文档简介:



实时作业创建
点击新建按钮,弹出【新建作业】弹窗。输入实时开发作业名称。
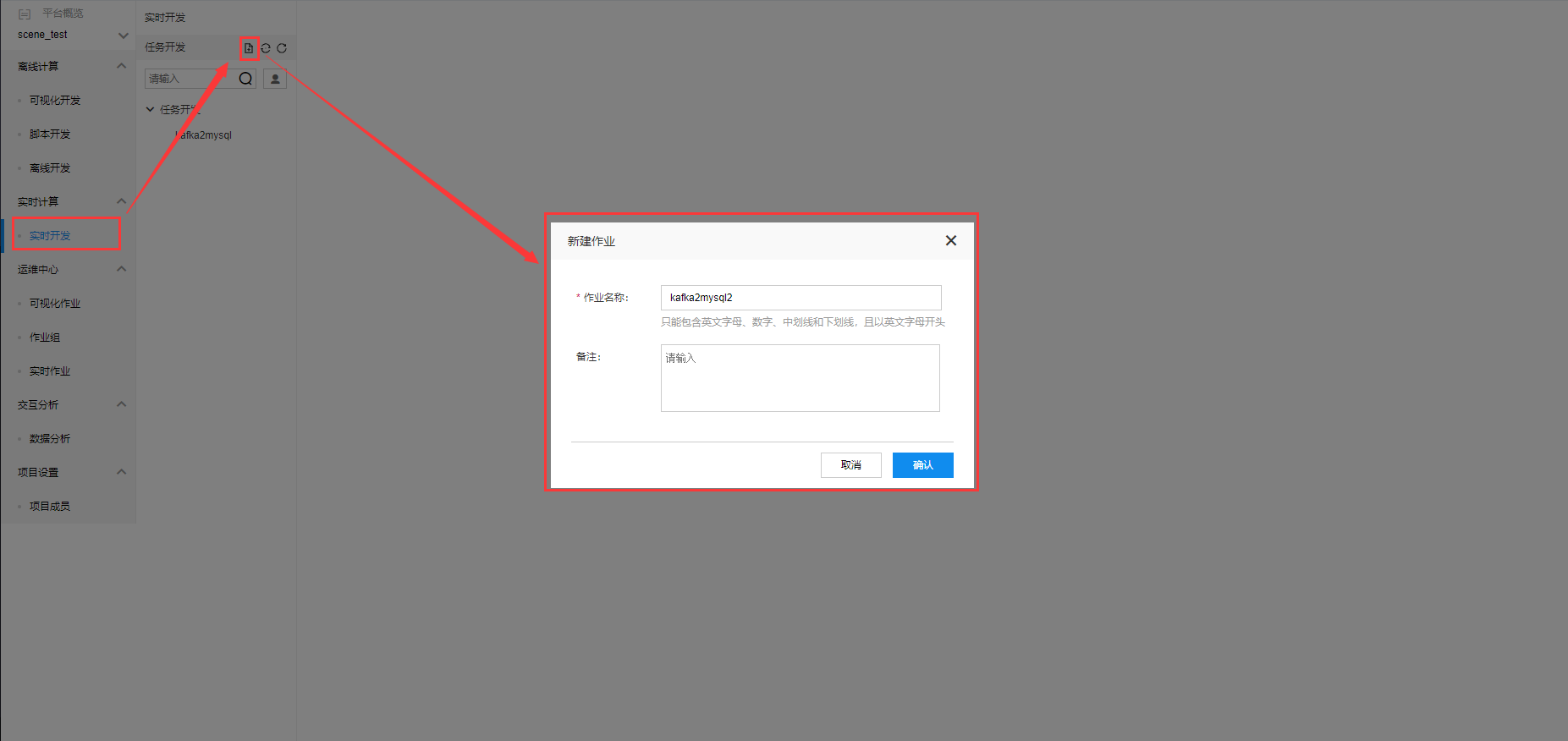
点击【确定】。在【任务开发】列表中,显示创建任务。并且在开发面板中显示实时作业支持插件。
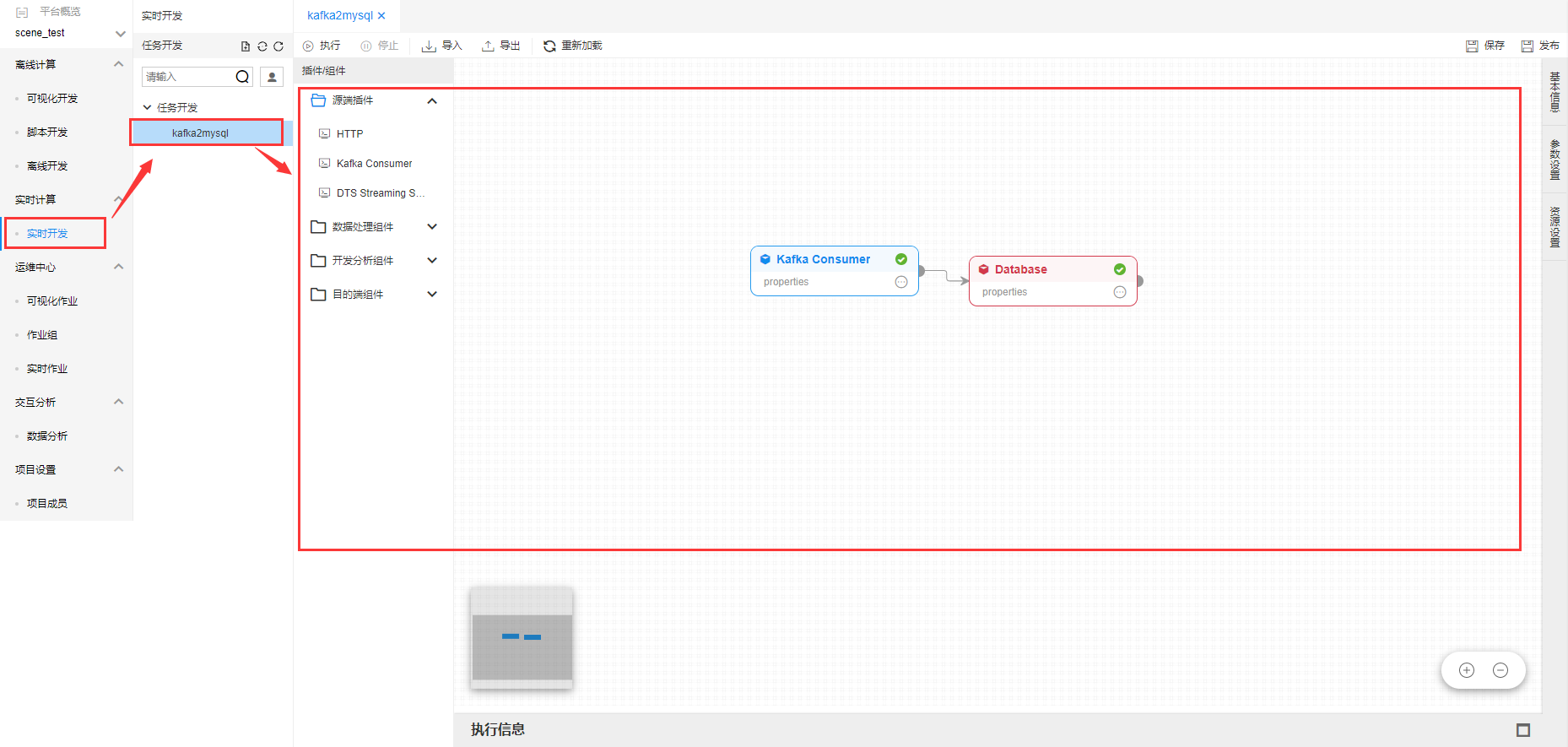
目前实时计算支持计算引擎为Spark Streaming引擎。Flink引擎即将升级支持。
实时作业编辑
