模型字段
字段集合可以新增字段和关系。字段和数据库的表的字段类似,具备属性;关系是表与表之间的关联,和 E-R 图中表之间的关系类似。
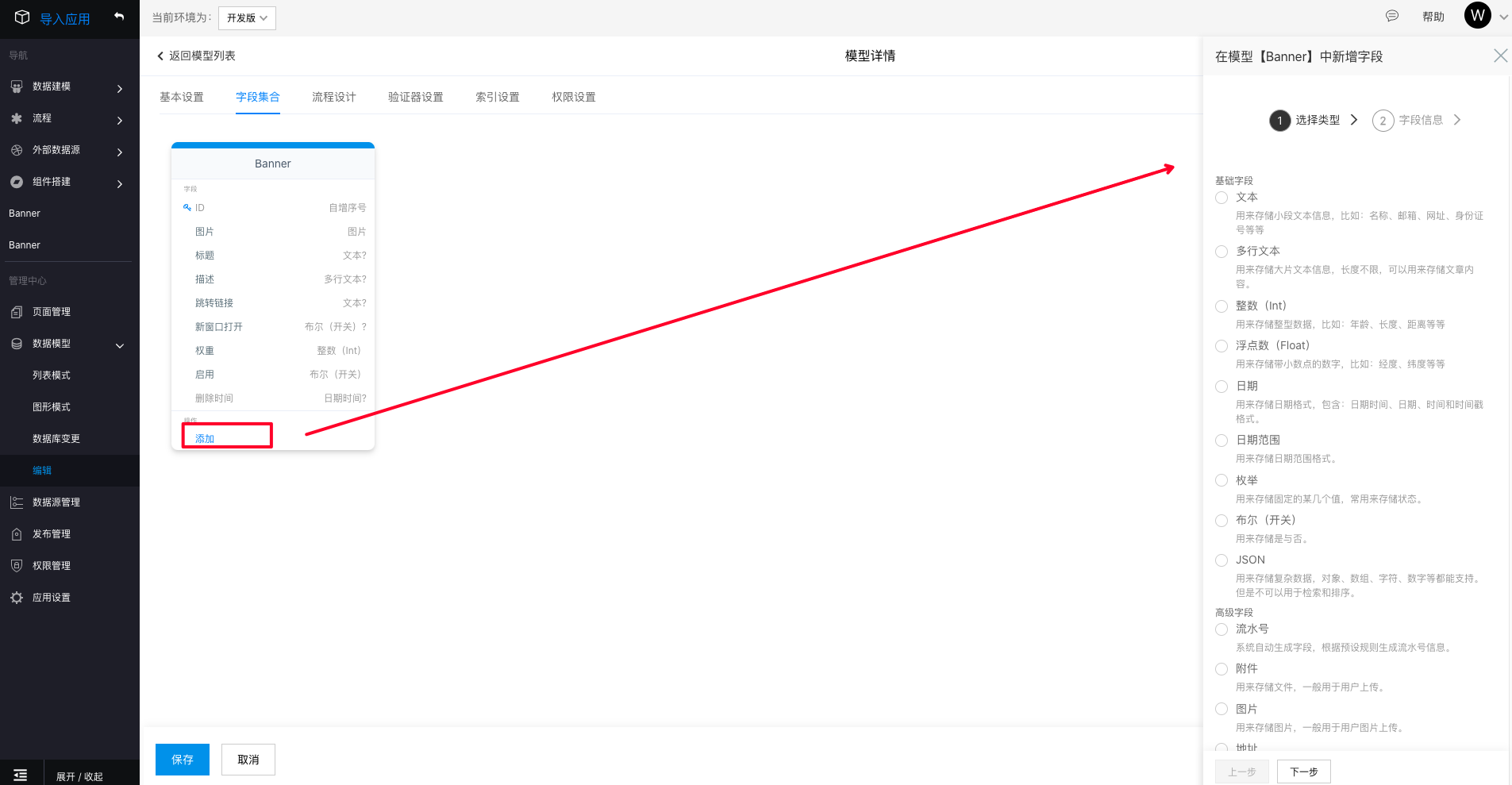
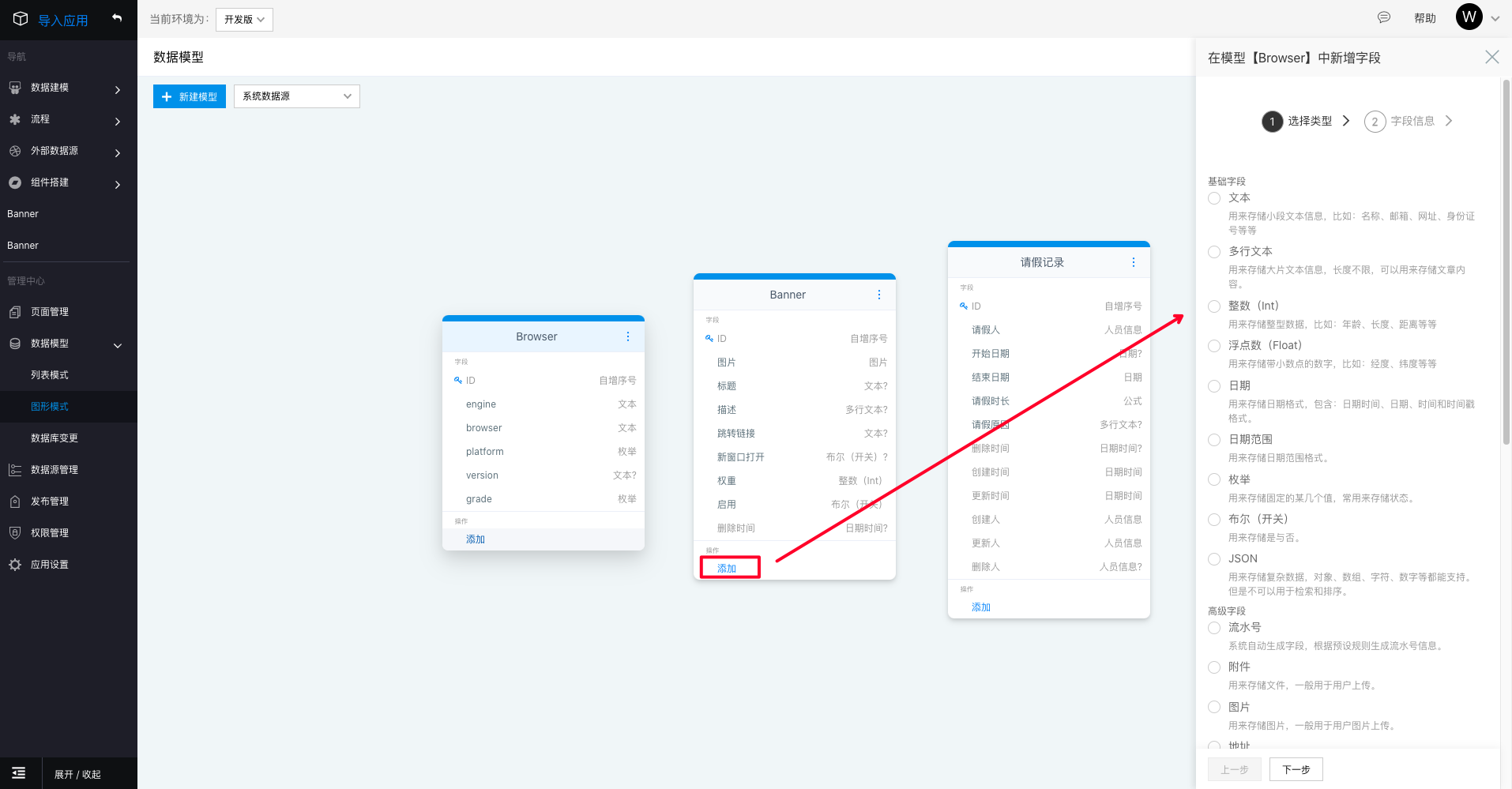
添加字段
模型字段共分为两大类,基础字段类型和高级字段类型。


- 基础字段:文本、多行文本、整数、浮点数、日期、日期范围、枚举、布尔(开关)、JSON
- 高级字段:流水号、附件、图片、地址、位置、密码、密文、金额、人员信息、拥有者、所属部门、公式
在模型图的底部,点击添加即可显示选择字段类型抽屉。
公共属性
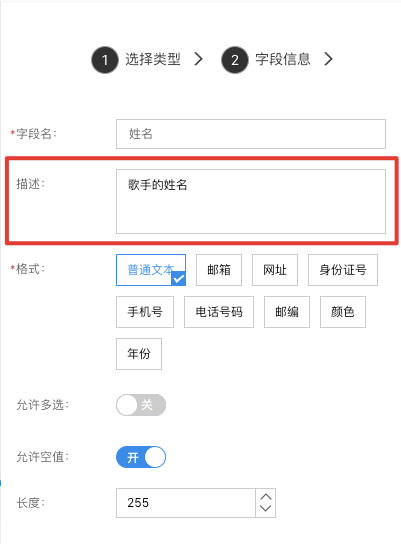
- 字段名:模型的字段名,支持中文与英文;
- 描述:描述当前字段作用,一般会在对应表单项下展示;
- 允许多选:部分字段不支持该属性,配置字段是否支持以多选模式进行选值
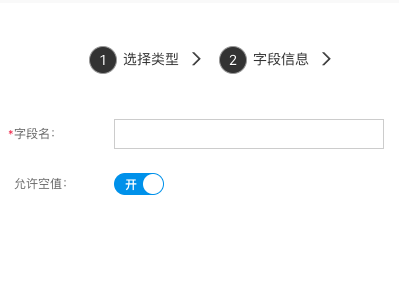
- 允许空值:配置字段是否可以为空
文本
用来存储小段文本信息,比如:名称、邮箱、网址、身份证号等等。
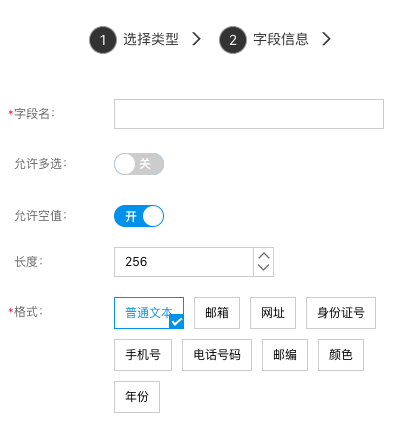
- 格式:表单项和静态展示中,该字段的输出格式
