

百度智能云飞桨EasyDL零门槛AI开发平台情感倾向分析 - 创建数据集并导入
文档简介:
在训练模型之前,需要先在数据总览【创建数据集】。只需输入数据集名称、选择数据去重策略,即可创建一个空数据集。
数据自动去重即平台对您上传的数据进行重复样本的去重。建议创建数据集时选择「数据自动去重」。



创建数据集
在训练模型之前,需要先在数据总览【创建数据集】。只需输入数据集名称、选择数据去重策略,即可创建一个空数据集。
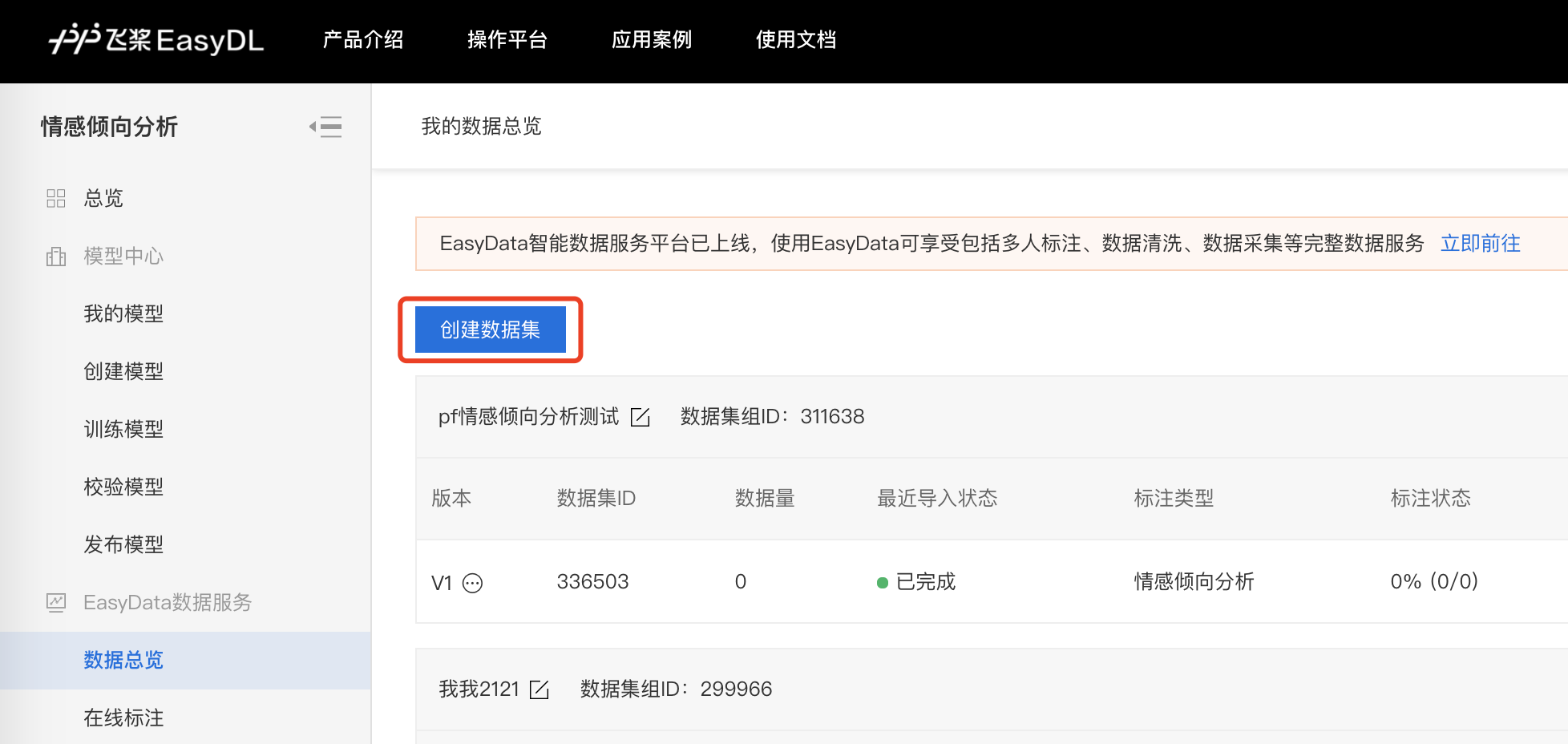
数据自动去重即平台对您上传的数据进行重复样本的去重。建议创建数据集时选择「数据自动去重」
导入数据
创建数据集后,在「数据总览」页面中,找到该数据集,点击右侧操作列下的「导入」,即可进入导入数据页面。
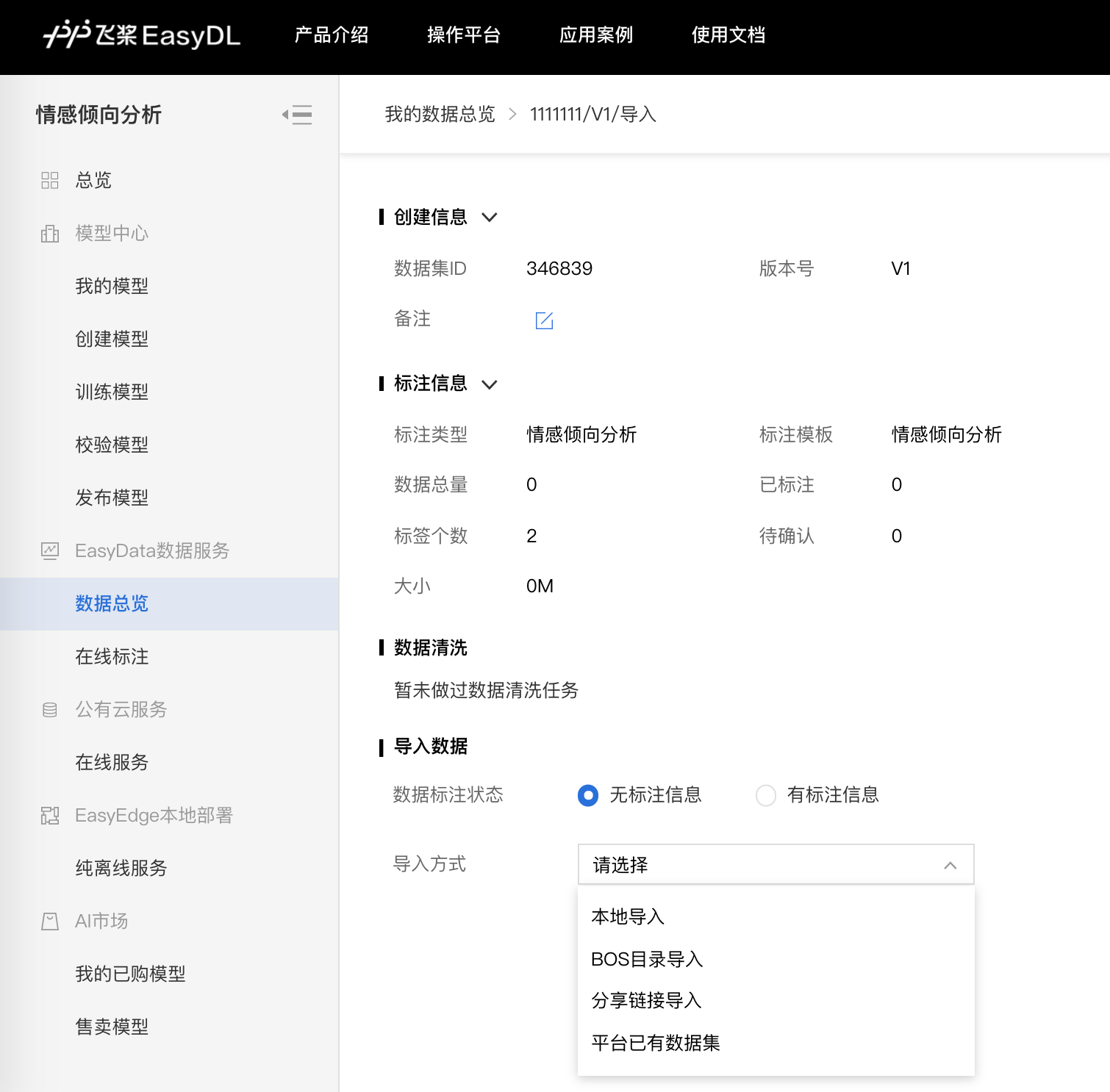
您可以使用4种方案上传情感倾向分析的数据,分别为:
- 本地导入
- BOS目录导入
- 分享链接导入
- 平台已有数据集
不论您上传无标注信息的数据或有标注信息的数据,都需要以下述格式要求进行上传。区别在于上传有标注信息的数据时,需要针对正向文本内容与负向文本内容分别进行上传。每个数据集里面默认包含正向(positive)标签和负向(negative)标签。
