




在已开通了专属云计算与存储的环境下,还支持开通专属云中的分布式消息Kafka服务,提供高可用、高吞吐的消息中间件服务,适用于第三方解耦、构建实时数据管道、流量削峰去谷等场景,具体大规模、高可靠、高并发访问及完全托管的特点,是分布式应用上云必不可少的重要组件。
兼容开源社区Kafka,业务代码无需改造,即可快速上云
高可靠丨全托管
不再需要客户部署、运维,只需专注于业务本身,提供可靠安全的托管Kafka队列服务
安全丨安全防护
业务操作可追溯,支持SASL_SSL机制对身份认证和数据通道加密传输,确保数据传输过程中不被窃取和篡改
稳定丨高性能
高吞吐量,低时延,消息队列性能高
队列高并发
队列并发最高可超过10万TPS(每秒处理的消息数),扩展队列数可获得更高并发能力
低时延
消息投递时间可至毫秒级,保证消息及时性
海量堆积
支持亿级消息堆积,在海量堆积下不影响队列性能
日常监控
提供Topic、消费组、应用用户的管理;Broker、Topic多维度指标监控
安全防护
提供创建实例时开启SASL访问,开启后数据加密传输,安全性更高
多路转发
适用场景
对于不同业务维度,需要不同计算方式,比如对于对账系统,可能需要实时的流处理方式;对于统计分析而言,使用批计算方式。Kafka能够实现多路转发,上游生产一份数据,多个下游节点都能够获取这份数据并做出相应的处理,Kafka可完成数据多路转发功能
产品优势
一对多消费模型
“发布/订阅”模型,支持同份数据集能同时被消费多次
同时支持实时和批处理
支持本地数据持久化和 Page Cache,在无性能损耗的情况下能同时传送消息到实时和批处理的消费者
推荐方案
专属云(计算独享型)+专属云Kafka
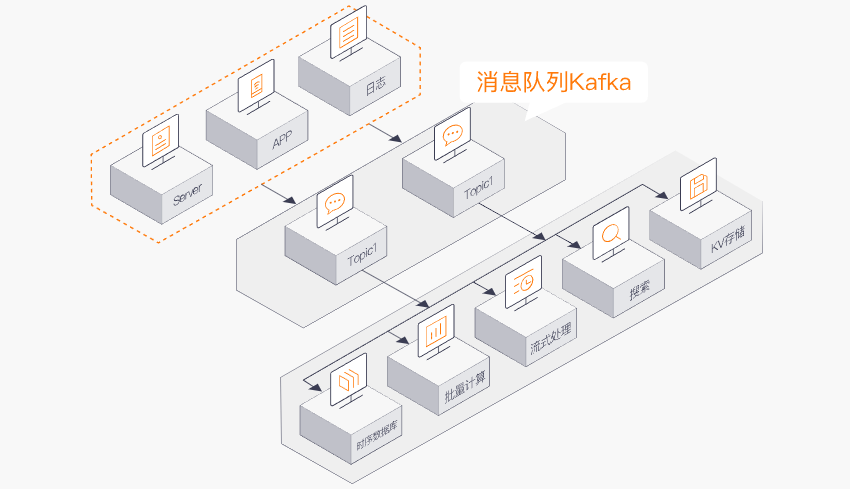
流计算处理
适用场景