- 长度:该字段可存的最大长度
多行文本
用来存储大片文本信息,长度不限,可以用来存储文章内容。
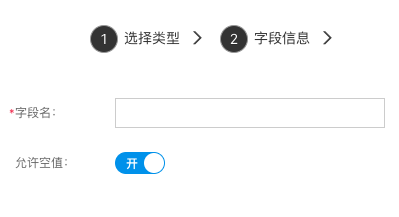
- 文字识别:该字段输入时是否支持图片识别文字
整数
用来存储整型数据,比如:年龄、长度、距离等等。
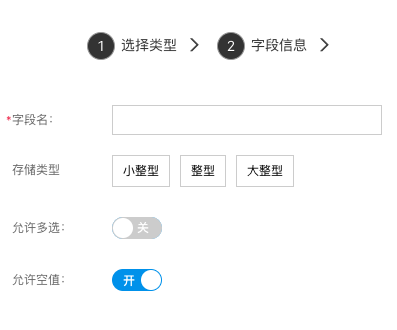
- 存储类型:字段存储类型,请根据需求选择
浮点数
用来存储带小数点的数字,比如:经度、纬度等等。
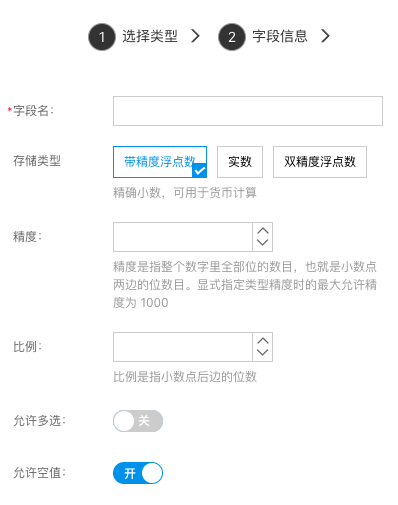
- 存储类型:字段存储类型,请根据需求选择
- 精度:精度是指整个数字里全部位的数目,也就是小数点两边的位数目。显式指定类型精度时的最大允许精度为 1000
- 比例:比例是指小数点后数字的位数
日期
用来存储日期格式,包含:日期时间、日期、时间和时间戳格式。
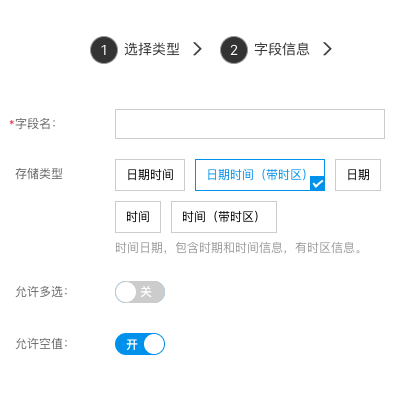
- 存储类型:字段存储类型,请根据需求选择
日期范围
用来存储日期范围格式。
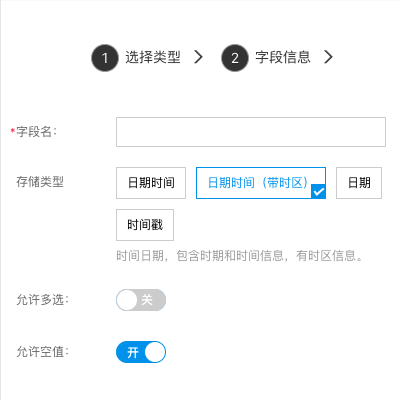
- 存储类型:字段存储类型,请根据需求选择
枚举
用来存储固定的某几个值,常用来存储状态。