实时作业支持四种类型插件。源端插件、数据处理组件、开发分析组件和目标端插件。
- 源端插件:作为整个作业的数据输入端,源端插件只能作为流水线的开始节点,下游可以连接数据处理组件、开发分析组件或者直接连接目标端插件。
- 数据处理组件:对上游源端插件的数据进行数据处理,用户可以使用脚本类插件对数据进行处理。
- 数据开发组件:对上游源端插件的数据进行数据开发,用户可以使用SQL抽象插件进行数据处理。
- 目标端插件:将上游处理好的数据写入到目标端插件。且目标端插件需要作为流水线的最后节点。
源端插件
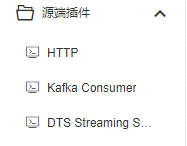
目前源端支持【HTTP】、【Kafka Consumer】、【DTS Streaming Source】三种。
用户可以返回将源端插件拖拽到开发画布中,作为实时数据的源端。
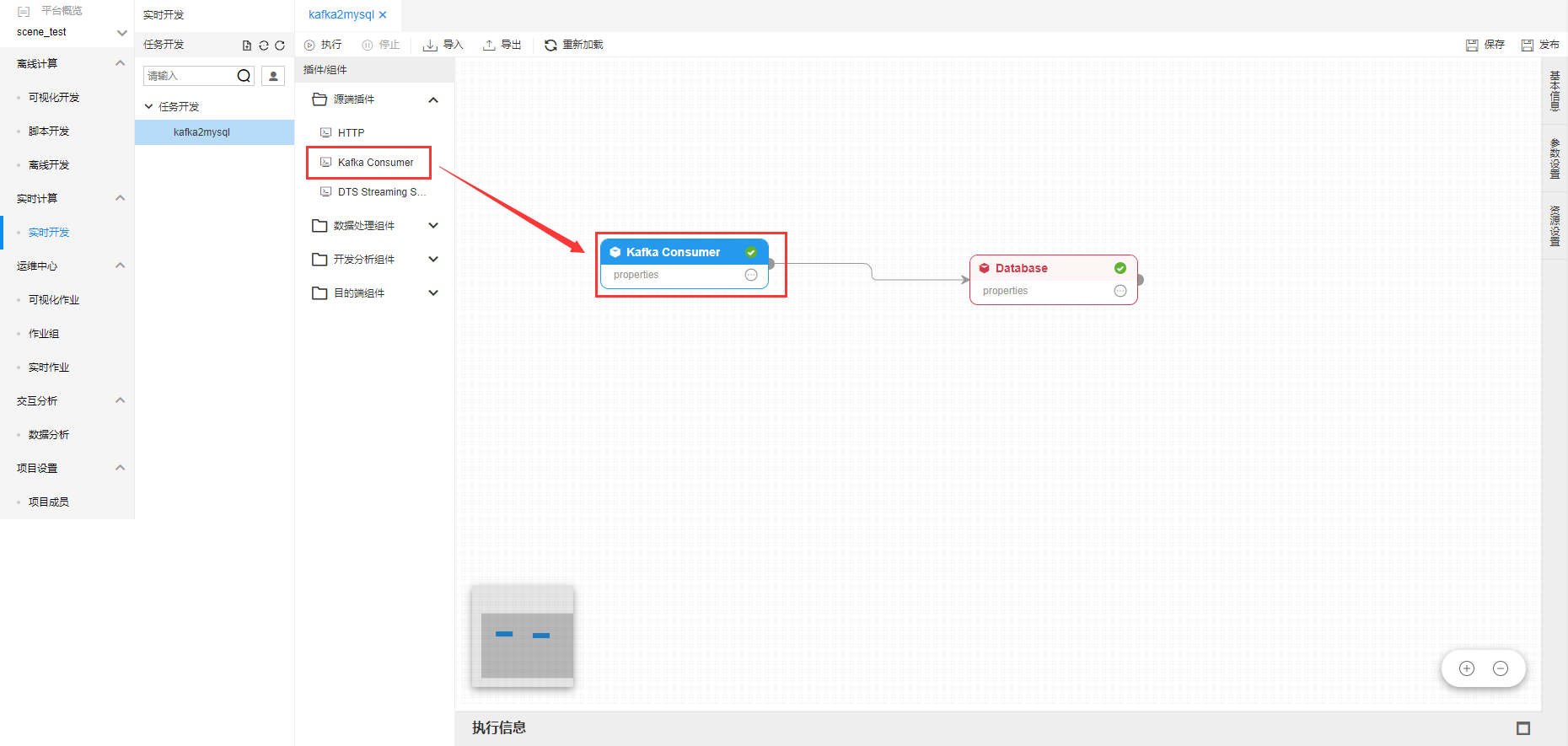
点击源端插件,弹出编辑框。
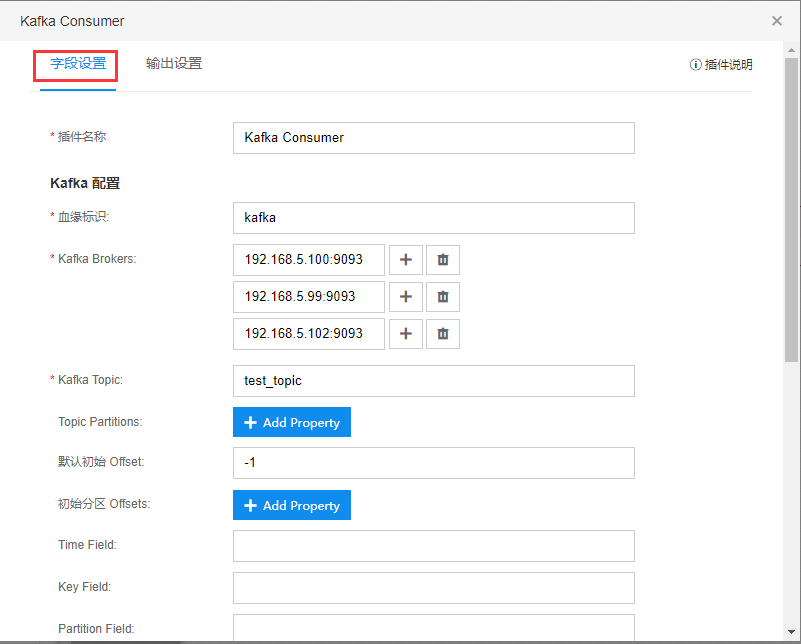
【字段设置】中进行插件相关的设置。具体设置规则可以点击【插件说明】对每个字段进行解释。
