




多数据源支持
可对接多种数据源,允许存储任意规模的结构化、半结构化、非结构化数据,同时可以按原样存储数据。
计算弹性
通过计算与存储分离,实现计算资源的弹性伸缩,满足客户对计算资源的灵活调度。
成本最优
为集中式存储池,可快速扩展或缩减存储资源,实现存储数据冷热分层,降低大数据分析与机器学习存储成本。
服务集成
无缝支持腾讯云各类计算分析、机器学习产品,包括弹性 MapReduce、 流计算 Oceanus 、腾讯云 TI 平台机器学习。
业务架构
对象存储 COS 可存储任意规模的结构化、半结构化、非结构化数据,其提供12个9的数据持久性,实现计算与存储分离,发挥计算弹性伸缩能力,同时对存储数据冷热分层,是构建数据湖的首选存储服务。借助 COS 构建的数据湖,搭配数据湖加速器 GooseFS、元数据加速器、AZ 加速器等加速服务,可以高效、低成本地对接各类计算分析和机器学习平台,从而打破数据孤岛,洞察业务价值,指导客户做出更好的决策。
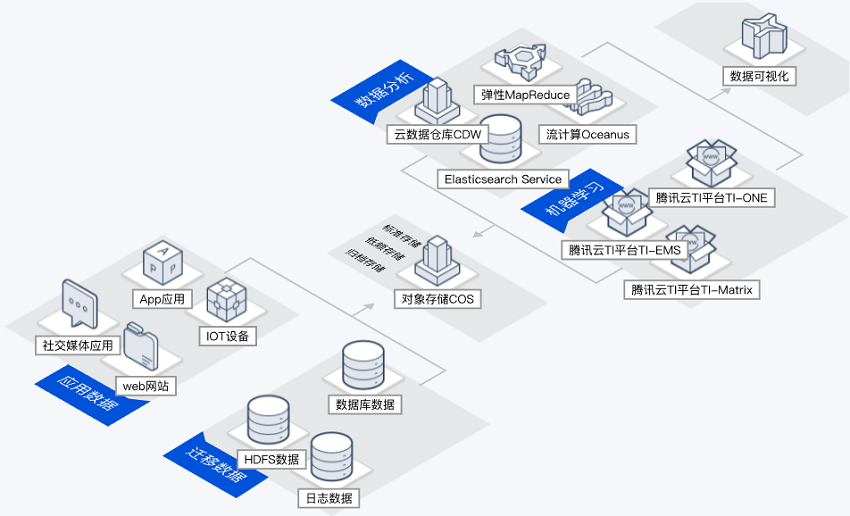
开源生态数据湖
客户基于开源 Hadoop 生态构建大数据处理与分析,会面临计算资源与存储资源扩容速度不匹配、存储系统需对接多数据源的问题。
主要能力
计算存储分离:通过计算与存储分离,实现计算资源弹性伸缩,满足客户对计算资源的灵活调度。
多数据源支持:可对接多种数据源,允许存储任意规模的结构化、半结构化、非结构化数据。
高性能业务架构:通过数据湖加速器 GooseFS、元数据加速器、AZ 加速器等多级加速服务,提升计算业务访问性能。