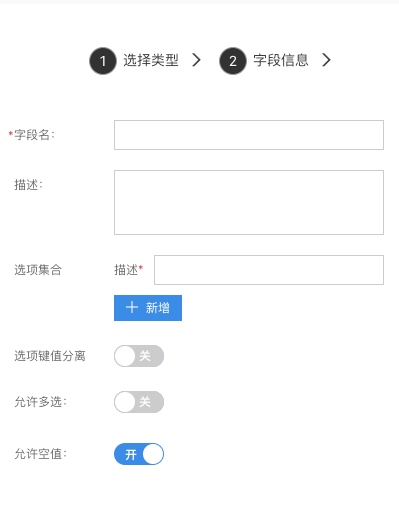
- 选项集合:配置枚举的选项组;
- 选项键值分离:选项组内单个选项是否是键值对分离的格式
布尔(开关)
用来存储是与否。
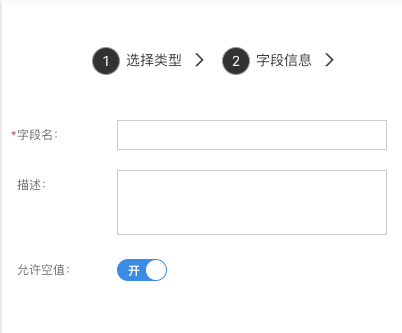
JSON
用来存储复杂数据,对象、数组、字符、数字等都能支持。但是不可以用于检索和排序。
流水号
系统自动生成字段,根据预设规则生成流水号信息。
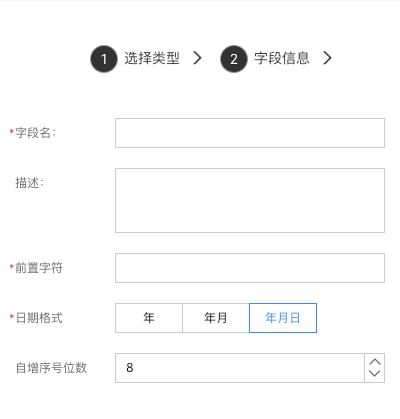
- 前置字符:生成流水号中的前置字符;
- 日期格式:流水号中日期的格式;
- 自增序号位数:自增序号的数字位数
附件
用来存储文件,一般用于用户上传。
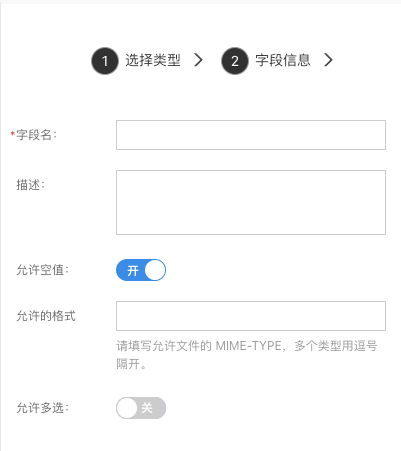
- 允许的格式:填写限制上传的文件格式,为文件后缀名,例如:.mp3。配置多个可以用逗号分隔,例如:.mp3,.mp4
图片
用来存储图片,一般用于用户图片上传。
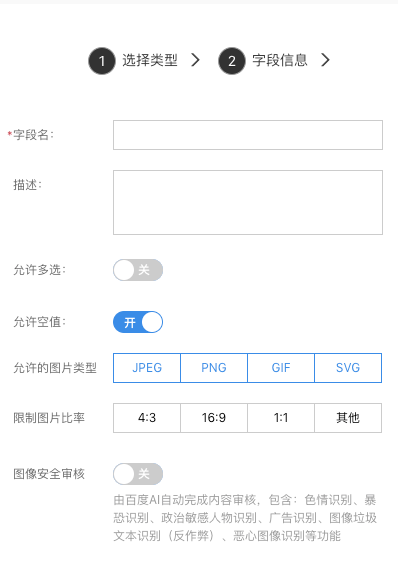
- 允许图片类型:勾选允许的图片类型;
- 限制图片比率:配置是否限制图片比率
- 图像安全审核:是否开启图片安全审核功能,由百度 AI 自动完成内容审核,包含:色情识别、暴恐识别、政治敏感人物识别、广告识别、图像垃圾文本识别(反作弊)、恶心图像识别等功能
