

文档简介:



简介
Linux GPU加速版SDK是适用于EasyDL经典版、EasyDL专业版模型快速部署的工具包。SDK中包含了EasyDL训练的模型资源文件、SDK和demo文件。
测试前的准备
-
Linux x86 GPU的硬件及开发环境
- 详情参考下方文档
-
EasyDL平台的Linux x86 GPU 加速版服务器端SDK&激活序列号
- 以经典版图像分类为例,在操作台训练「私有服务器部署-服务器端SDK」下的模型后,前往控制台申请发布Linux x86 GPU的服务器端SDK,发布成功后即可同时获得加速版SDK和序列号
- 首次使用SDK或者更换序列号、更换设备时,需要联网激活。激活成功之后,有效期内可离线使用
安装依赖
在使用SDK之前,首先要确认自己的硬件类型和相应的依赖库安装是否已经符合要求。
硬件要求:
- Linux GPU加速版SDK支持绝大部分Nvidia显卡。
软件要求:
- gcc 5.4+(需包含GLIBCXX_3.4.22)
- cmake 3+
- CUDA 9.0 + cuDNN 7.5 或 CUDA 10.0 + cuDNN 7.5
- TensorRT 7.0
- OpenCV 3.4
其他要求:
- 第一次使用SDK请确保联网
SDK结构
获取到的SDK解压后的目录结构是:
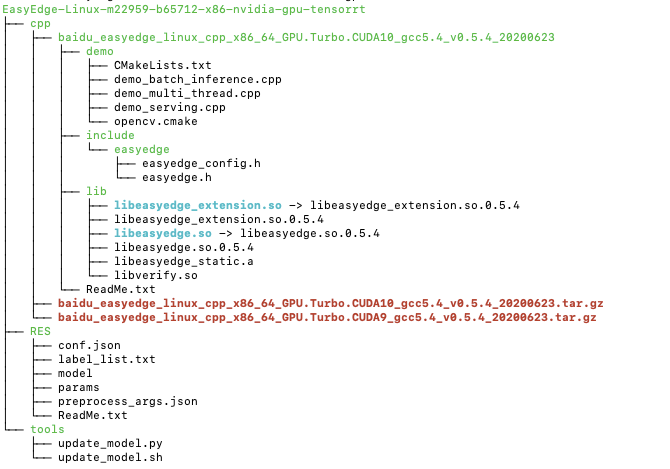
其中:
- cpp文件夹下有两个压缩包分别为适配不同版本CUDA的SDK,解压缩后得到include头文件、lib库文件和demo示例代码文件。
- RES文件夹下是EasyDL训练得到的模型资源文件。
- tools文件夹下提供的是模型更新工具,用在迭代训练模型后,直接拉取新训练的模型,而不用重新下载SDK。
编译demo
解压SDK后,进入到demo目录可以直接编译demo。编译方法如下:
# 1. 首先进入demo目录 # 2. 创建build文件夹并进入 $ mkdir build
&& cd build # 3. 执行编译 $
cmake .. $ make -j3 # 4. 执行安装,把lib文件安装到系统路径,
需要sudo权限;也可以选择不执行安装,把lib路径加为环境变量即可
$ sudo make install # 5. 这时候应该会产出demo编译的可执行文件,
直接执行可以查看需要的参数 $ ./easyedge_batch_inference {res_dir}
{image/image_dir} # 或 $ ./easyedge_multi_thread {res_dir}
{image/image_dir} # 或 $ ./easyedge_serving {res_dir} {serial_key}
{host, default 0.0.0.0} {port, default 24401}
编译产出有三个可执行文件,分别为:
- easyedge_batch_inference:提供了对批量图片预测的能力,预测速度快, 是最推荐使用的方式。
- easyedge_multi_thread:提供了对多卡或多线程预测的支持。其中多线程的支持是针对一张显卡而言的,这种方式通常并不推荐使用,因为计算资源的相互竞争会拉慢单次预测的速度并且预测时间不稳定。
- easyedge_serving:提供了http服务的能力。启动服务后,可以轻松把http服务接口集成到自己的应用中。
其中前两个demo示例了SDK API的集成方式,第三个demo示例了如何使用SDK创建http服务。根据个人需求选择不同集成方式即可,接下来将分别介绍这两种集成方式。
API集成
使用SDK的API接口方式能提供功能更丰富、预测速度更快的能力。API接口的设计尽可能的降低了调用复杂度,可以很方便的集成到自己的应用当中。
调用流程
// 1. 设置序列号 global_controller()->set_licence_key("ABCD-ABCD-ABCD-ABCD");