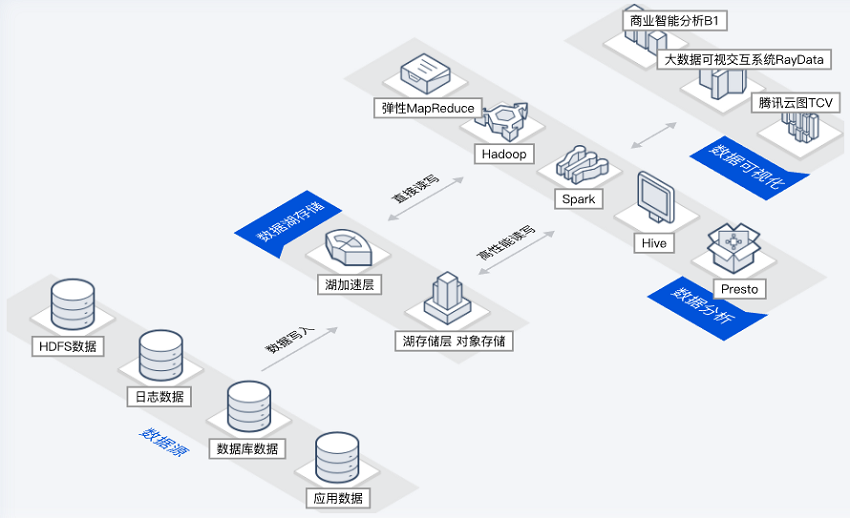
交互式查询数据湖
场景描述
客户在 COS 中存储了多种数据源数据,包括实时计算数据,需要对其中的数据进行 OLAP 分析并进行数据可视化展示。
主要能力
多数据源支持:可对接多种数据源,允许存储任意规模的结构化、半结构化、非结构化数据。
性能加速:通过数据湖加速器 GooseFS、元数据加速器、AZ 加速器等多级加速服务,实现超越本地 HDFS 的性能。
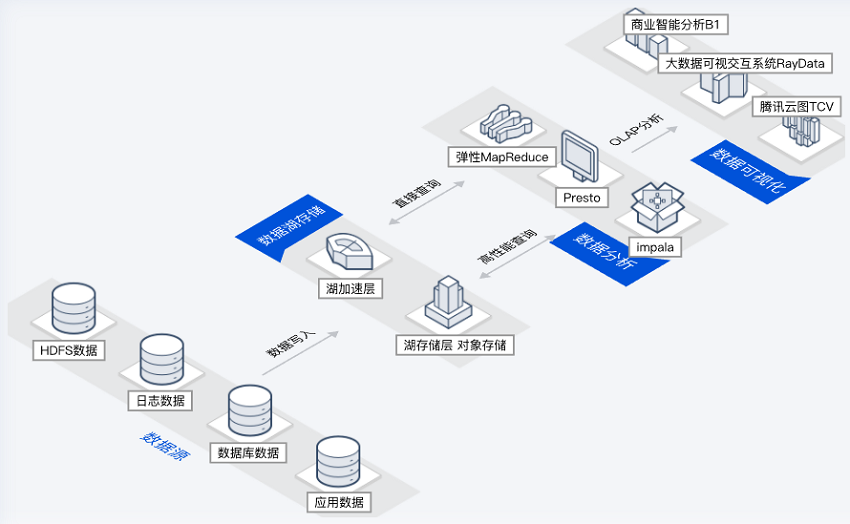
混合分层模式数据湖
场景描述
在海量大数据分析中,随着时间的推移,分析数据将不断累积,同时数据访问频率逐渐降低,会面临存储数据更低成本的问题。
主要能力
冷热分层:对存储数据冷热分层,降低大数据分析资源成本。
多数据源支持:可对接多种数据源,允许存储任意规模的结构化、半结构化、非结构化数据。
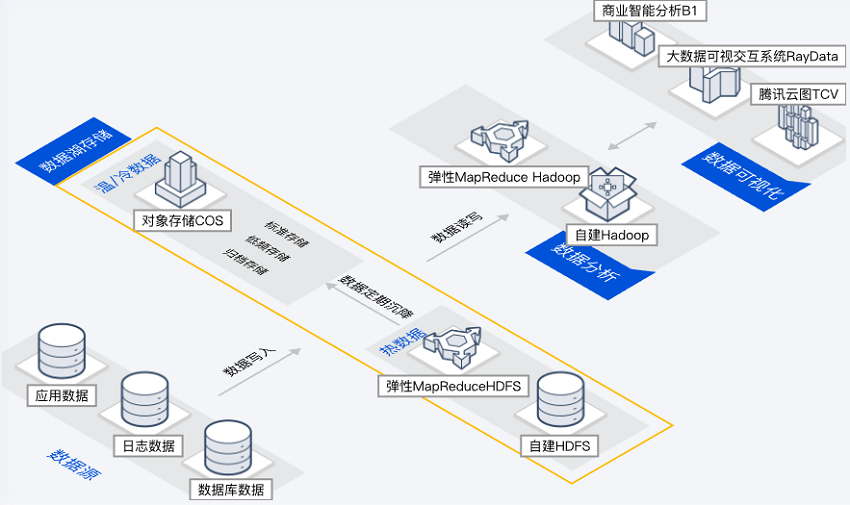
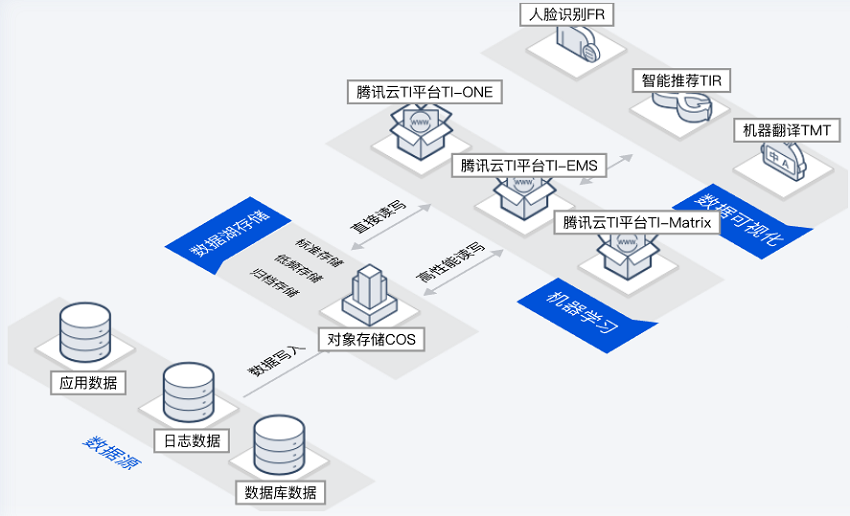
机器学习数据湖
场景描述
在经典机器学习场景中,训练数据量大,同时要求很大的内网带宽。
主要能力
超大带宽:可以提供超大的内网带宽,满足机器学习场景大带宽需求。
多数据源支持:可对接多种数据源,允许存储任意规模的结构化、半结构化、非结构化数据。
性能加速:通过数据湖加速器GooseFS、元数据加速器、AZ 加速器等多级加速服务,实现超越本地 HDFS 的性能。
