




腾讯云向量数据库(Tencent Cloud VectorDB)是一款全托管的自研企业级分布式数据库服务,专用于存储、检索、分析多维向量数据。该数据库支持多种索引类型和相似度计算方法,单索引支持 10 亿级向量规模,可支持百万级 QPS 及毫秒级查询延迟。腾讯云向量数据库不仅能为大模型提供外部知识库,提高大模型回答的准确性,还可广泛应用于推荐系统、自然语言处理等 AI 领域。
高性能
向量数据库 Tencent Cloud VectorDB 单索引支持 10 亿级向量数据规模,可支持百万级 QPS 及毫秒级查询延迟。
高可用
向量数据库 Tencent Cloud VectorDB 提供多副本高可用特性,提高容灾能力,确保数据库在面临节点故障和负载变化等挑战时仍能正常运行。
大规模
向量数据库架构支持水平扩展,单实例可支持百亿级 QPS,轻松满足 AI 场景下的向量存储与检索需求。
低成本
只需按照控制台的指引简单操作,即可快速创建向量数据库实例,全流程平台托管,无需进行任何安装、部署、运维操作,减少机器成本、运维成本、人力成本开销。
简单易用
支持丰富的向量检索能力,用户通过 API 即可快速操作数据库,开发效率高。同时控制台提供了完善的数据管理和监控能力,操作简单便捷。
稳定可靠
向量数据库 Tencent Cloud VectorDB 源自腾讯集团自研的向量检索引擎 OLAMA,近 40 个业务线上稳定运行,日均处理的搜索请求高达千亿次,服务连续性、稳定性有保障。
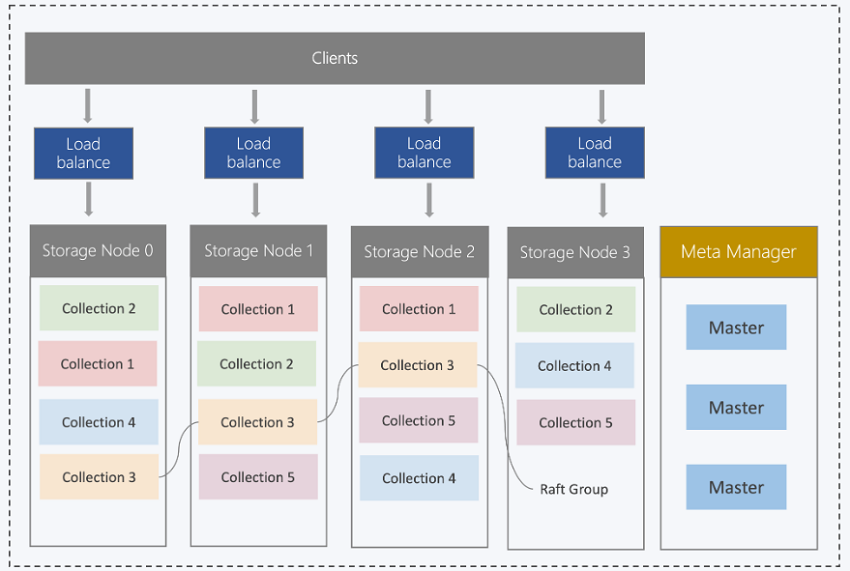
产品架构
腾讯云向量数据库 Tencent Cloud VectorDB 基于腾讯集团每日处理千亿次检索的向量引擎 OLAMA,底层采用 Raft 分布式存储,通过 Master 节点进行集群管理和调度,实现系统的高效运行。同时,腾讯云向量数据库支持设置多分片和多副本,进一步提升了负载均衡能力,使得向量数据库能够在处理海量向量数据的同时,实现高性能、高可扩展性和高容灾能力。