// 2. 配置运行选项 TensorRTConfig config; config.model_dir = argv[1];
config.device = 0; // 设置需要使用的GPU config.max_batch_size = 4;
// 优化的模型可以支持的最大batch_size,实际单次推理的图片数不能大于此值
config.max_concurrency = 1; // 设置device对应的卡可以使用的最大线程数
config.fp16 = false; // 置true开启fp16模式推理会更快,精度会略微降低
,但取决于硬件是否支持fp16,不是所有模型都支持fp16,参阅文档 //
3.创建predictor并初始化 auto predictor = global_controller()
->CreateEdgePredictor(config); predictor->init(); //
4. 执行预测 predictor->infer(imgs, result);
当机器上存在多张显卡时,可以创建多个predictor,每一个predictor通过config配置不同的显卡id,这样就可以同时在不同的显卡上执行预测。具体使用方式可以参考demo_multi_thread.cpp的示例代码。这里贴出:
// 配置要使用的显卡id std::vector<int> devices{0, 1, 2, 3};
// 每个predictor对应一张显卡 std::vector<std::unique_ptr<EdgePredictor>>
predictors; // 配置运行选项 TensorRTConfig config; config.model_dir = model_dir;
config.max_batch_size = 8; // 单次预测可以支持的最大batch_size,
多个predictor的此值要保持一致 config.max_concurrency = 1;
// 单个device上的最大infer并发量,建议保持为1 config.compile_level
= 1; // 编译模型的策略,如果当前设置的max_batch_size与历史编译存储的不同,
则重新编译模型 config.fp16 = false; // 置true开启fp16模式推理会更快,
精度会略微降低,但取决于硬件是否支持fp16,且不是所有模型都支持fp16,
参阅开发文档 // for(int i = 0; i < predictors.size(); ++i)
{ config.device = devices[i]; // 设置GPU id // 创建predictor
auto predictor = global_controller()->CreateEdgePredictor<TensorRTConfig>(config);
if (predictor->init() != EDGE_OK) { exit(-1);
} predictors.emplace_back(std::move(predictor)); }
// 创建与predictor数量等同线程数的infer_task std::vector<std::thread>
threads; std::map<int /*predictor index*/, std::vector<std:
:vector<EdgeResultData>>> results; for (int i = 0; i
< predictors.size(); ++i) { assert(split_img_files[i].size()
<= config.max_batch_size); // infer_task的实现详见demo_multi_thread.cpp,
主要功能为执行infer预测 threads.emplace_back(std::thread(infer_task,
std::ref(predictors[i]), std::ref(split_img_files[i]), std::ref(results),
