




概述
MapReduce(简称“BMR”)是托管的一站式大数据平台,提供高可靠、高安全性、高性价比、易运维的分布式计算服务,涵盖 Hadoop、Spark、Hive、Flink、Presto、Druid等多种开源组件,并与百度对象存储无缝衔接,助力企业轻松高效地处理海量数据。
MapReduce支持完整的Hadoop生态:
- Hadoop:提供可靠存储HDFS以及MapReduce编程范式以便大规模并行处理数据。
- Spark:提供基于分布式内存的大规模并行处理框架,从而大大提高大数据分析性能。Spark提供了SQL查询接口、流数据处理以及机器学习。
- HBase:大规模分布式NoSQL数据库,提供随机存取大量的非结构化和半结构化的海量数据。
- Kafka:提供托管kafka独立集群模板,支持kafka 1.0.1、1.1.1、2.5.1 多个版本,提供可靠的消息队列服务。
- ClickHouse:是一个开源的列式存储数据库管理系统,多用于联机分析(OLAP)场景,可提供海量数据的存储和分析,同时利用其数据压缩和向量化引擎的特性,能提供快速的数据搜索。
与自己搭建Hadoop集群相比,MapReduce有以下优势:
- 方便:几分钟便可创建集群,无需为节点分配、部署、优化投入时间。
- 弹性:创建任意大小的集群并动态调整集群规模,高峰期加大集群规模以提高计算能力,低峰期可对应缩减集群规模降低花费。