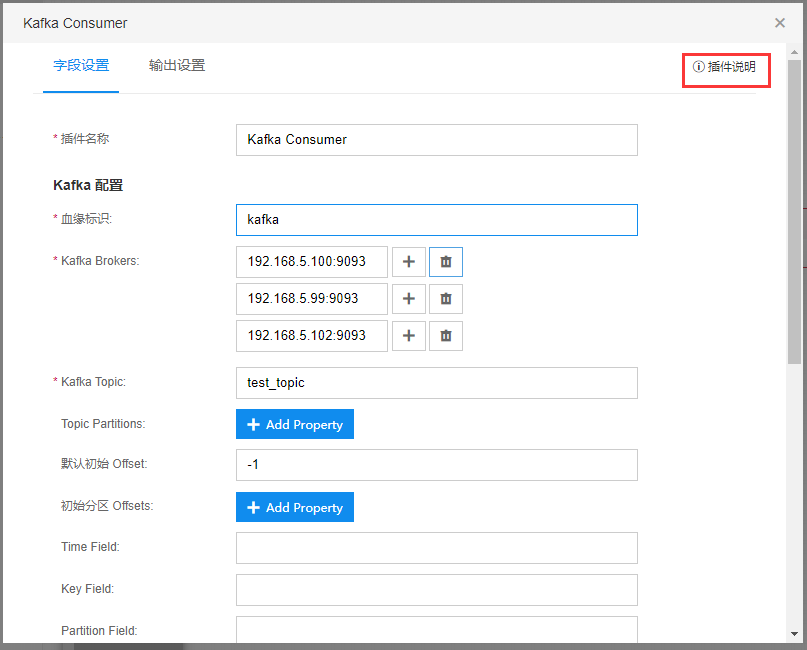
弹窗显示插件使用说明。

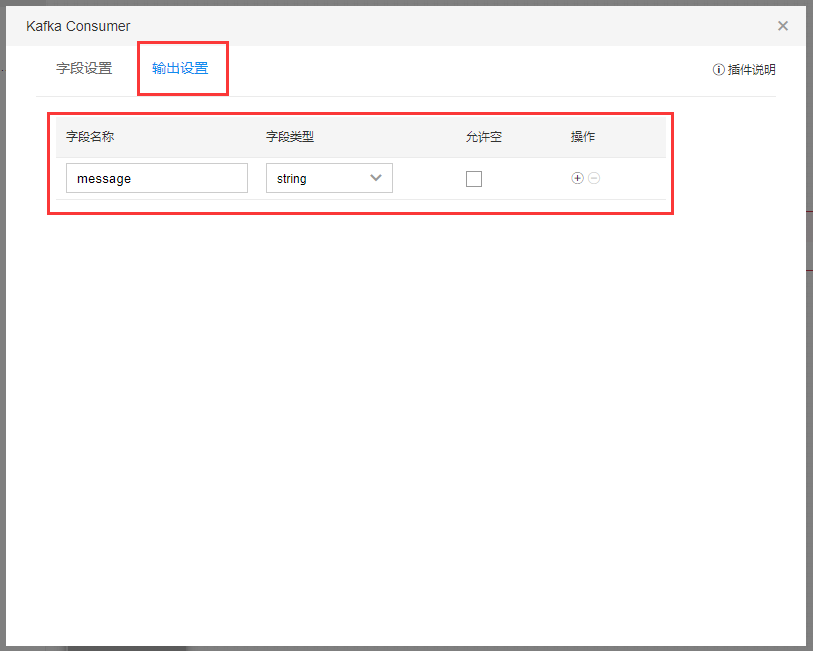
在插件【输出设置】中进行字段设置,此字段会向后传递。
数据处理组件
数据处理组件拖拽到开发面板之后,将上游的源端插件连接到数据处理组件中。
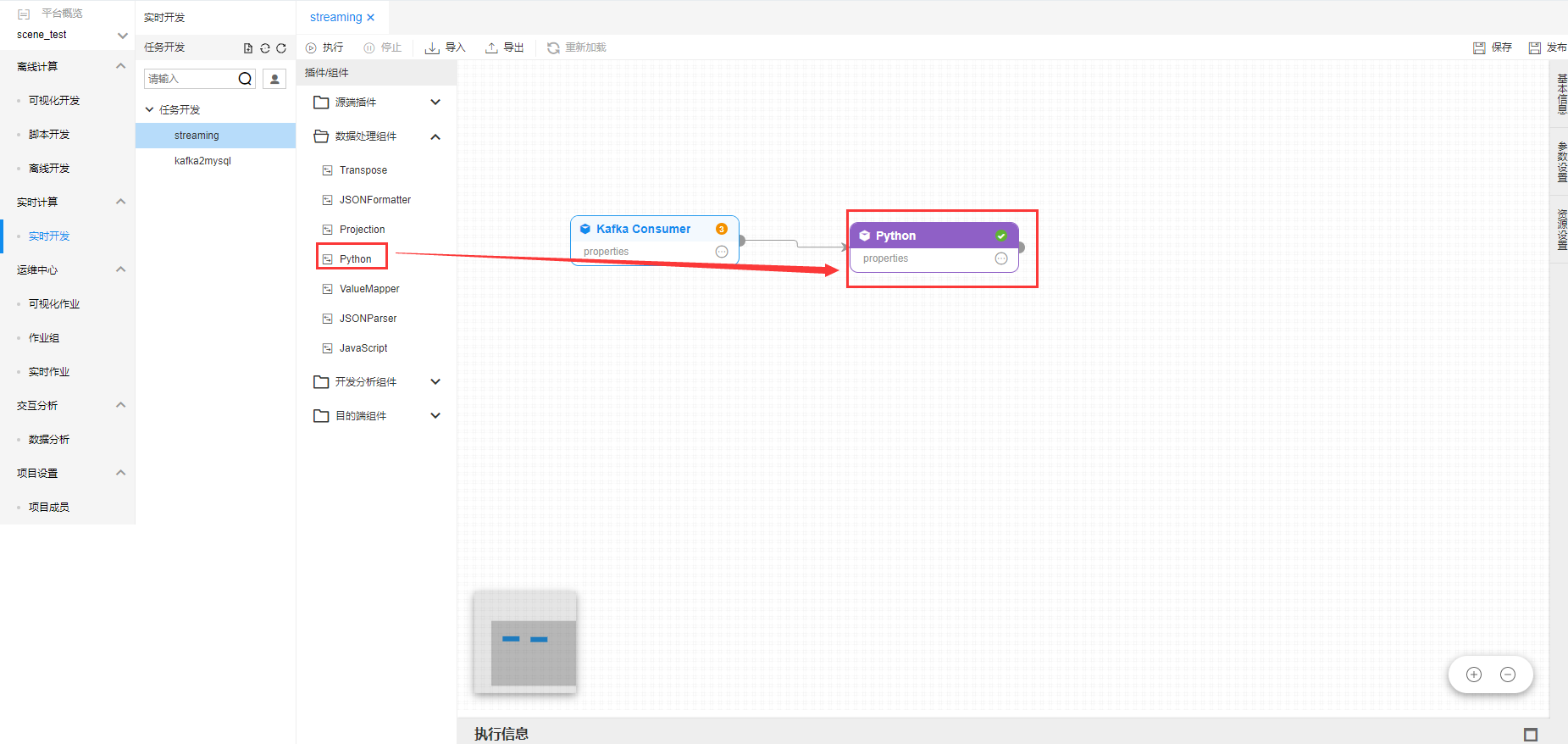
点击【数据处理组件】-【Python】,显示插件编辑框。