地址
用来存储地址,包含省份、城市、地区街道信息。
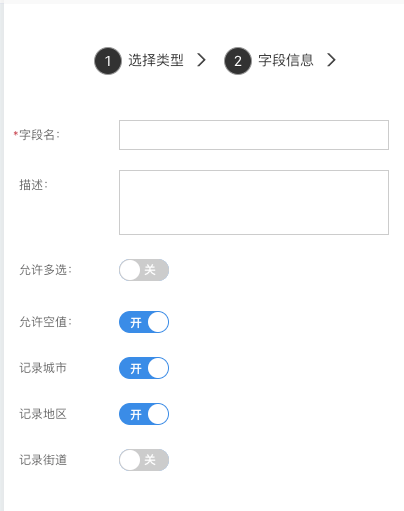
- 记录城市:是否记录城市名
- 记录地区:是否记录地区名
- 记录街道:是否记录街道名
位置
用来存储地理位置,包含经纬度信息。
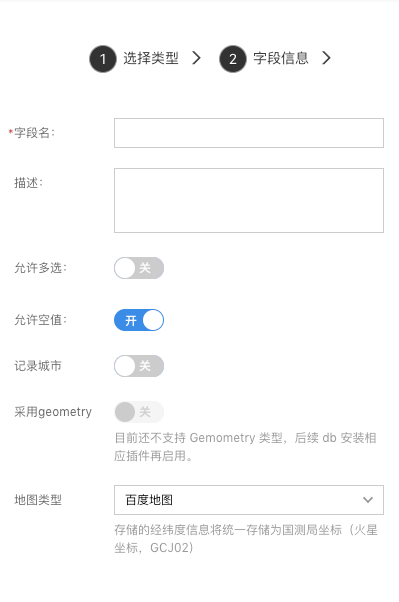
- 记录城市:是否记录城市;
- 采用 geometry:尚未支持,敬请期待;
- 地图类型:选择地图插件类型,目前只支持百度地图
密码
用来存储密文,只能用于结果比对,不可反解。
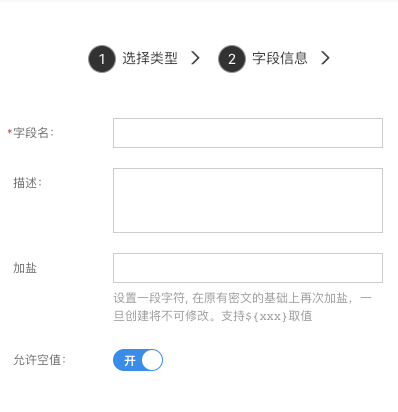
- 加盐:密码加盐。在密码学中,是指通过在密码任意固定位置插入特定的字符串,让散列后的结果和使用原始密码的散列结果不相符,这种过程称之为“加盐”。
密文
用来存储加密文本,可反解。
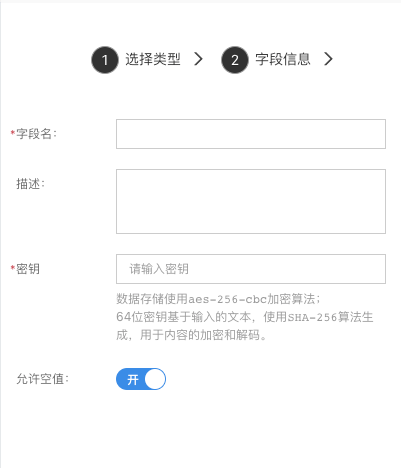
- 密钥:数据存储使用 aes-256-cbc 加密算法;64 位密钥基于输入的文本,使用 SHA-256 算法生成,用于内容的加密和解码。
金额
用来存储金额类型字段,单位为分
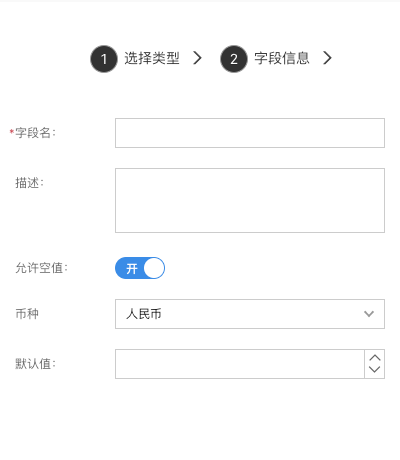