本地导入
您可以通过以下三种方式进行本地数据的导入:
- 以压缩包的方式上传
- 以TXT文本文件方式上传
- 以Excel文件的方式上传
以压缩包方式上传
- 一个文本文件保存一个样本,文本文件的编码方式:UTF-8,每个文本文件最长不能超过512个汉字(字符)
- 压缩包仅支持zip格式;大小需要在5GB以内
以TXT文本文件上传
- 一个文本文件包含多个样本,文本文件中每行为一个样本
- 一个文本文件包含一个样本,单次上传限制100个文件,最多可上传100万个文本文件
- 每行样本最长不能超过512个汉字(字符),文件编码方式:UTF-8
以Excel文件上传
- Excel文件上传数据格式为每行是一个样本,每个数据文本内容的字符数建议不超过512个,超出将被截断
- 文件类型支持xlsx格式,单次上传限制100个文件
- 需确保上传的样本在sheet1中,且数据都在首列
BOS目录导入
需选择Bucket地址与对应的文件夹地址。
请确保将全部文本已通过txt文件保存至同一层文件目录,该层目录下子文件目录及非相关内容(包括压缩包格式等)不导入。
分享链接导入
需输入链接地址。分享链接导入的要求如下:
- 仅支持来自百度BOS、阿里OSS、腾讯COS、华为OBS的共享链接