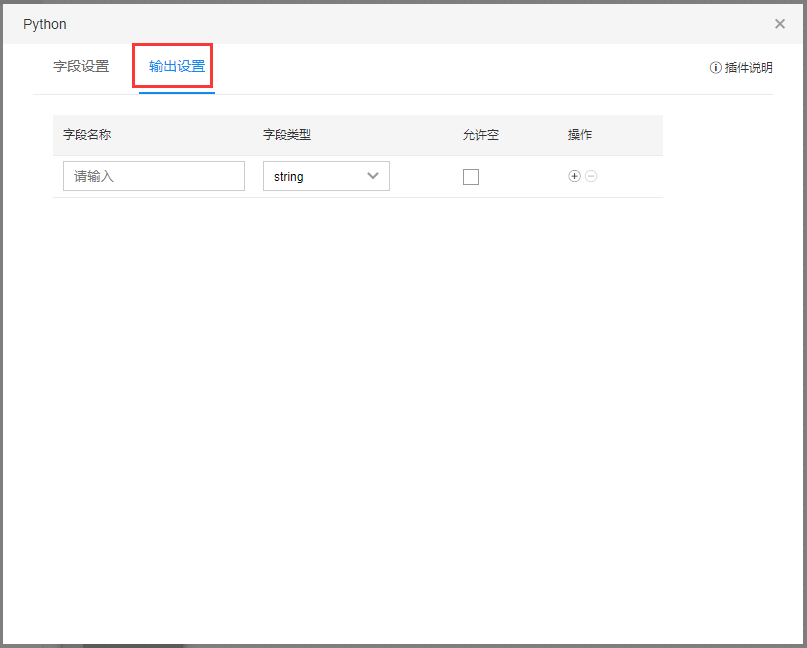
在【输出设置】中,设置插件输出字段。
具体插件的使用说明,可以点击弹窗中插件说明查看使用说明。

使用说明弹窗如下:

开发分析组件
【开发分析组件】和【数据处理组件】使用流程相同,在源端插件之后,进行数据处理。
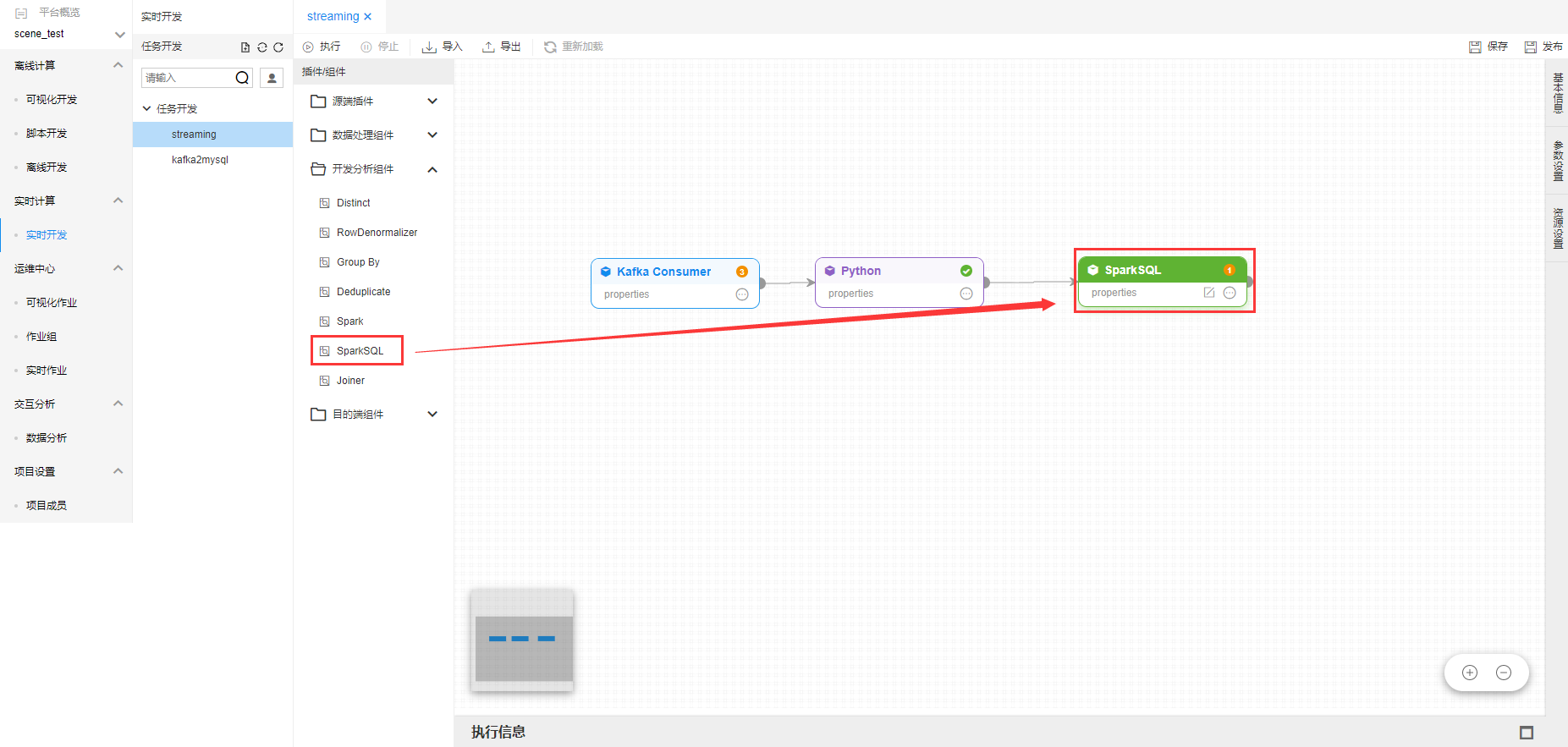
点击【开发分析组件】-【SparkSQL】,显示插件编辑框。

在【输出设置】中,设置插件输出字段。