- 币种:选择币种
人员信息
可用来存储人员信息,与平台用户信息关联。
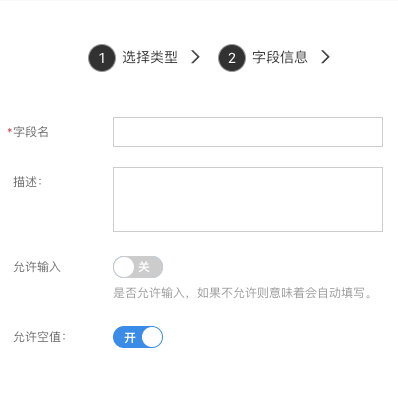
- 允许输入:配置是否允许输入,如果不允许则意味着会自动设置当前操作人。
拥有者
用来存储数据所属人员信息,可用于权限设置。
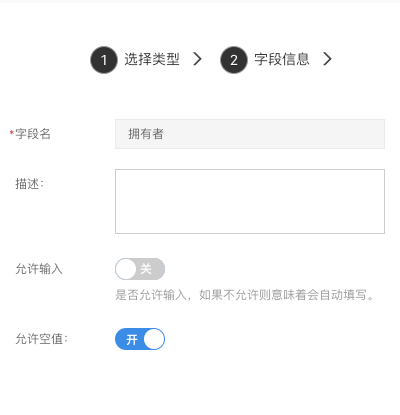
- 允许输入:配置是否允许输入,如果不允许则意味着会自动设置当前操作人。
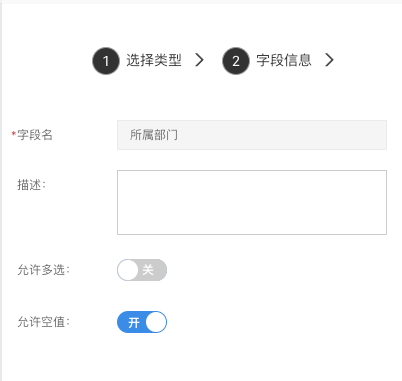
所属部门
用来存储数据所属部门信息,可用于权限设置。
公式
不存储数据,根据公式自动计算结果
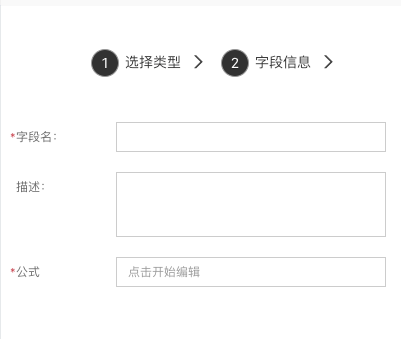
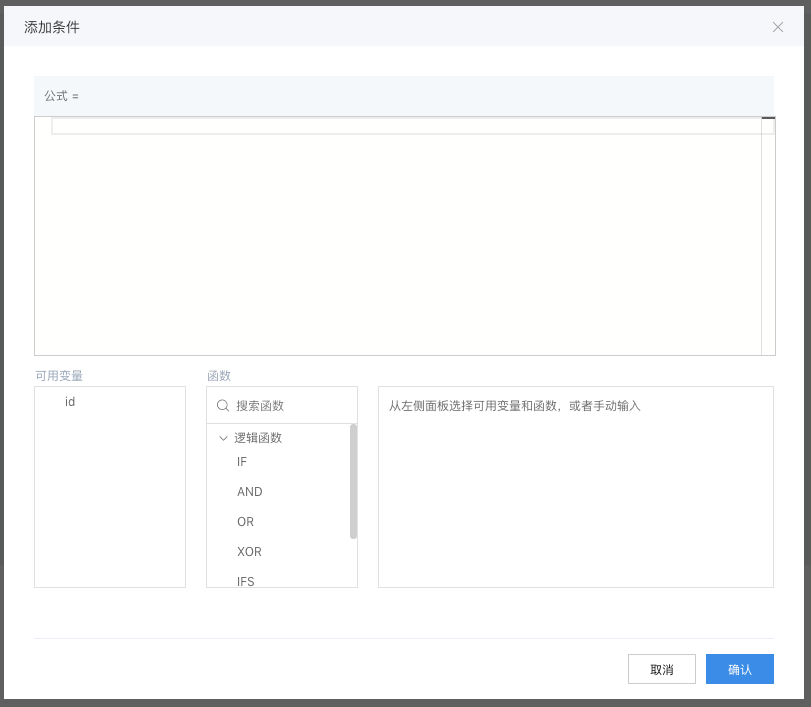
公式编辑:
编辑字段
可以在模型图中的字段右侧,鼠标悬浮在字段上,可以点击“铅笔”符号编辑字段属性。
删除字段
可以在模型图中的字段右侧,鼠标悬浮在字段上,可以点击“减号”符号删除字段。
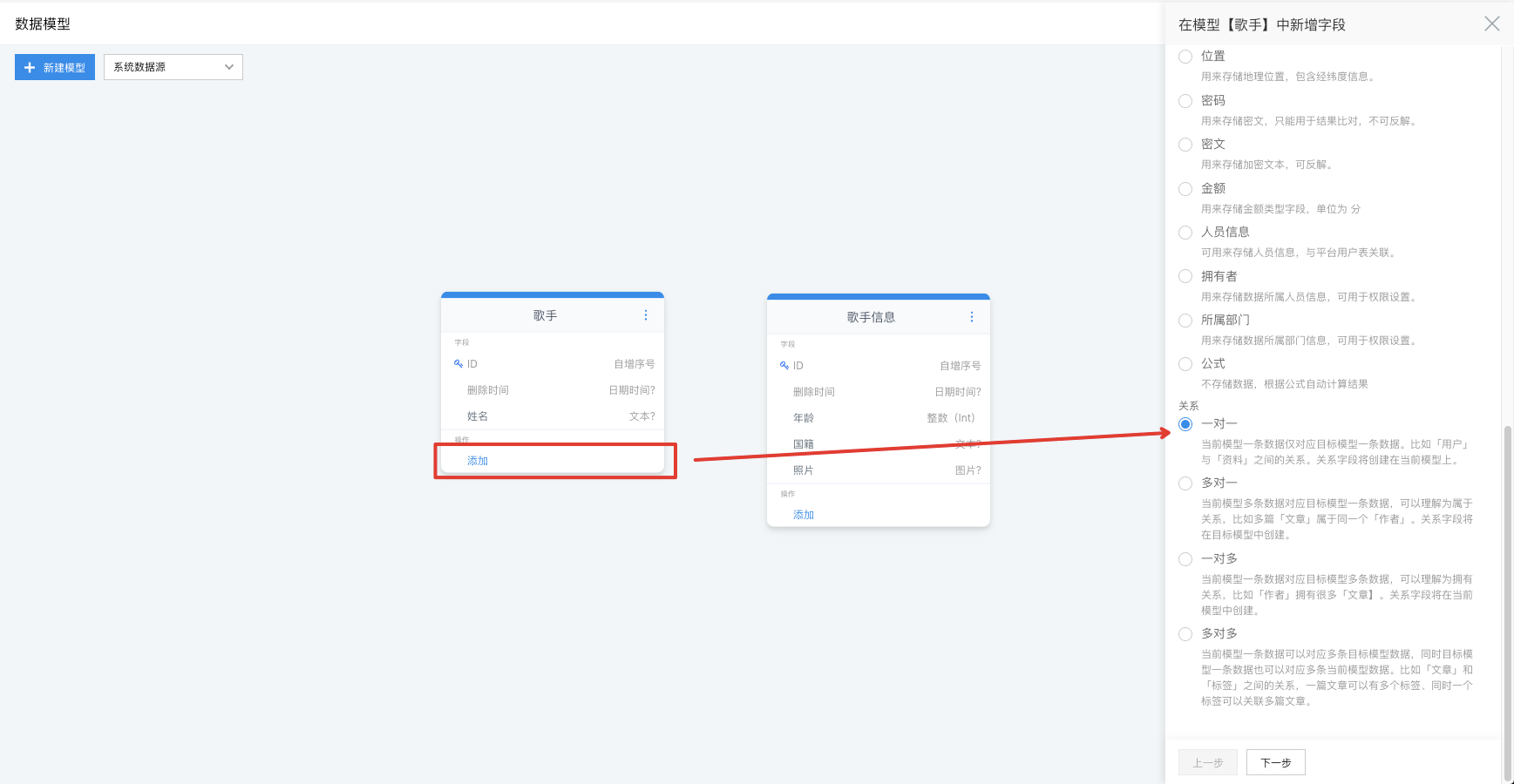
添加关系
可以给模型添加关系,从而关联其他模型,更加方便实现数据间的联通。

一对一
首先我们准备两个模型,分别为:【歌手】和【歌手信息】