平台已有数据集
- 导入无标注数据时,选择需要导入的数据集名称,可导入其不带标注的全部数据,或未标注的数据
- 导入已标注数据时,选择需要导入的数据集名称,可导入其某个或全部标签下的数据
准备数据集的技巧
情感倾向分析任务中,可参考以下准备数据集的技巧:
设计分类
情感倾向分析的数据集,默认只使用正向和负向两种标签的数据,所以数据集中无需创建标签,您只需准备对应情感倾向的标签数据即可。
数据量
每个标签建议至少需要准备50个以上的样本,如果想要较好的效果,建议准备1000-10000个文本样本,如果某些分类的文本具有相似性,需要增加更多文本。
数据分布
- 训练集文本需要和实际场景要识别的文本内容的业务范围一致,且标签对应文本的数量分布一致。如训练集的业务范围是图书商品的情感倾向分析,而预计线上对应的场景或业务是电子产品的情感倾向分析,此时两者不一致,将会导致模型实际应用效果不佳
- 考虑实际应用场景有多种可能性,每个场景都需要准备相对应的训练数据,训练集若能覆盖的场景越多,模型的泛化能力则越强
- 建议对高频的业务场景尽量做到覆盖,并通过线上bad case来进行训练数据的优化
如果需要寻求第三方数据采集团队协助数据采集,请在百度云控制台内提交工单反馈