i)); } for (auto& t : threads) { if (t.joinable()) { t.join(); } }
通过创建多个predictor可以将同一个模型同时部署到多张显卡上,这样可以提升执行预测的吞吐率。当然也可以在不同的显卡上部署不同的模型,通过在config中指定不同的model_dir即可。
可以看到,调用SDK的API流程很简单,并可以通过config的不同配置实现不同的能力。比如支持批量图片预测、多卡部署、多线程预测、fp16加速等。实际集成的过程中,最需要注意的就是config的配置,一个适合自己应用场景的config参数配置才能带来最佳的预测速度。
参数配置
config的定义可以参见头文件easyedge.h
struct TensorRTConfig : public EdgePredictorConfig
{ std::string model_filename{"model"}; std::string params_
filename{"params"}; std::string cache_name{"m_cache"}; /** * @brief GPU工作空间大小设置 * workspace_size = workspace_prefix * (1 << workspace_offset) * workspace_offset: 10 = KB, 20 = MB, 30 = GB */ int workspace_prefix{16}; int workspace_offset{20}; /** * @brief 生成最大 batch_size 为 max_batch_size 的优化模型,
单次预测图片数量可以小于或等于此值 */ int max_batch_size{1}; /** * @brief 设置使用哪张 GPU 卡 */ int device{0}; /** * @brief 模型编译等级 * 0:无论当前设置的max_batch_size是多少,仅使用历史编译产出(如果存在) * 1:如果当前max_batch_size与历史编译产出的max_batch_size不相等时,
则重新编译模型(推荐) * 2:无论历史编译产出的max_batch_size为多少,均根据当前max_batch_size重新编译模型 */ int compile_level{1}; /** * @brief 设置device对应的卡可以支持的最大并发量 * 实际预测的时候对应卡的最大并发量不超过这里设置的范围 */ int max_concurrency{1}; /** * @brief 是否开启fp16模式预测,需要硬件支持 */ bool fp16{false}; /** * @brief 设置需要使用的DLA Core */ int dla_core{-1}; }
cache_name:GPU加速版SDK首次加载模型会先对模型进行编译优化,通过此值可以设置优化后的产出文件名。比如,可以根据不同的配置来命名产出文件,从而可以在之后的运行中直接通过文件名就可以索引到编译产出,而不用再次执行优化过程。
workspace_size:设置运行时可以被用来使用的最大临时显存。通常默认即可,但当执行预测失败时,可以适当调大此值。
max_batch_size:此值用来控制批量图片预测可以支持的最大图片数,实际预测的时候单次预测图片数不可大于此值,但可以是不大于此值的任意图片数。建议设置为与实际需要批量预测的图片数量保持一致,以节省内存资源并可获得较高预测速度。
device:设置需要使用的 GPU 卡号。
compile_level:模型编译等级。通常模型的编译会比较慢,但编译产出是可以复用的。可以在第一次加载模型的时候设置合理的 max_batch_size 并在之后加载模型的时候直接使用历史编译产出。是否使用历史编译产出可以通过此值 compile_level 来控制,当此值为 0 时,表示忽略当前设置的 max_batch_size 而仅使用历史产出(无历史产出时则编译模型);当此值为 1 时,会比较历史产出和当前设置的 max_batch_size 是否相等,如不等,则重新编译;当此值为 2 时,无论如何都会重新编译模型。