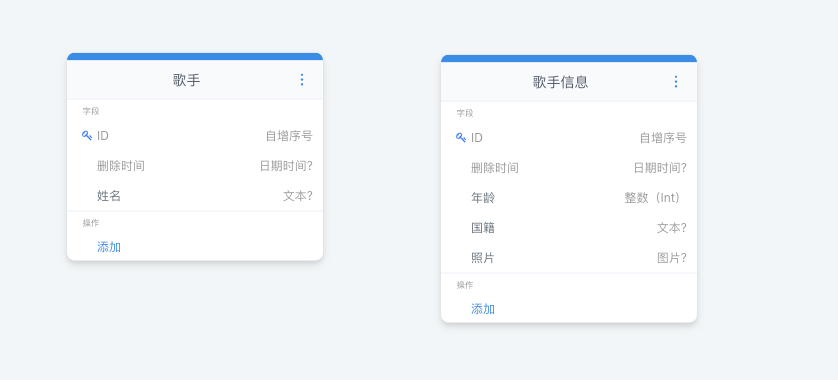
然后我们为【歌手】添加一对一关系,关联【歌手信息】
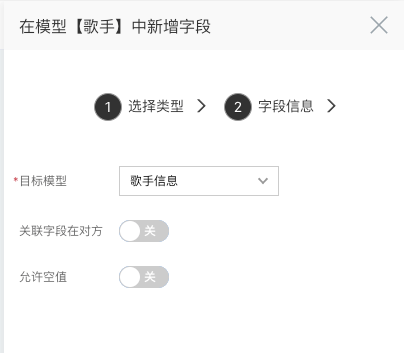
- 目标模型:选择要关联的模型,这里我们选择【歌手信息】
- 关联字段在对方:配置标记关联关系的字段是否在对方,这里我们暂时不开启
- 允许空值:该关系字段是否可以为空
点击确认添加成功后,我们可以看到关系已经成功关联。
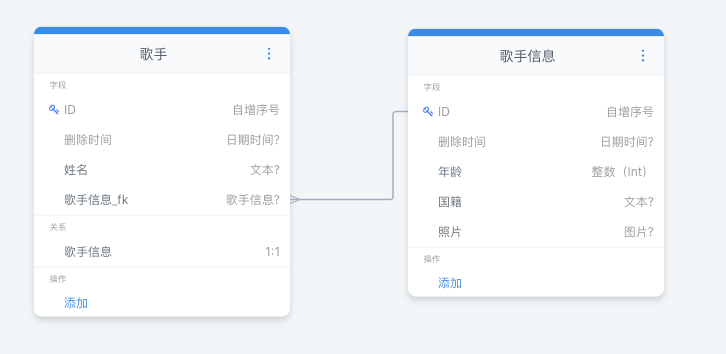
歌手信息_fk 是 歌手信息外键的意思
这时候我们来到数据管理,点击新建歌手时,可以看到可以同步添加歌手信息了:
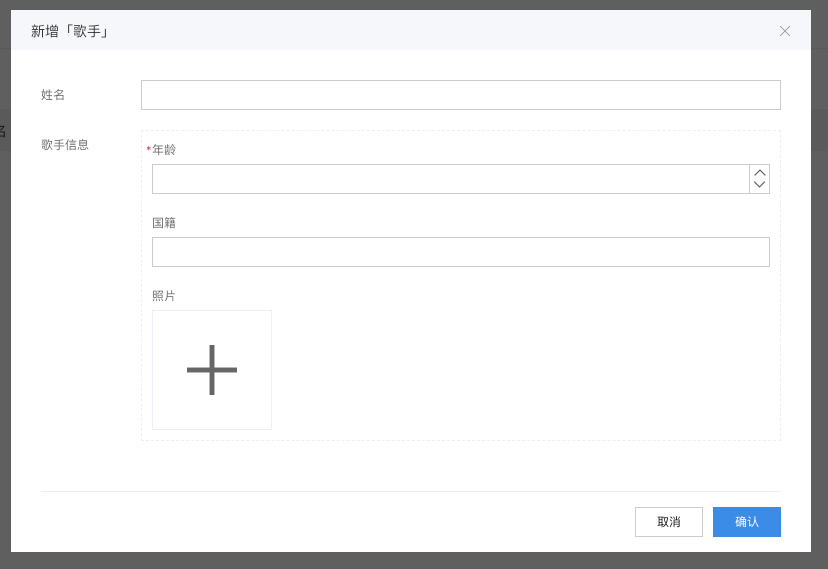
我们添加一条数据:
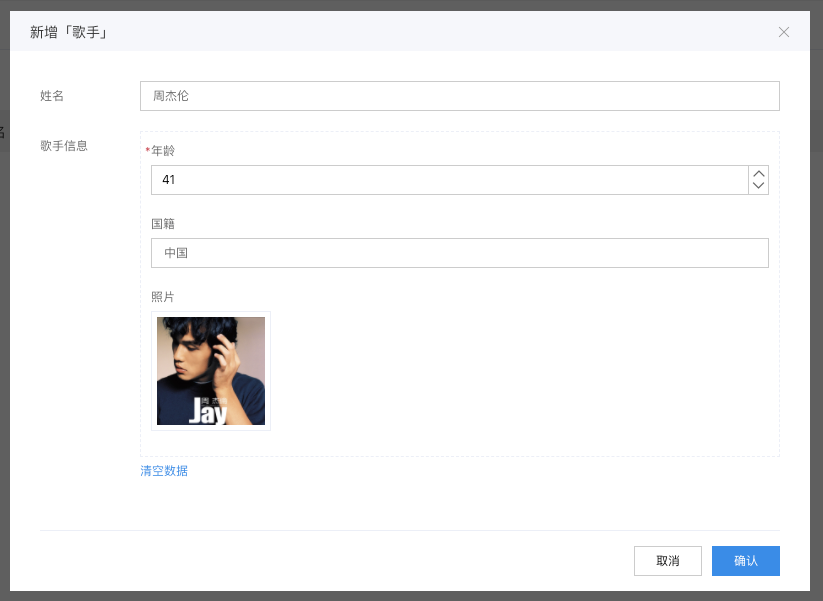
添加成功后,我们去看歌手信息数据管理页面,可以看到也同步添加了一条信息:

多对一
首先我们准备两个模型,分别是:【歌手】和【专辑】
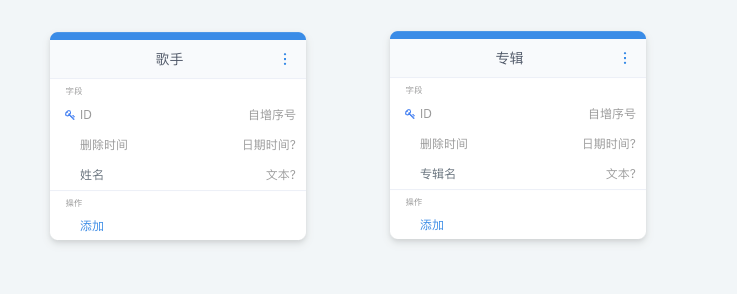
因为一个【歌手】可以对应多个专辑,因此我们在【专辑】上添加多对一关系:
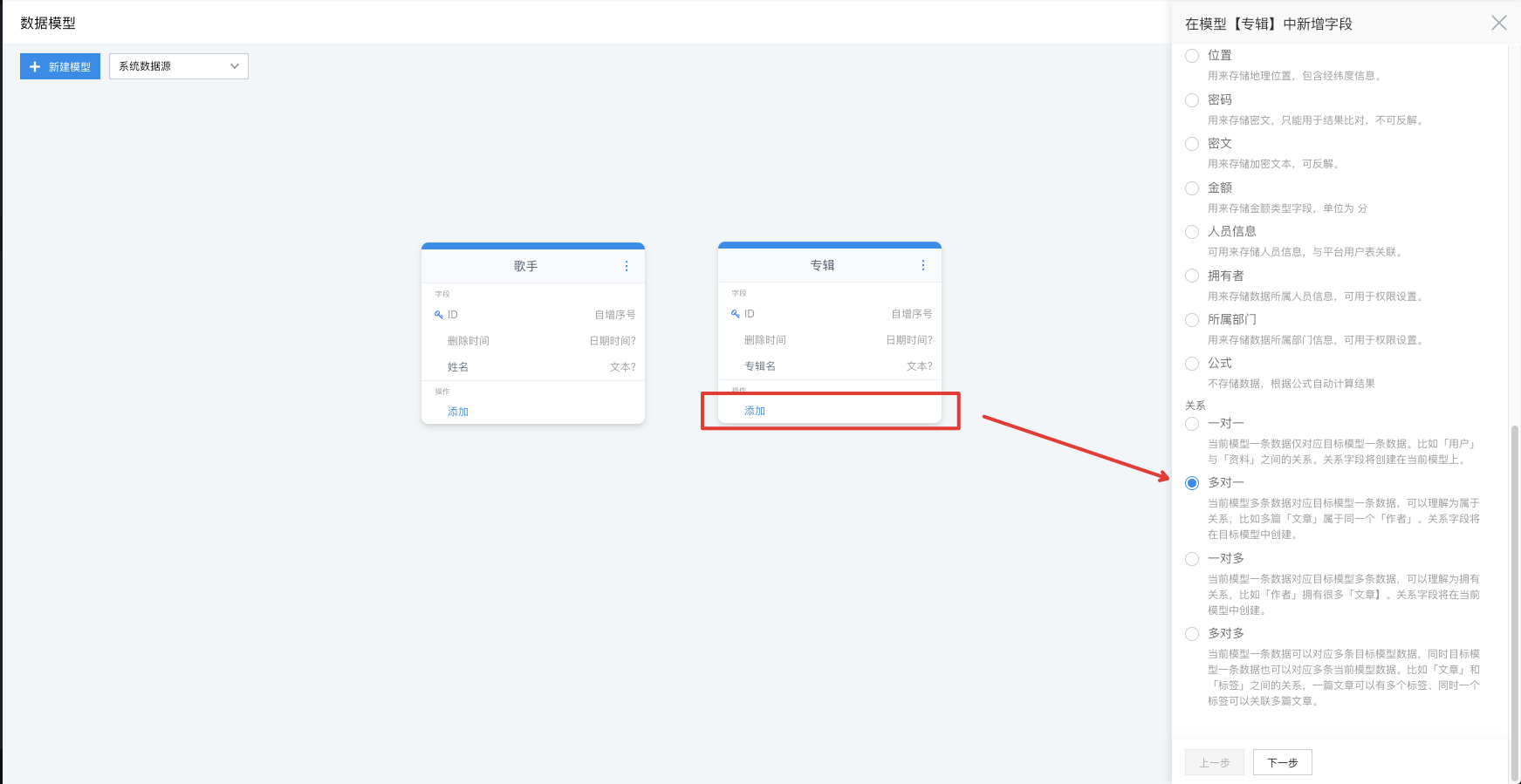