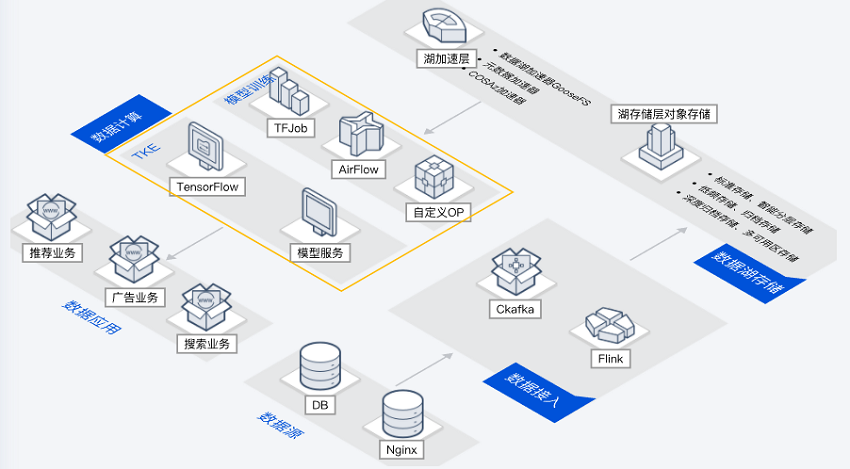
云原生数据湖
场景描述
通过容器服务,结合 Flink、TensorFlow 等开源应用,搭建云原生数据 ETL 集群和分析集群,实现计算资源的弹性化;通过数据湖加速器 GooseFS、元数据加速器、AZ 加速器等多级加速服务,提升计算业务访问性能;通过对象存储服务作为数据湖存储底座,实现海量异构数据的低成本存储。
主要能力
计算存储分离:通过计算与存储分离,实现计算资源弹性伸缩,满足客户对计算资源的灵活调度。
高性能业务架构:通过数据湖加速器 GooseFS、元数据加速器、AZ 加速器等多级加速服务,提升计算业务访问性能。
丰富生态支持:可存储 Parquet、ORC 多种格式数据源,支持 Spark、Presto、Flink 等多种大数据插件。
相关云产品和功能
提供稳定持久、安全可靠、成本最优的云端存储服务,可根据应用程序类型提供各语言 SDK,实现无缝接入。
云 HDFS
提供标准HDFS访问协议和分层命名空间的高性能分布式文件系统。
容器服务
稳定、安全、高效、灵活扩展、简单易用的Kubermetes容器管理平台。
数据湖加速器 GooseFS
提供高性能、高可用、稳定可靠的分布式文件缓存服务,支持AI/大数据等数据密集型业务。
弹性 MapReduce
云端托管的弹性开源泛Hadoop服务,支持Spark、Hbase、Presto、Flink、Druid等大数据框架。
腾讯云 TI 平台
一站式机器学习生态服务平台,涵盖了数据预处理、模型训练、评估、预测全部流程。