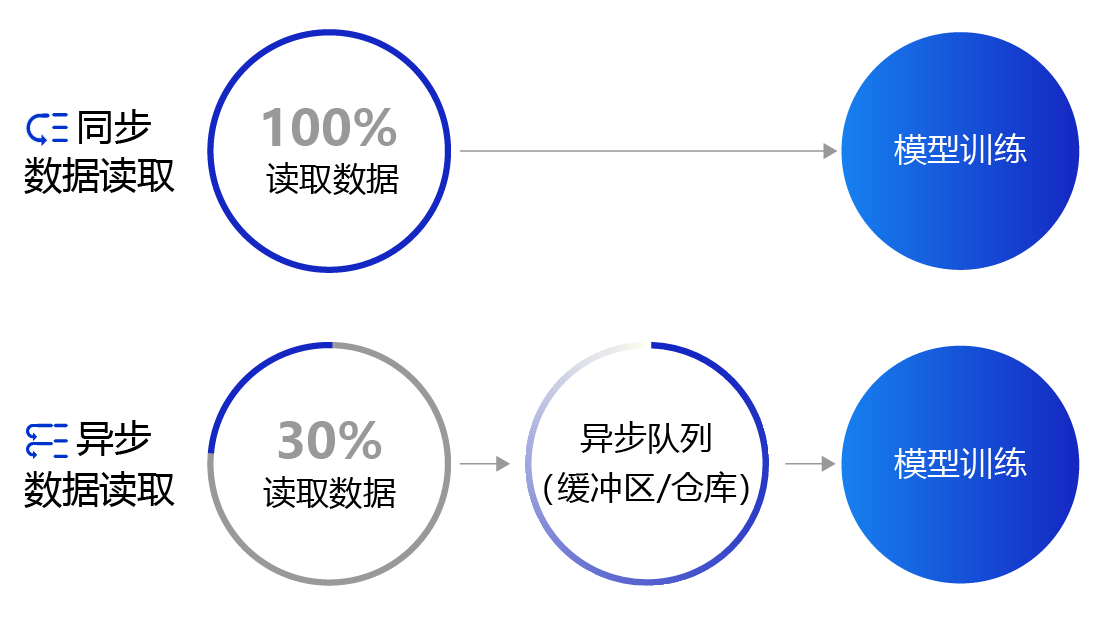
图4:同步数据读取和异步数据读取示意图
- 同步数据读取:数据读取与模型训练串行。当模型需要数据时,才运行数据读取函数获得当前批次的数据。在读取数据期间,模型一直等待数据读取结束才进行训练,数据读取速度相对较慢。
- 异步数据读取:数据读取和模型训练并行。读取到的数据不断的放入缓存区,无需等待模型训练就可以启动下一轮数据读取。当模型训练完一个批次后,不用等待数据读取过程,直接从缓存区获得下一批次数据进行训练,从而加快了数据读取速度。
- 异步队列:数据读取和模型训练交互的仓库,二者均可以从仓库中读取数据,它的存在使得两者的工作节奏可以解耦。
使用飞桨实现异步数据读取非常简单,只需要两个步骤:
- 构建一个继承paddle.io.Dataset类的数据读取器。
- 通过paddle.io.DataLoader创建异步数据读取的迭代器。
首先,我们创建定义一个paddle.io.Dataset类,使用随机函数生成一个数据读取器,代码如下:
import numpy as np from paddle.io import Dataset # 构建一个类,继承paddle.io.Dataset,
创建数据读取器 class RandomDataset(Dataset): def __init__(self, num_samples):
# 样本数量 self.num_samples = num_samples def __getitem__(self, idx): #
随机产生数据和label image = np.random.random([784]).astype('float32')
label = np.random.randint(0, 9, (1, )).astype('float32') return image,
label def __len__(self): # 返回样本总数量 return self.num_samples # 测试数据读取器
dataset = RandomDataset(10) for i in range(len(dataset)):
print(dataset[i])
在定义完paddle.io.Dataset后,使用paddle.io.DataLoader API即可实现异步数据读取,数据会由Python线程预先读取,并异步送入一个队列中。
class paddle.io.DataLoader(dataset, batch_size=100, shuffle=True, num_workers=2)
DataLoader支持单进程和多进程的数据加载方式。当 num_workers=0时,使用单进程方式异步加载数据;当 num_workers=n(n>0)时,主进程将会开启n个子进程异步加载数据。 DataLoader返回一个迭代器,迭代的返回dataset中的数据内容;
dataset是支持 map-style 的数据集(可通过下标索引样本), map-style 的数据集请参考 paddle.io.Dataset API。
使用paddle.io.DataLoader API以batch的方式进行迭代数据,代码如下:
loader = paddle.io.DataLoader(dataset, batch_size=3, shuffle=True,
drop_last=True, num_workers=2) for i, data in enumerate(loader()):
images, labels = data[0], data[1]
print("batch_id: {}, 训练数据shape: {}, 标签数据shape: {}".format(i, images.shape, labels.shape))
batch_id: 0, 训练数据shape: [3, 784], 标签数据shape: [3, 1] batch_id: 1, 训练数据shape: [3, 784], 标签数据shape: [3, 1] batch_id: 2, 训练数据shape: [3, 784], 标签数据shape: [3, 1]
通过上面的学习,我们指导了如何自定义、使用paddle.io.Dataset和paddle.io.DataLoader,下面我们以MNIST数据为例,生成对应的Dataset和DataLoader。
import paddle import json import gzip import numpy as np # 创建一个类MnistDataset,
继承paddle.io.Dataset 这个类 # MnistDataset的作用和上面load_data()函数的作用相同,
均是构建一个迭代器 class MnistDataset(paddle.io.Dataset): def __init__(self, mode):