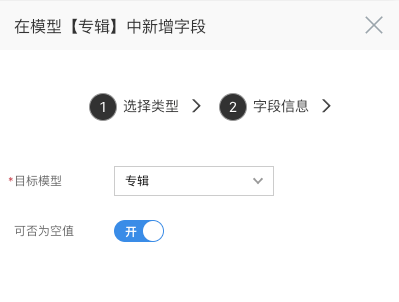
- 目标模型:选中需要关联的目标模型,这里我们选择【歌手】
- 可否为空值:关系字段是否可以为空值;
确认后,添加成功
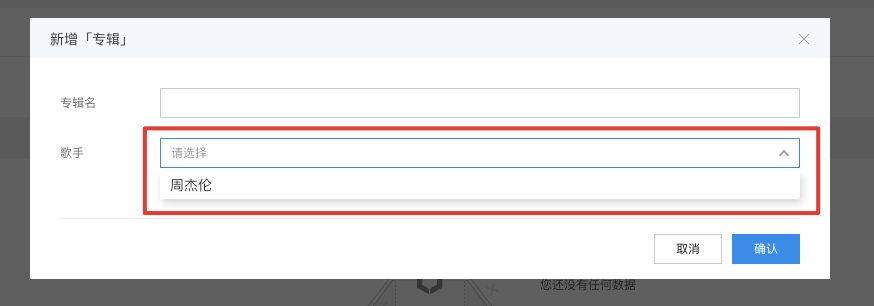
 来到专辑的数据管理中,我们点击新增专辑,可以看到出现了勾选歌手的表单项:
来到专辑的数据管理中,我们点击新增专辑,可以看到出现了勾选歌手的表单项:

一对多
同样因为一个歌手对应多个专辑,我们也可以给歌手模型上添加一对多关系:
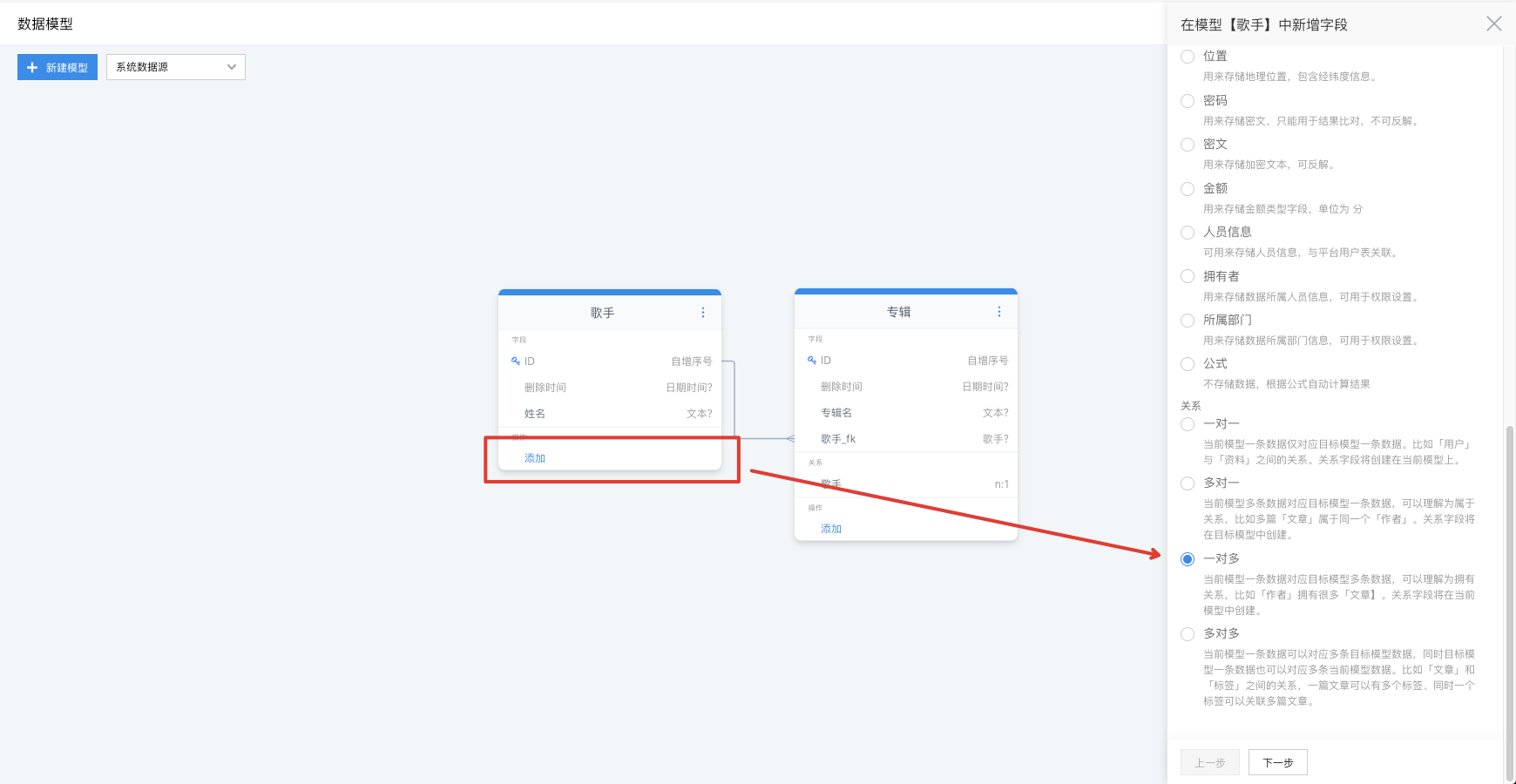
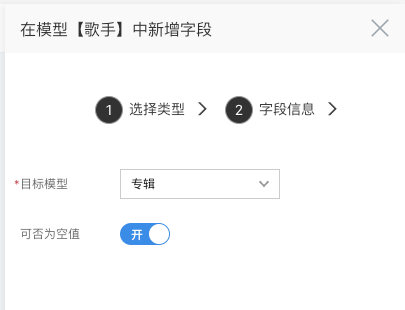
- 目标模型:选中需要关联的目标模型,这里我们选择【专辑】
- 可否为空值:关系字段是否可以为空值;
确认后,添加成功
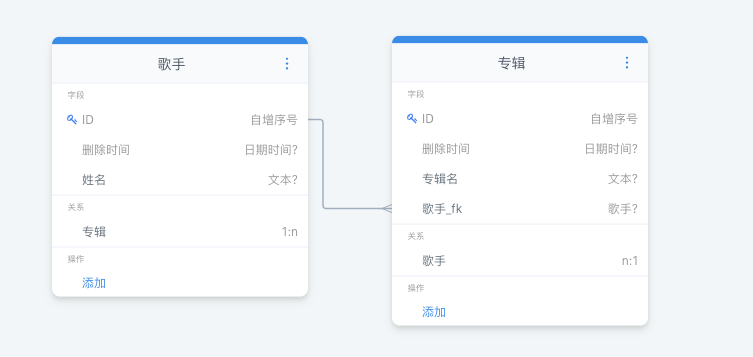
这时我们来到【歌手】的数据管理页面,点击新增歌手,可以看到出现了可以新增【专辑】的表单项
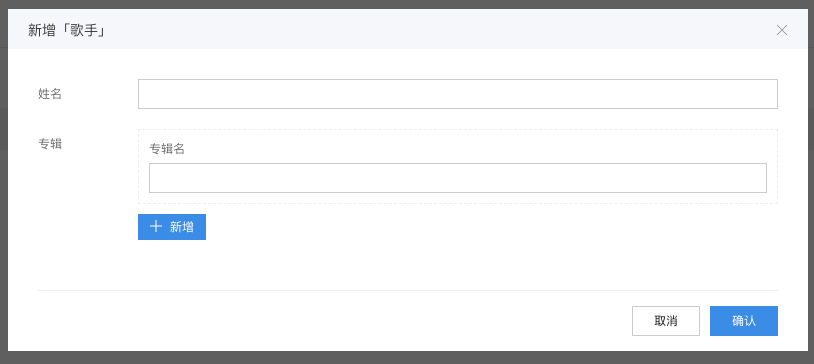
多对多
因为一首【歌曲】有可能有多个【歌手】合作,而一名【歌手】也会有很多首【歌曲】作品,因此我们来添加一个多对多关系。