具体插件的使用说明,可以点击弹窗中插件说明查看使用说明。
使用说明弹窗如下:

目标端插件
实时作业支持目标端。用户可以将实时作业,处理加工的数据流接入到目标端。目标端可以是另一个kafka消息队列,也可以是Hive等数据库。
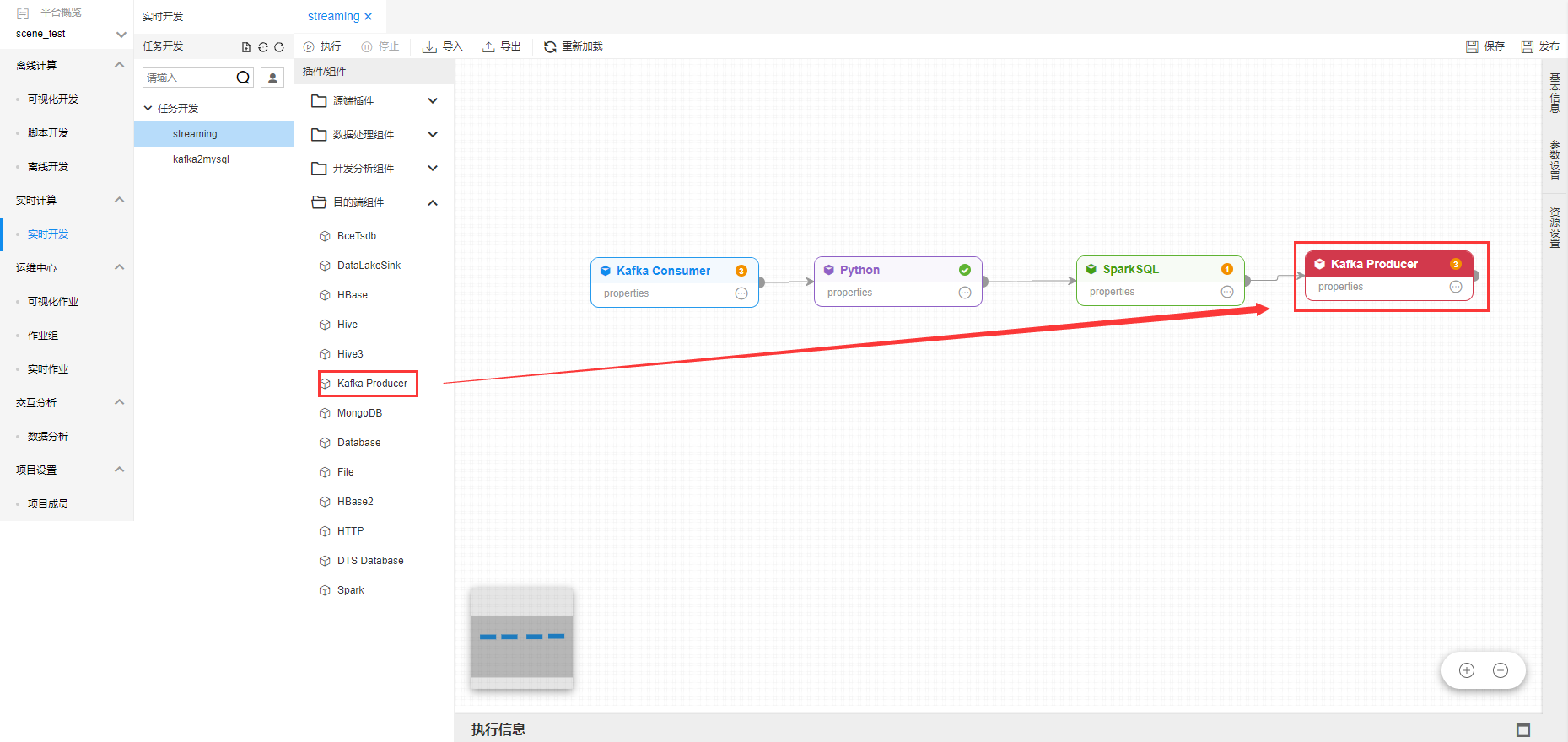
点击【目标端插件】-【Kafka Producer】,显示插件编辑框。
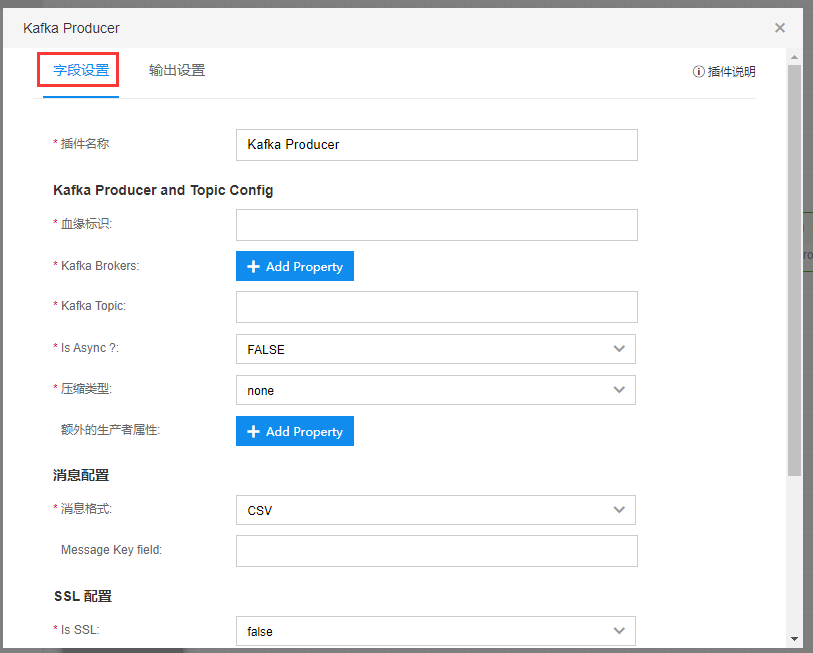