datafile = './work/mnist.json.gz' data = json.load(gzip.open(datafile))
# 读取到的数据区分训练集,验证集,测试集 train_set, val_set, eval_set = data
if mode=='train': # 获得训练数据集 imgs, labels = train_set[0], train_set[1] elif
mode=='valid': # 获得验证数据集 imgs, labels = val_set[0], val_set[1] elif mode=='eval':
# 获得测试数据集 imgs, labels = eval_set[0], eval_set[1] else: raise Exception("mode can
only be one of ['train', 'valid', 'eval']") # 校验数据 imgs_length = len(imgs) assert
len(imgs) == len(labels), \ "length of train_imgs({}) should be the same as
train_labels({})".format(len(imgs), len(labels))
self.imgs = imgs
self.labels = labels def __getitem__(self, idx):
img = np.array(self.imgs[idx]).astype('float32')
label = np.array(self.labels[idx]).astype('float32') return
img, label def __len__(self): return len(self.imgs)
# 声明数据加载函数,使用MnistDataset数据集 train_dataset = MnistDataset(mode='train')
# 使用paddle.io.DataLoader 定义DataLoader对象用于加载Python生成器产生的数据, # DataLoader
返回的是一个批次数据迭代器,并且是异步的; data_loader = paddle.io.DataLoader(train_dataset,
batch_size=100, shuffle=True) # 迭代的读取数据并打印数据的形状 for i, data in enumerate(data_loader()):
images, labels = data
print(i, images.shape, labels.shape) if i>=2: break
0 [100, 784] [100] 1 [100, 784] [100] 2 [100, 784] [100]
异步数据读取并训练的完整案例代码如下所示。
def train(model): model = MNIST()
model.train()
opt = paddle.optimizer.SGD(learning_rate=0.001, parameters=model.parameters())
EPOCH_NUM = 10 for epoch_id in range(EPOCH_NUM): for batch_id, data in enumerate(data_loader()):
images, labels = data
images = paddle.to_tensor(images)
labels = paddle.to_tensor(labels).astype('float32') #前向计算的过程 predicts = model(images)
#计算损失,取一个批次样本损失的平均值 loss = F.square_error_cost(predicts, labels)
avg_loss = paddle.mean(loss) #每训练了200批次的数据,打印下当前Loss的情况 if batch_id % 200 == 0:
print("epoch: {}, batch: {}, loss is: {}".format(epoch_id, batch_id, avg_loss.numpy()))
#后向传播,更新参数的过程 avg_loss.backward()
opt.step()
opt.clear_grad() #保存模型参数 paddle.save(model.state_dict(), 'mnist')
#创建模型 model = MNIST() #启动训练过程 train(model)
