

文档简介:



TSDB :Time Series Database,时序数据库,用于保存时间序列(按时间顺序变化)的海量数据。
度量(metric):数据指标的类别,如发动机的温度、发动机转速、模拟量等。
域(field):在指定度量下数据的子类别。即一个metric支持多个field,如metric为wind,该metric可以有两个field:direction和speed。
时间戳(timestamp):数据产生的时间点。
数值(value):度量对应的数值,如56°C、1000r/s等(实际中不带单位)。如果有多个field,每个field都有相应的value。不同的field支持不同的数据类型写入。对于同一个field,如果写入了某个数据类型的value之后,相同的field不允许写入其他数据类型。
标签(tag):一个标签是一个key-value对,用于提供额外的信息,如"设备号=95D8-7913"、“型号=ABC123”、“出厂编号=1234567890”等。
数据点(data point):“1个metric+1个field(可选)+1个timestamp+1个value + n个tag(n>=1)”唯一定义了一个数据点。当写入的metric、field、timestamp、n个tag都相同时,后写入的value会覆盖先写入的value。
时间序列 :“1个metric+1个field(可选) +n个tag(n>=1)”定义了一个时间序列。单域和多域的数据点和时间序列由下图所示:
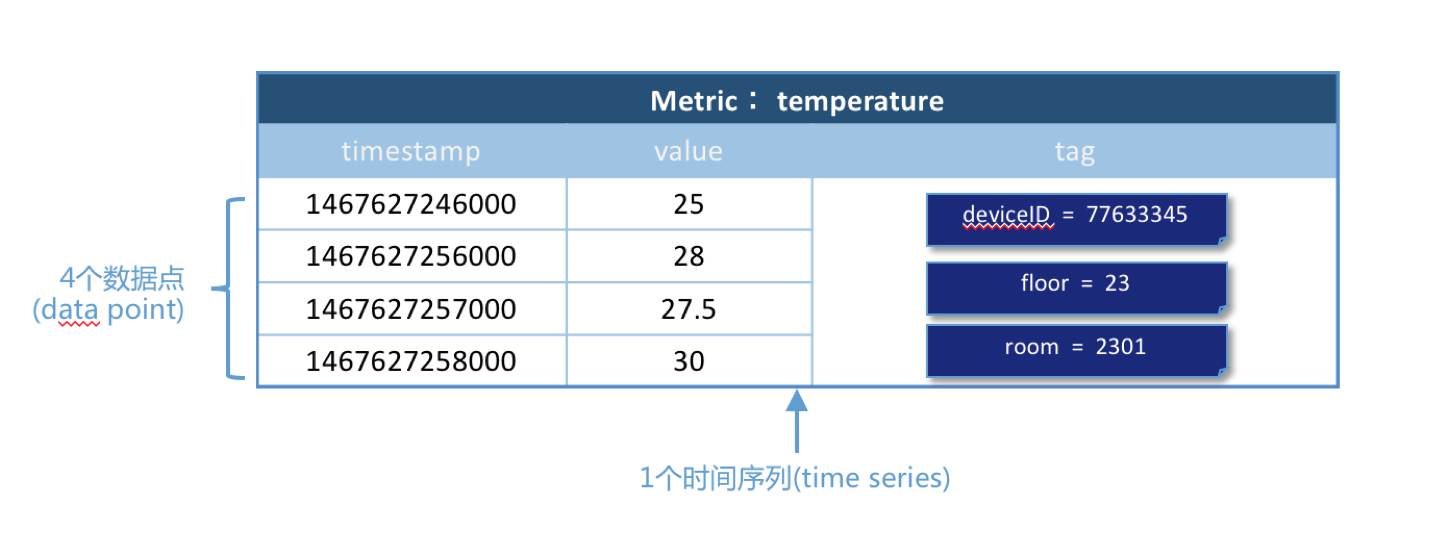
实践一(单域)
监测温度的值,把温度(temperature)作为一个度量(metric),用标签(tag)来标识每一个数据的额外信息,比如每个数据点都有3个tag,tag是一个key-value对,tag的key分别是deivceID、floor、room。
如图所示,表示对温度的时间序列监测值,共4个数据点。在该图中的4个数据点使用的metric、tag是相同的,所以是同一个时间序列。
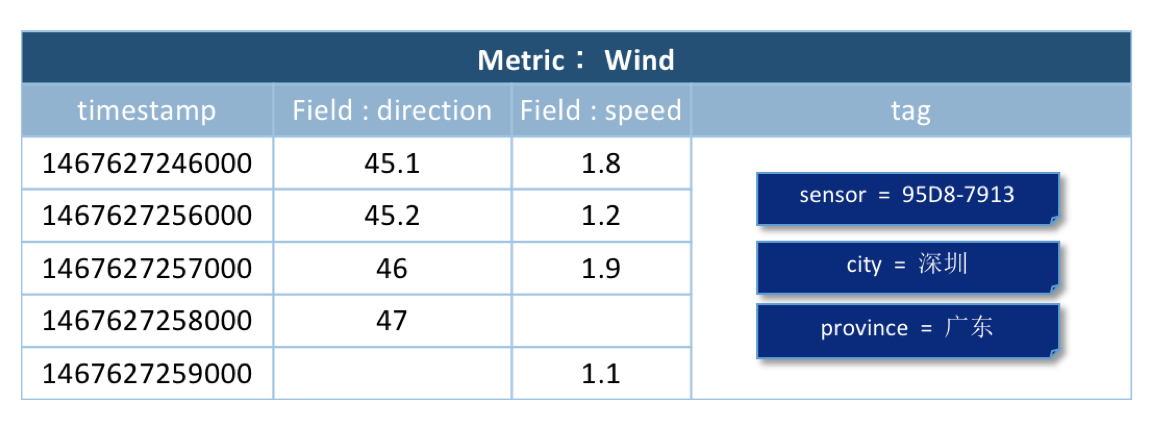
实践二(多域)
监测风力的值,把风力(wind)作为一个度量(metric),风力(wind)分为两个域:风向(direction)和速度(speed)。这些监测数据是从不同的传感器传输到云端的,用标签(tag)来标识每一个数据的额外信息,比如每个数据点有三个tag,tag是一个key-value对;tag的key分别是sensor、city、province。
为了表示在广东省深圳市传感器编号95D8-7913上传风向(direction)数据,可以将这个数据点的tag为标记为sensor=95D8-7913、city=深圳、province=广东。
如图,展示了metric为wind的两个域(speed和direction)的监测数据。当使用的是metric、field和tag是相同的时,是同一个时间序列。即图中有2个时间序列,8个数据点。

将数据采用metric+field的方式存储的优势在于,可以将同一metric下的数据进行多field联合查询。以上图为例,要查询1467627246000-1467627249000时间内风力(wind)的情况,可以联合查询多个field的值,得到下图的数据。
如果写入时没有数据,在查询时,可以采用插值方案将值补充完整,插值的使用说明见数据库操作相关文档。
- tag的key值和value值都相同才算做同一个tag,即deviceid=1和deviceid=2是两个标签。
- 请不要将时间戳作为tag,否则会导致时间序列超过限制,关于时间序列的限制请参考费率表。
分组(group):可以按标签(tag)对数据点进行分组。
聚合函数(aggregator):可以对一段时间的数据点做聚合,如每10分钟的和值、平均值、最大值、最小值等。TSDB目前支持的聚合函数请参考文档
数据库(database):一个用户可以有多个数据库,一个数据库可以写入多个“度量”的“数据点”。