Kafka能够做到流计算处理,如股市走向分析、气象数据测控、网站用户行为分析等,这些领域中数据产生快、实时性强、数据量大,很难统一采集并入库存储后再做处理。而Kafka Stream以及Storm/Samza/Spark等流计算引擎,可根据业务需求对数据进行计算分析,最终把结果保存或者分发给需组件
产品优势
流动的数据构建
流动的数据构建应用系统和分析系统的桥梁,并将它们之间的关联解耦
支持流计算引擎
可对接开源 Storm/Samza/Spark 流计算引擎
推荐方案
专属云(计算独享型)+专属云(存储独享型)+专属云Kafka
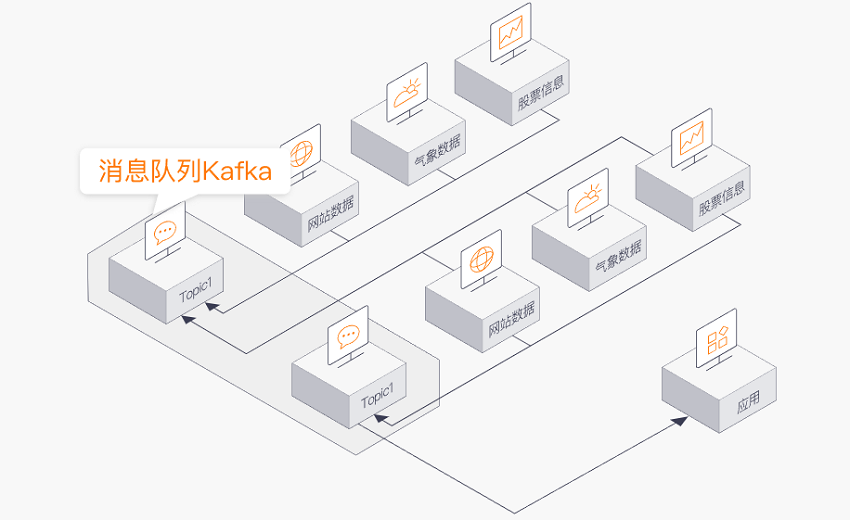
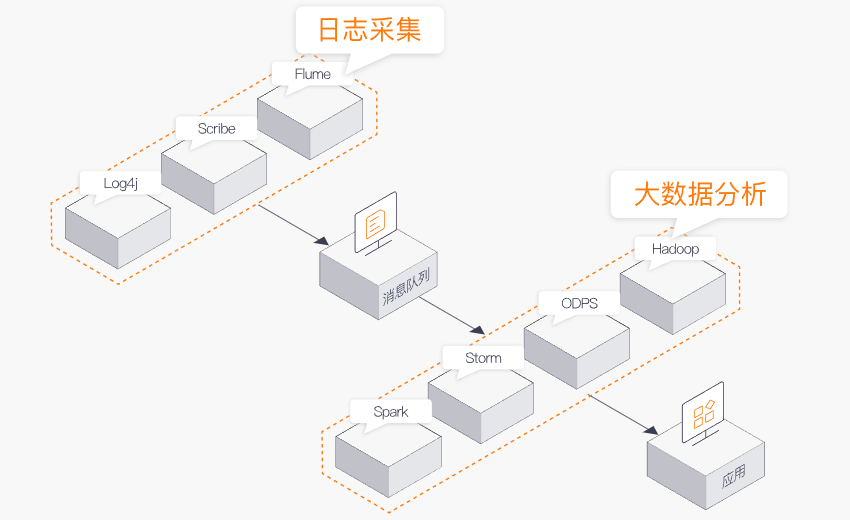
日志收集
Kafka本身的性能是高效,其特性决定它非常适合作为"日志收集中心",当日志数据发送到Kafka集群,对于业务而言是完全无侵入的。同时其在下游能直接对接Hadoop/ODPS等离线仓库存储和Strom/Spark等实现实时在线分析。只需用户去关注整个流程里面的业务逻辑,而无需做更多的开发就能够实现统计、分析以及报表
产品优势
应用与分析解耦
构建应用系统和分析系统的桥梁,并将它们之间的关联解耦
支持在线/离线分析系统
支持实时在线分析系统和类似于 Hadoop 的离线分析系统推荐方案
专属云(计算独享型)+专属云(存储独享型)+专属云Kafka
专属云(计算独享型)
在专属云内,用户独享专用的服务器/集群,可选择独享存储/网络资源,并可在管理控制台统一管理,就像自建私有云一样灵活使用专属云资源
专属云(存储独享型)
为您提供独享的物理存储资源,通过数据冗余和缓存加速等多项技术,提供高可用性和持久性,以及稳定的低时延性能;可灵活对接专属云(计算独享型)等多种不同类型的计算服务