max_concurrency:通过此值设置单张 GPU 卡上可以支持的最大 infer 并发量,其上限取决于硬件限制。init 接口会根据此值预分配 GPU 资源,建议结合实际使用控制此值,使用多少则设置多少。注意:此值的增加会降低单次 infer 的速度且预测速度不稳定,建议优先考虑 batch inference。
fp16:默认是 fp32 模式,置 true 可以开启 fp16 模式预测,预测速度会有所提升,但精度也会略微下降,权衡使用。注意:不是所有模型都支持 fp16 模式,也不是所有硬件都支持 fp16 模式。已知不支持fp16的模型包括:EasyDL经典版图像分类高精度模型。
运行demo
命令执行格式:
./easyedge_batch_inference {模型RES文件夹} {测试图片路径或图片文件夹路径}
./easyedge_multi_thread {模型RES文件夹} {测试图片路径或图片文件夹路径}
如:

预测效果展示:

Http服务集成
使用SDK的http服务API可以创建一个http服务端口,从而可以在应用里或者网页中通过http请求的方式执行模型的预测并获取预测结果。
调用流程
// 1. 设置序列号 global_controller()->set_licence_key("ABCD-ABCD-ABCD-ABCD"); //
2. 配置运行选项 TensorRTConfig config; config.device = 0; config.model_dir = model_dir; //
3. 启动服务 return global_controller()->start_http_server(config, host, port, service_id, 1);
编译并运行后就会在控制台启动一个服务,默认地址为:http://{设备ip}:24401,通过在浏览器访问此地址可以打开一个测试页面,上传图片即可获取识别结果。
运行demo
demo命令执行格式
./easyedge_serving {res_dir} {serial_key} {host, default 0.0.0.0} {port, default 24401}
如:

当出现提示:HTTP is now serving at 0.0.0.0:24401, holding 1 instances 时,表示服务已经启动成功,这时候可以在浏览器里输入地址打开一个测试页面。如下所示:
上传图片,可以看到预测效果:
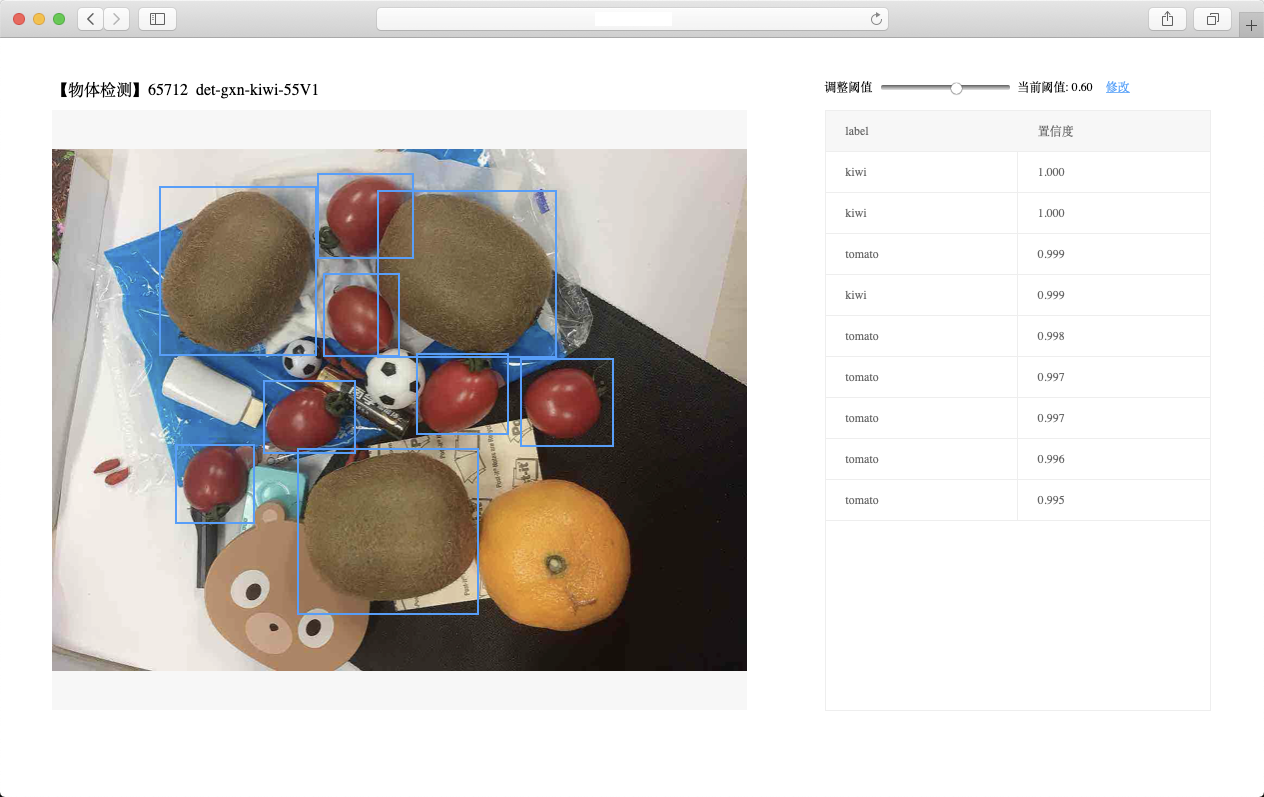
也可以通过在自己的项目中请求此地址做预测,并获取预测结果。URL中的get参数:
| 参数 | 说明 | 默认值 |
|---|---|---|
| threshold | 阈值过滤, 0~1 | 如不提供,则会使用模型的推荐阈值 |
HTTP POST Body即为图片的二进制内容(无需base64, 无需json)
如使用Python的请求示例:
import requests with open('./1.jpg', 'rb') as f: img = f.read() result = requests.post
( 'http://127.0.0.1:24401/', params={'threshold': 0.1}, data=img).json()
http请求的返回格式为:
| 字段 | 类型说明 | 其他 |
|---|---|---|
| error_code | Number | 0为成功,非0参考message获得具体错误信息 |
| results | Array | 内容为具体的识别结果。其中字段的具体含义请参考开发文档 |
| cost_ms | Number | 预测耗时ms,不含网络交互时间 |
