




数据集成(DataInLong)源于腾讯开源并孵化成功的 ASF 顶级项目 Apache InLong(应龙),依托 InLong 百万亿级别的数据接入和处理能力支持数据采集、汇聚、存储、分拣数据处理全流程,在跨云跨网环境下提供可靠、安全、敏捷的全场景异构数据源集成能力。
覆盖离线、实时的全场景同步,支持数据接入(E)、清洗与打宽(T)、数据加载(L)全流程。用户能够以业务特性为导向定义数据来源及去向,关联配置数据字段及类型映射关系,稳定保障不同数据类型结构转换一致性和可用性。
多源异构数据融合
支持30+异构数据源类型,覆盖关系型数据库、大数据存储、非结构化数据、消息队列等常见数据源。异构数据源之间,支持读写任意搭配。
全面运维及监控
支持从集成任务、数据链路、同步节点等维度对同步过程中任务状态、数据变化、资源使用及各类异常情况进行全方面监控,提供丰富复杂的调度策略,精细化的流量、速率、脏数据管理,以及细粒度的权限安全控制等,覆盖电话、邮件、短信、企业微信、微信和http等多种告警能力。
轻量可视
基于 DAG 画布模式,通过拖拉拽即可完成同步节点及技术属性开发配置。同时,结合图表从任务、链路、节点多粒度可视化地展示同步中的数据流量、同步速率、资源使用率等核心指标和里程碑事件。
稳定可靠
采用全托管模式的标准数据集成资源组,支持资源一键配置、可视管理、灵活变配等操作,提供集成任务独享、资源及数据隔离能力,能够保障高峰期任务运行稳定、数据产出及时。
开源开放
技术上,DataInLong 与 Apache 开源社区项目 InLong 同源共生,共同持续推进技术演进和服务稳定。能力上, DataInLong 面向客户及产品开放集成能力,支持灵活与各类基础技术能力、产品、平台系统进行数据对接。
应用场景
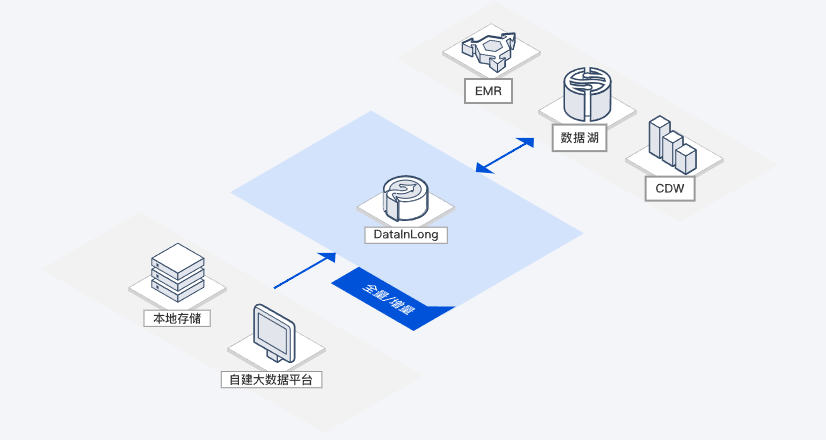
数据入仓入湖/交互分析
基于大数据云服务的弹性和按需能力,通过快速连接云下自建/云上数据源进行采集同步、清洗转换、开发分析、治理及建模,帮助用户轻松快速完成数据入仓入湖和业务数据分析,有效实现数据价值最大化。