- 开放:完全兼容开源Hadoop/Spark社区,零成本业务迁移。
- 实惠:支持按需付费以及包年包月,计价简单而透明。
- 安全:专属私有网络,独占系统环境,确保数据安全。
MapReduce组件

- MapReduce:用于大规模数据集的分布式并行计算的编程模型,极大地方便了开发者在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。
- Spark:开源的集群计算框架。Spark通过拓展内存计算可在海量数据的迭代式计算和交互式计算中提供远快于Hadoop的运算速度。同时,Spark支持SQL请求、流数据处理、机器学习和图表处理,提高开发者效率。
- HBase:开源的、非关系型、分布式的列式数据库,为Hadoop提供NoSQL功能。
- Hive:允许使用类似于SQL语法进行数据查询,适合数据仓库的分析任务。
- Pig:是一种过程语言,可加载数据、表达转换数据以及存储最终结果,使得日志等半结构化数据变得有意义。
- Hue:为了方便管理Hadoop集群以及执行Hive或者Pig脚本而提供的一系列网页应用。
- Sqoop:用于Hadoop与传统的数据库间的数据导入和导出。
- Kafka:开源的、高吞吐量的分布式消息队列系统,支持Hadoop并行数据加载。
- Zeppelin:Web版的notebook,用于数据分析和可视化,可无缝对接Hive、SparkSQL等。
- ZooKeeper:提供分布式一致性锁,用于HDFS、YARN高可用,在HBase、Kafka、Druid中保证数据一致性。
- Ranger:提供基于策略的用户权限管理服务,BMR中的Ranger支持对HDFS、Hive、HBase、Kafka配置用户权限。
- Impala:为数据分析师提供的开源的OLAP数据分析引擎。Impala和Hive使用相同的元数据。
- Presto:为数据分析师提供的开源的OLAP数据分析引擎。Presto和Hive使用相同的元数据。
- Alluxio:是一个面向基于云的数据分析和人工智能的开源的数据编排技术。 它为数据驱动型应用和存储系统构建了桥梁, 将数据从存储层移动到距离数据驱动型应用更近的位置从而能够更容易被访问。
- Airflow:是一个分布式的流程调度系统,在配置上可以像编程一样的方式去创作工作流,通过DAG定时和管理各种离线Job的调度平台。
高可用架构
Hadoop-3.0.0以及以上集群版本服务部署情况:
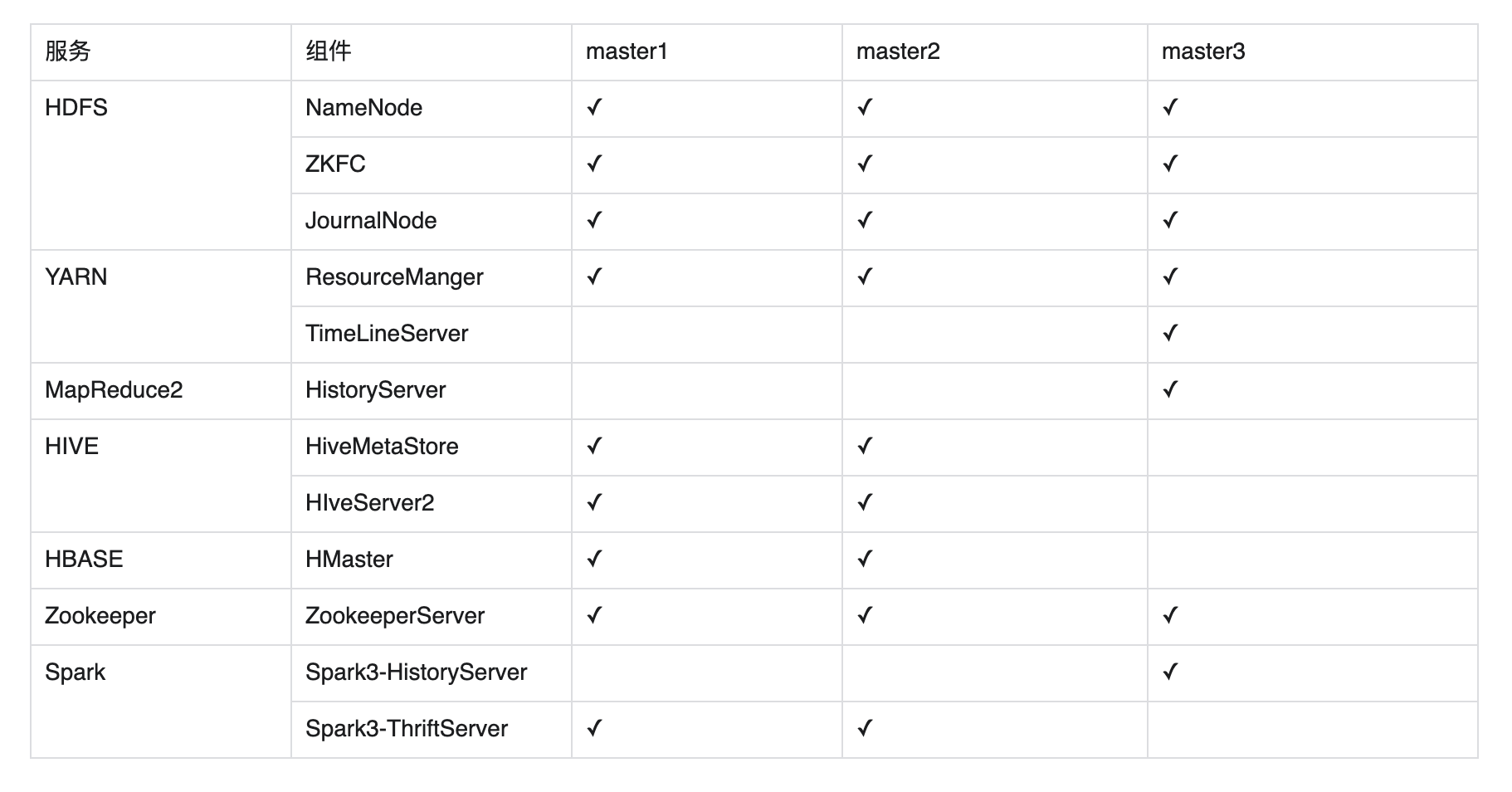
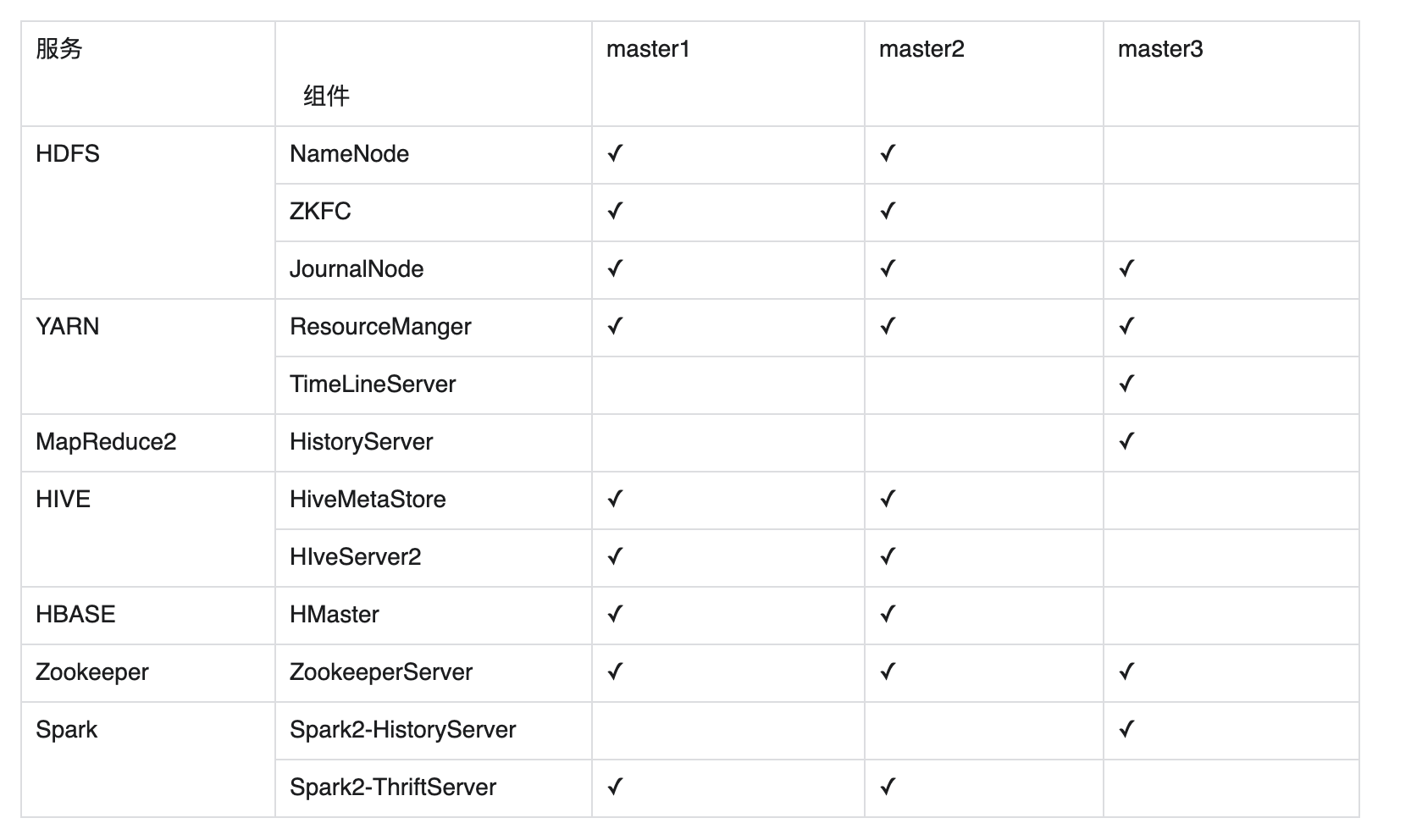
Hadoop-3.0.0以下集群版本服务部署情况:
ClickHouse

