




批量计算(BatchCompute)是一种适用于大规模并行批处理作业的分布式云服务。BatchCompute可支持海量作业并发规模,系统自动完成资源管理,作业调度和数据加载,并按实际使用量计费。BatchCompute广泛应用于电影动画渲染、生物数据分析、多媒体转码、金融保险分析、科学计算等领域。
产品优势
大规模并发
支持10万核级别以上并发,极大加速计算过程
简单易用
一键提交作业,自动完成资源管理、作业调度
分布式缓存加速I/O
通过独有分布式缓存技术加速共享数据访问,大幅提升I/O效率
丰富的行业解决方案
提供面向影视动画渲染、基因数据分析等行业解决方案
支持按作业需要自动创建释放集群,简化资源管理,节省计算成本。在预留集群模式下,支持作业按照优先级调度,灵活满足业务需求。支持万级别并发实例的平稳运行,为关键业务提供有力保障。
基于有向无环图轻松构建工作流
可以通过有向无环图(DAG)的方式指定任务间的依赖关系,支持复杂工作流的轻松构建。
分布式缓存加速数据访问
通过分布式缓存大幅加速共享数据的并发读取,大规模电影渲染场景效率提升5到10倍。支持OSS和NAS存储。
通过文件系统接口访问OSS
支持把OSS路径挂载到虚拟机的本地文件系统,程序可以通过文件系统接口访问对象存储数据,无缝兼容传统软件上云。
使用竞价实例降低成本
根据指定竞价策略,调用竞价实例进行运算,大幅降低计算成本。
计算环境完全定制
支持通过Docker或者自定义镜像的方式部署计算环境,支持Windows和Linux操作系统。
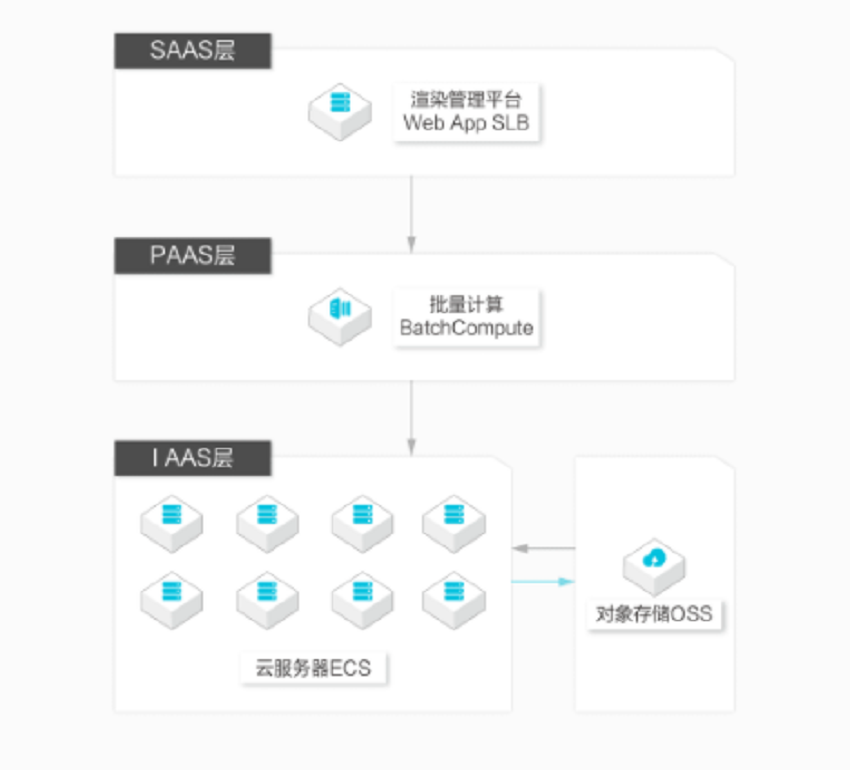
影视渲染
大幅提升渲染效率
批量计算的高效集群管理可以帮助您轻松调度十万核以上的计算资源进行渲染,并且通过独有分布式缓存技术大幅提升共享场景文件的加载性能。同时提供简单易用的渲染管理系统,无需编程实现云上渲染。
能够解决
分布式缓存
无论使用OSS还是NAS,通过简单的配置指定数据源就可以启动分布式缓存功能。缓存加速能力随着集群规模线性扩展,解决大规模渲染场景下素材加载慢的痛点。
灵活易用
用户可以通过集群模式搭建混合云渲染环境,也可以通过作业模式实现自动的资源管理和作业调度。批量计算还提供了方便易用的命令行工具和渲染管理系统,大大减少云渲染系统搭建的投入。
节省成本
用户只需要支付实际消耗的计算和存储费用,批量计算提供的资源管理、作业调度和分布式缓存功能不收取额外费用。大幅减少传统渲染调度软件的license成本。
基因数据分析
轻松实现大批量样本分析
支持基于有向无环图轻松构建复杂工作流,结合批量计算独有的分布式缓存技术和OSS挂载功能,无需特别编程就可以实现稳定高效的大规模样本分析。
能够解决
工作流构建
通过有向无环图的方式指定任务间的依赖关系实现工作流构建。批量计算根据指定的依赖关系保障任务的执行顺序。并且支持通过数据切分的方式实现相同逻辑的并发处理。
支持多种数据源
批量计算任务可以支持OSS和NAS的数据处理。独有OSS挂载功能可以支持程序通过文件接口访问对象存储数据,简化流程迁移上云成本。
简单易用
提供易用强大的命令行工具,用户可以通过编辑配置文件实现工作流构建,并通过简单的命令提交管理作业。无需特殊编程实现流程上云。