具体插件的使用说明,可以点击弹窗中插件说明查看使用说明。

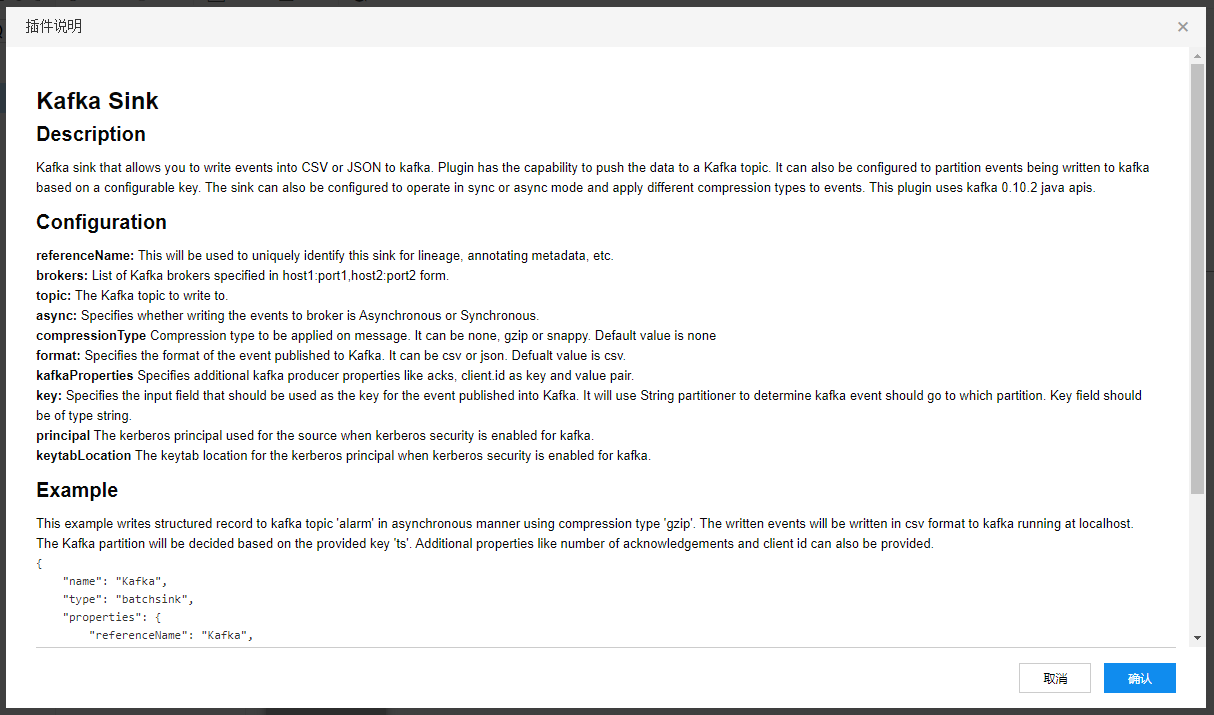
使用说明弹窗如下:
实时作业配置
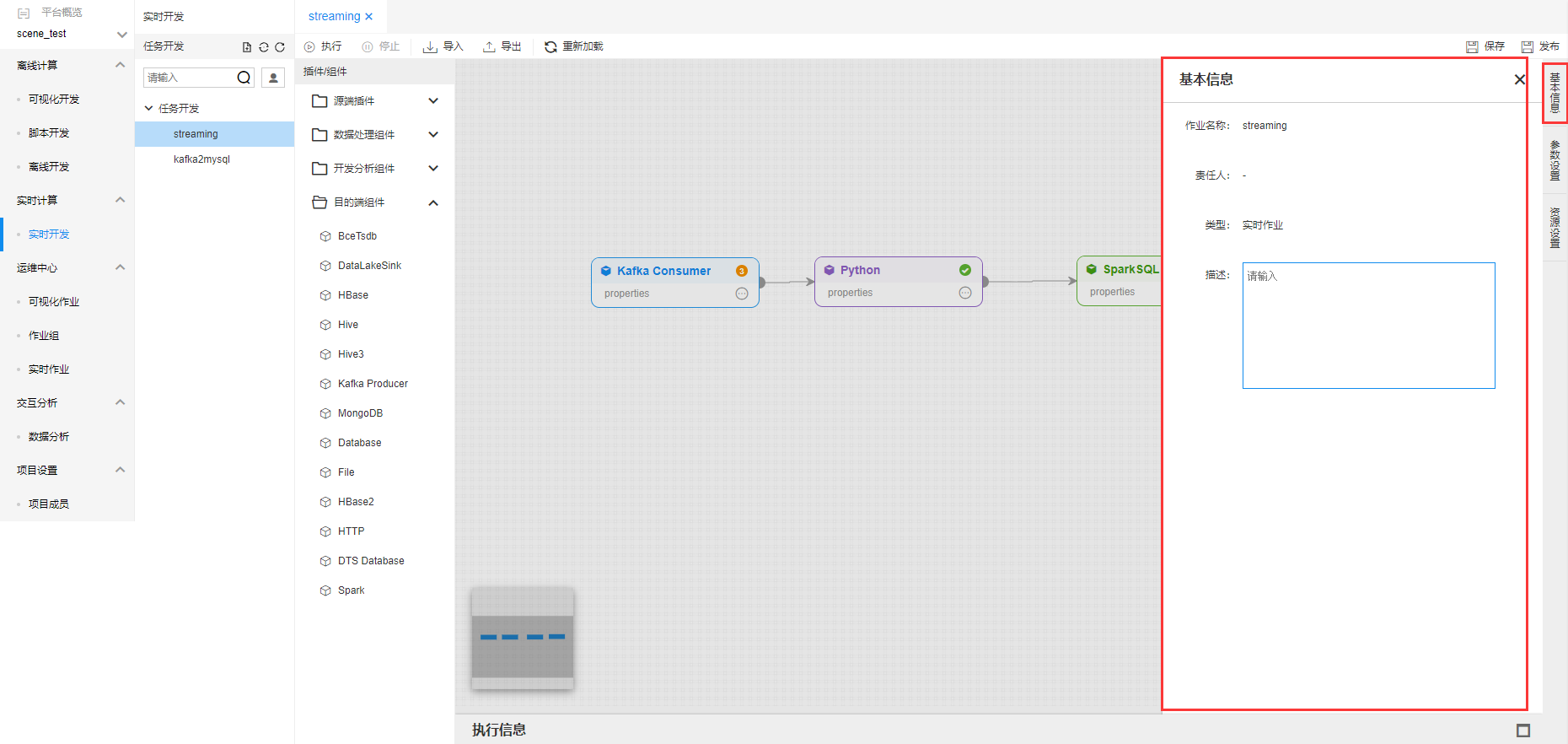
开发完实时作业之后,点击【基本信息】,显示实时作业的基本信息,并能够进行描述修改。
点击【参数设置】,弹出实时作业的参数设置。设置的参数可以在作业中进行引用。
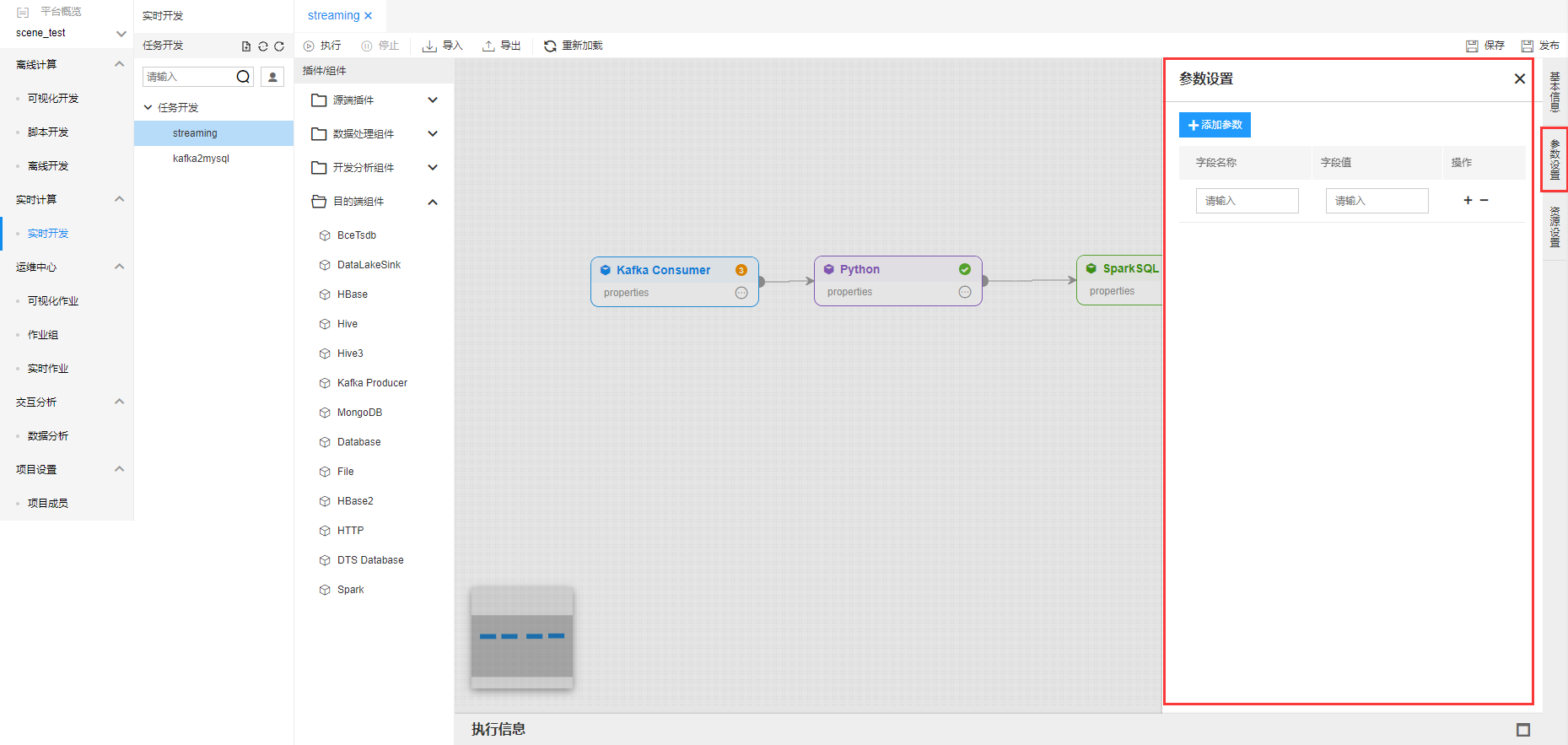