应用场景
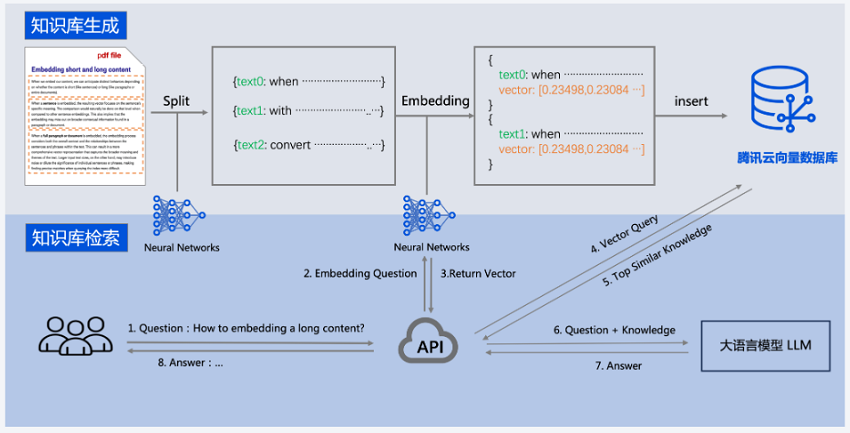
大模型知识库
腾讯云向量数据库可以和大语言模型 LLM 配合使用。企业的私域数据在经过文本分割、向量化后,可以存储在腾讯云向量数据库中,构建起企业专属的外部知识库,从而在后续的检索任务中,为大模型提供提示信息,辅助大模型生成更加准确的答案。
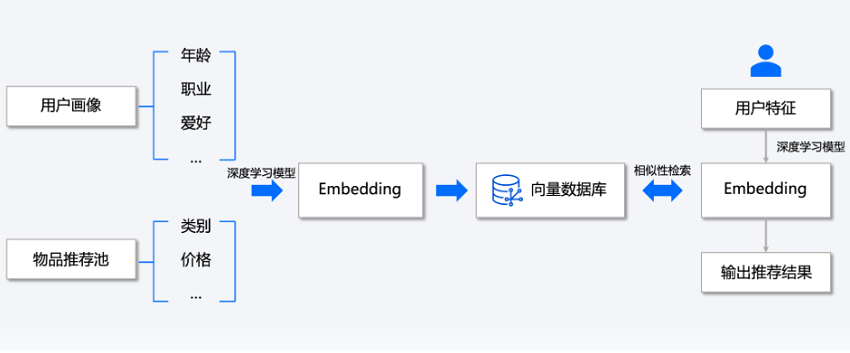
推荐系统
推荐系统的目标是根据用户的历史行为和偏好,向用户推荐可能感兴趣的物品。在这种场景下,将用户行为特征向量化存储在向量数据库。当发起推荐请求时,系统会基于用户特征进行相似度计算,然后返回与用户可能感兴趣的物品作为推荐结果。
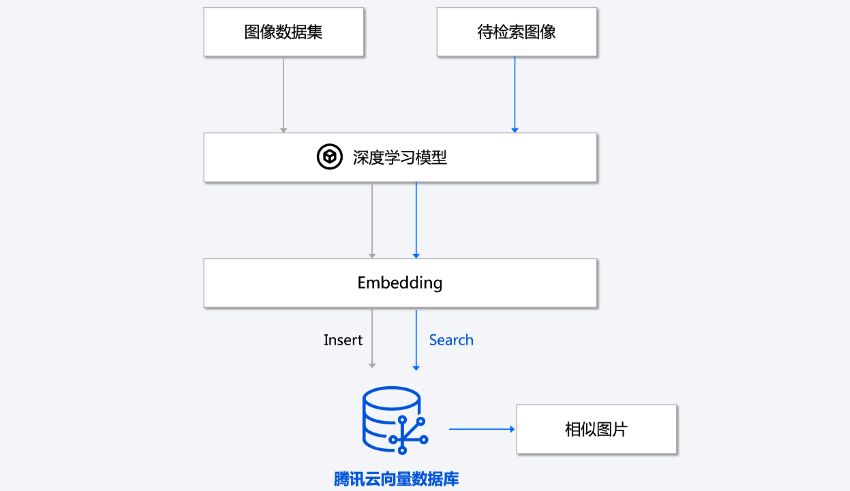
文本/图像检索
文本/图像检索任务是指在大规模文本/图像数据库中搜索出与指定图像最相似的结果,在检索时使用到的文本/图像特征可以存储在向量数据库中,通过高性能的索引存储实现高效的相似度计算,进而返回和检索内容相匹配的文本/图像结果。
帮助与文档
帮助您快速了解腾讯云向量数据库 Tencent Cloud VectorDB 的产品定位、架构、优势以及具体功能。
产品规格
提供不同类型、不同规格节点的向量规模参考,用户可根据业务量评估选型方案。
快速入门
帮助您快速创建、连接、使用腾讯云向量数据库。
操作指南
本文将为您介绍腾讯云向量数据库 Tencent Cloud VectorDB 的基本操作及使用限制等内容。
数据库设计
介绍腾讯云向量数据库的产品架构、逻辑结构、鉴权方式等数据库设计信息。
地域和可用区
查看腾讯云在境内外的地域和可用区信息。