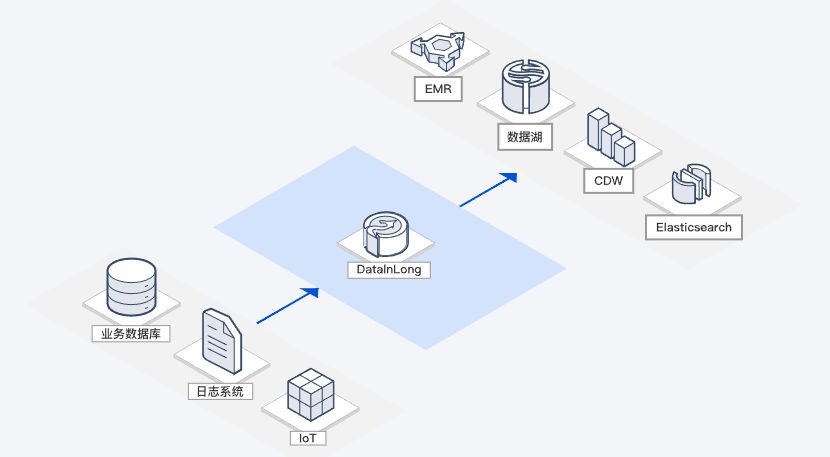
数据工程与科学平台构建
数据集成(DataInLong)提供了开放的技术能力,可与统一调度、元数据管理等技术/产品服务深度融合,为企业数据平台提供可靠技术底座和核心能力支撑,帮助企业搭建先进灵活的平台架构以更好应对快速变化、日益增长的业务数据需求。
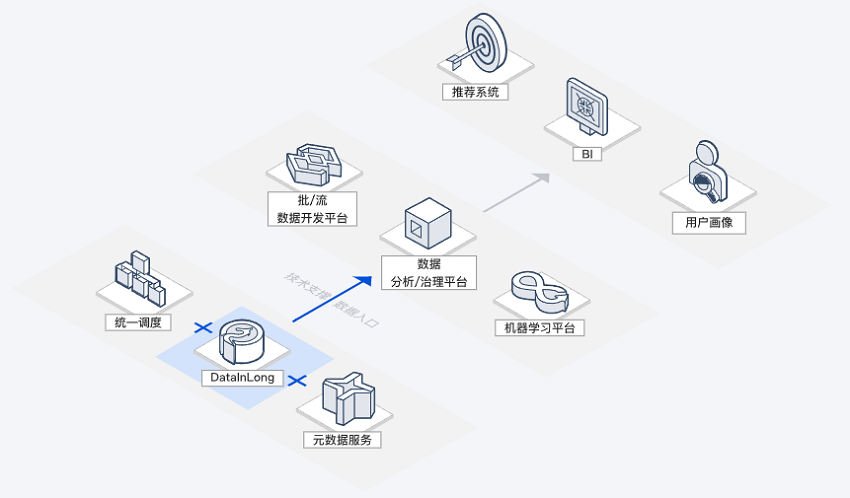
大数据迁移上云
快速迁移云下数据至云上存储,解决业务数据上云中遇到的技术、成本、人力等问题。上云迁移过程支持全量、增量方式,具备数据源类型丰富、简单易用、安全可靠、轻量灵活等优势。
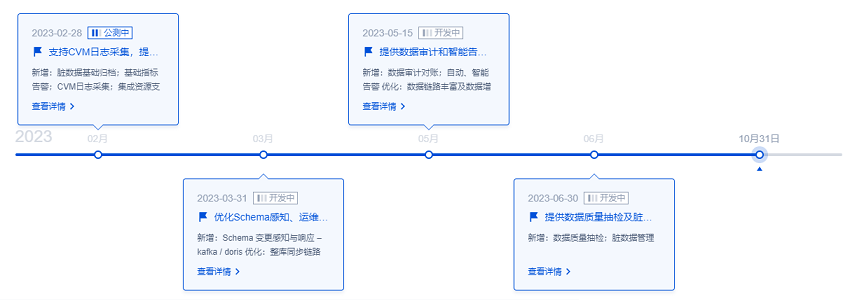
产品路线图
帮助与文档
帮助您快速了解数据集成(DataInLong)。
购买指南
帮助您了解产品计费及购买方式。
词汇表
本文将为您解释产品中涉及到的关键词。
常见问题
帮助您快速了解使用数据集成中涉及的常见问题。
常见问题
数据集成支持哪些数据源?
数据集成(DataInLong)支持多种云上及自建数据源,如:
关系型数据库:Mysql、PostgreSQL、Oracle、SQL Server、IBM DB2、达梦 DM、SAP HANA 等;
大数据存储:Hive、HDFS、HBase、Kudu、Clickhouse、DLC、Impala、Gbase、Tbase等;
半结构化:FTP、SFTP、COS;
NoSQL:Redis、Elasticsearch;
消息队列:Kafka
等。
数据集成支持哪些同步场景?
数据集成(DataInLong)核心支持离线和实时据同步场景。离线场景支持周期性数据摄取;实时场景基于数据库日志/消息队列监控数据变更,实时拉取刷新最新数据。
支持哪些数据同步方向?
数据集成采用星型结构数据模型,对支持的数据源类型可灵活任意搭配来源和去向。