首先准备【歌手】和【歌曲】模型:
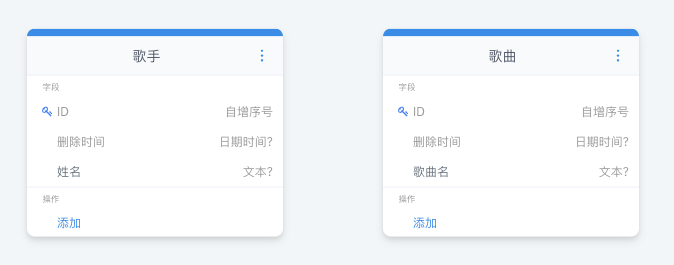
我们先选择在歌手上添加多对多关系
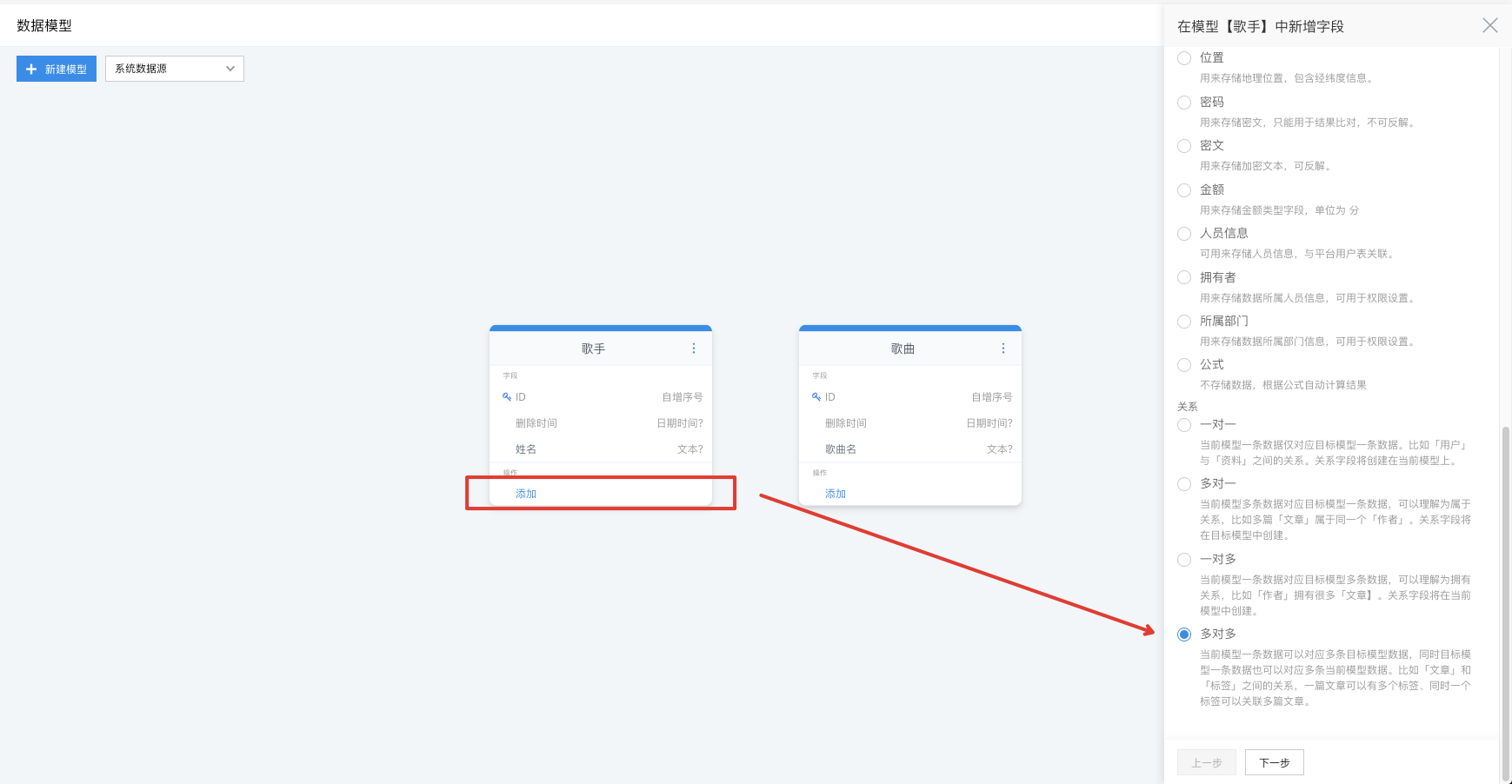
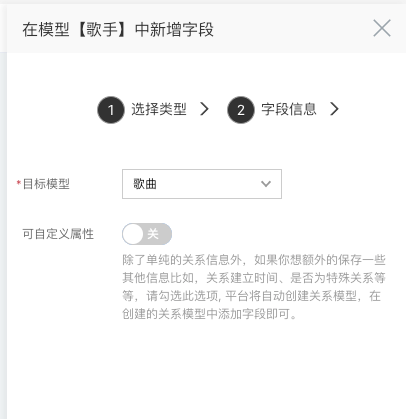
- 目标模型:选中需要关联的目标模型,这里我们选择【歌曲】
- 可自定义属性:除了单纯的关系信息外,如果你想额外的保存一些其他信息比如,关系建立时间、是否为特殊关系等等,请勾选此选项, 平台将自动创建关系模型,在创建的关系模型中添加字段即可。
确认后,添加成功
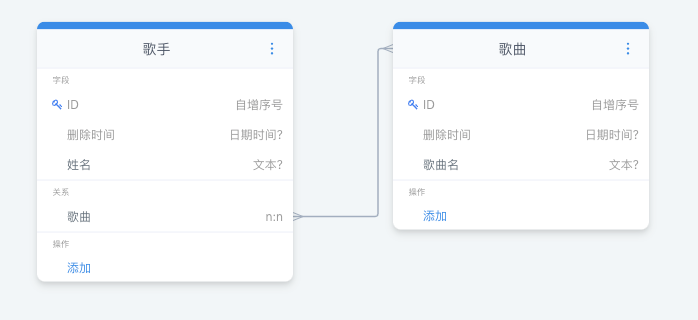
然后我们来到歌手的数据管理界面,点击新增歌手,可以看到出现了勾选歌曲的表单项(需提前添加歌曲数据):
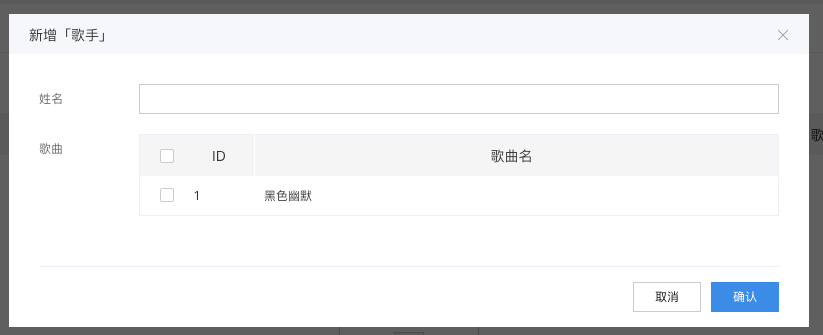
添加数据后,也可以查看关系数据:

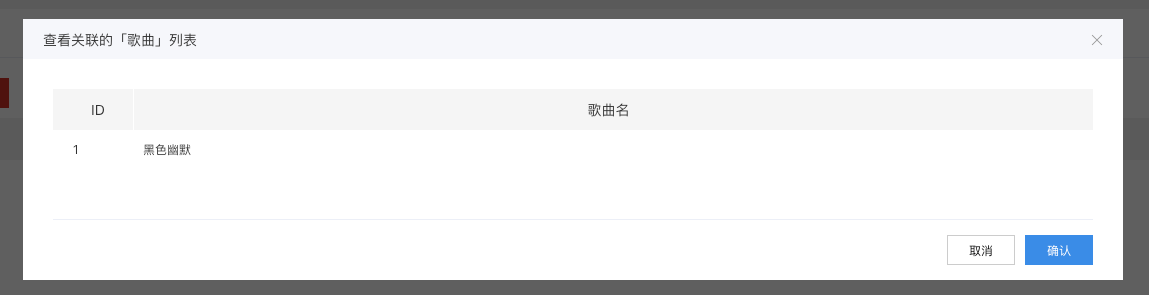
自己来试一试为【歌曲】添加多对多关系吧
编辑关系
可以在模型图中的关系右侧,鼠标悬浮在关系上,可以点击“铅笔”符号编辑关系属性。
删除关系
可以在模型图中的关系右侧,鼠标悬浮在关系上,可以点击“减号”符号删除关系。