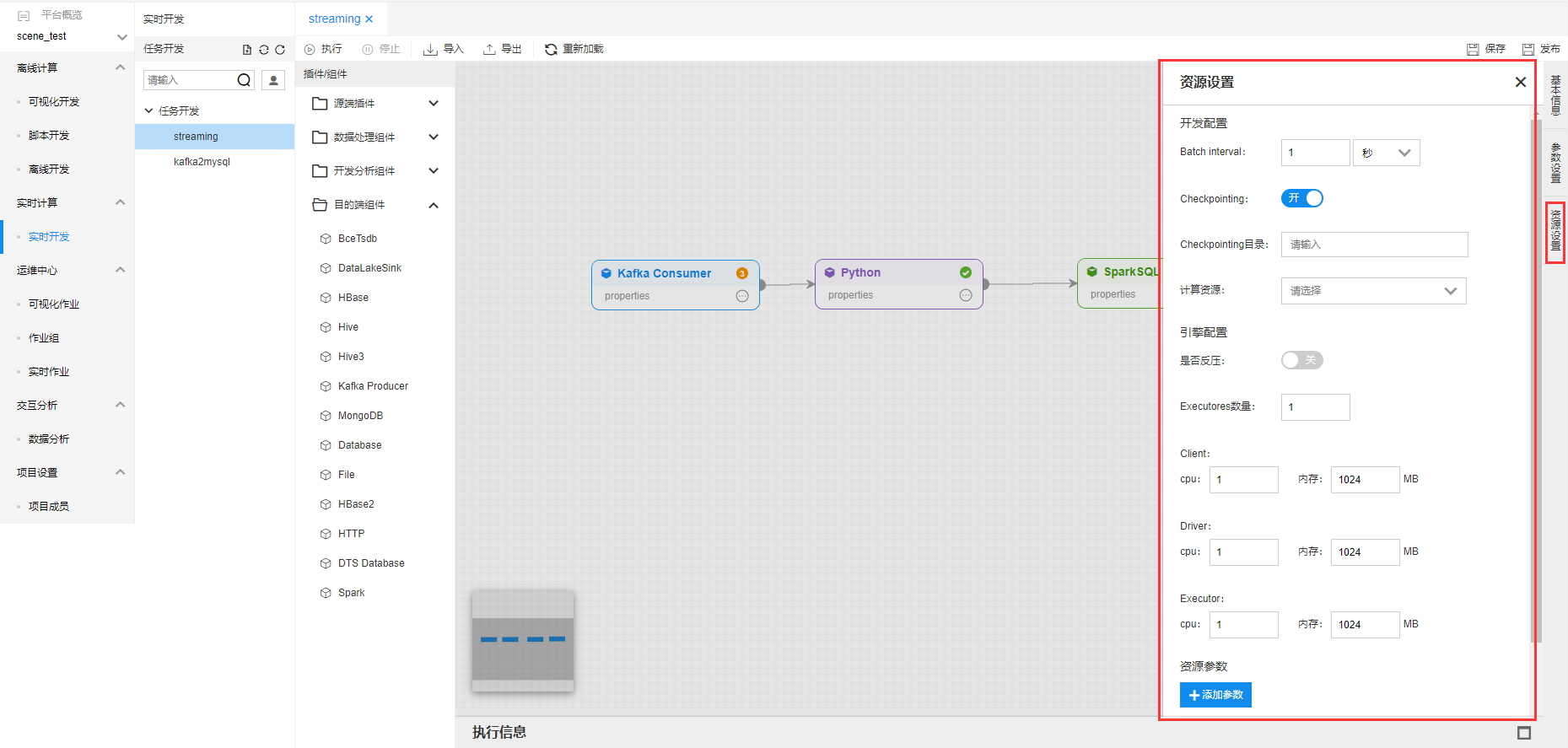
点击【资源设置】弹出作业资源设置框,对实时作业进行资源设置。
实时作业保存及测试运行
开发完实时作业后点击,上面【保存】按钮,进行作业保存。
点击【发布】即将作业发布到运维中心。
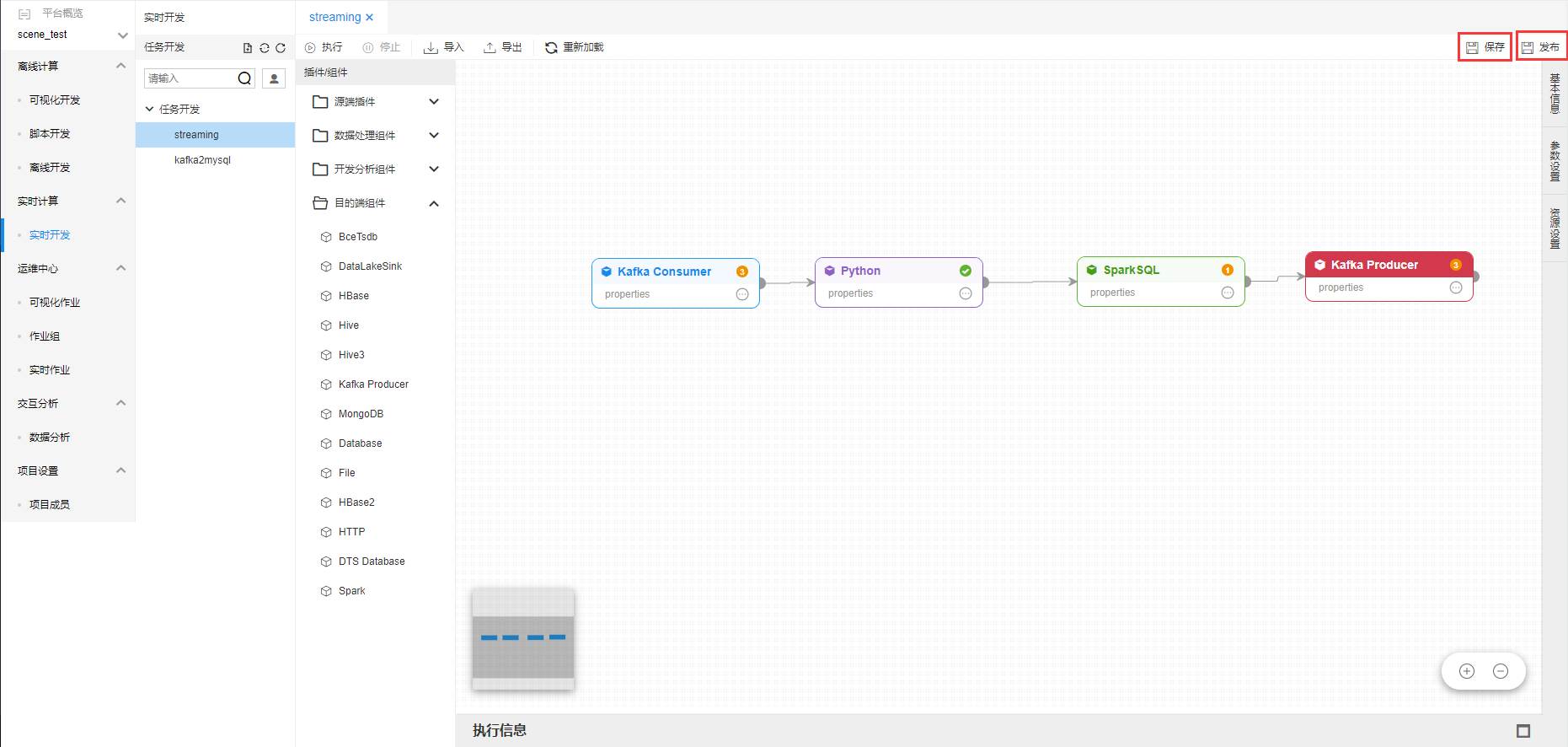
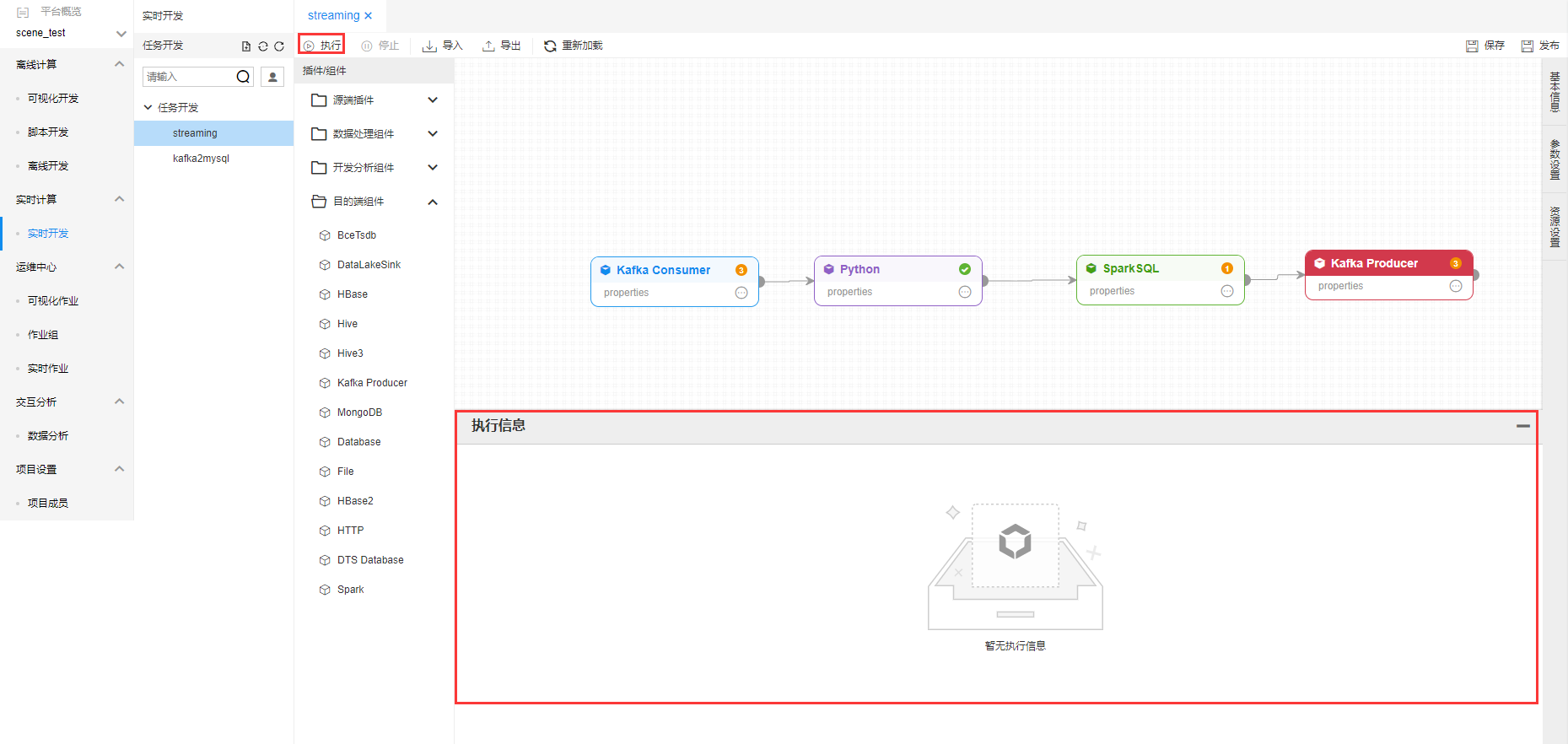
点击【执行】,进行作业测试运行,且在【执行信息】中弹出执行日志信息。