epoch: 0, batch: 0, loss is: [27.301617] epoch: 0, batch: 200, loss is: [9.759112] epoch: 0, batch: 400, loss is: [10.158085] epoch: 1, batch: 0, loss is: [7.505661] epoch: 1, batch: 200, loss is: [6.382886] epoch: 1, batch: 400, loss is: [9.5212] epoch: 2, batch: 0, loss is: [9.112238] epoch: 2, batch: 200, loss is: [7.8596096] epoch: 2, batch: 400, loss is: [8.110541] epoch: 3, batch: 0, loss is: [8.212602] epoch: 3, batch: 200, loss is: [9.671776] epoch: 3, batch: 400, loss is: [8.444334] epoch: 4, batch: 0, loss is: [7.6245728] epoch: 4, batch: 200, loss is: [7.7518682] epoch: 4, batch: 400, loss is: [8.427069] epoch: 5, batch: 0, loss is: [8.385333] epoch: 5, batch: 200, loss is: [8.1700735] epoch: 5, batch: 400, loss is: [9.062199] epoch: 6, batch: 0, loss is: [7.8162937] epoch: 6, batch: 200, loss is: [7.9461827] epoch: 6, batch: 400, loss is: [9.106985] epoch: 7, batch: 0, loss is: [7.9150925] epoch: 7, batch: 200, loss is: [7.319148] epoch: 7, batch: 400, loss is: [7.0969405] epoch: 8, batch: 0, loss is: [7.7315764]
从异步数据读取的训练结果来看,损失函数下降与同步数据读取训练结果一致。注意,异步读取数据只在数据量规模巨大时会带来显著的性能提升,对于多数场景采用同步数据读取的方式已经足够。
扩展阅读:数据增强/增广
任何数学技巧都不能弥补信息的缺失 -Cornelius Lanczos(匈牙利数学家、物理学家)
本节介绍的各种数据处理方法仅限于为了实现深度学习任务,所必要的数据处理流程。但在实际任务中,原始数据集未必完全含有解决任务所需要的充足信息。这时候,通过分析任务场景,有针对性的做一些数据增强/增广的策略,往往可以显著的提高模型效果。
数据增强是一种挖掘数据集潜力的方法,可以让数据集蕴含更多让模型有效学习的信息。这些方法是领域和任务特定的,通过分析任务场景的复杂性和当前数据集的短板,对现有数据做有针对性的修改,以提供更加多样性的、匹配任务场景复杂性的新数据。下面以计算机视觉相关问题的数据增强为例,给读者一些具体增强方法和背后的思考。
下图所示为一些基础的图像增强方法,如果我们发现数据集中的猫均是标准姿势,而真实场景中的猫时常有倾斜身姿的情况,那么在原始图片数据的基础上采用旋转的方法造一批数据加入到数据集会有助于提升模型效果。类似的,如果数据集中均是高清图片,而真实场景中经常有拍照模糊或曝光异常的情况,则采用降采样和调整饱和度的方式造一批数据,有助于提升模型的效果。  基础的图像增强方法
基础的图像增强方法
下图展示了一些高阶的图像增强方法,裁剪和拼接分别适合于“数据集中物体完整,但实际场景中物体存在遮挡”,以及“数据集中物体背景单一,而实际场景中物体的背景多变”的两种情况。  高阶的数据增强方法
高阶的数据增强方法
下图展示了专门针对文本识别的数据增强方法TIA(Text Image augmentation),对应到“数据集中字体多是平面,而真实场景中的字体往往会在曲面上扭曲的情况,比如拿着相机对一张凸凹不平摆放的纸面拍摄的文字就会存在这种情况”。 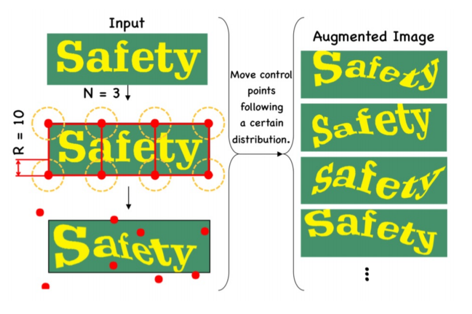 TIA(Text Image augmentation):针对文本识别数据增强方法
TIA(Text Image augmentation):针对文本识别数据增强方法
下图展示了一种新颖的数据增强技巧,用于很多现实中的文字检测,要面临复杂多样的背景,比如店铺牌匾上的文字,周围的背景可能是非常多样的。将部分文本区域剪辑出来,随机摆放到图片的各种位置来生成新的训练数据。这样的数据会大大提高模型在复杂背景中,检测到文字内容的能力。  CopyPaste:一种新颖的数据增强技巧
CopyPaste:一种新颖的数据增强技巧
由上述案例可见,数据增强/增广的方法是要根据实际领域和任务来进行设计的,在本书后续更深度的章节我们会展示如何基于飞桨来实现各种数据增强方法。在当前,读者仅需要了解,在深度学习任务的数据处理流程中,经常要采用这样的技巧即可。手写数字识别的任务比较简单,数据集也相对规整,采用这些方法的必要性并不高。
