




您可以新建一个 Pytorch 类型的任务。
前提条件
- 您已成功安装 CCE AI Job Scheduler 和 CCE Deep Learning Frameworks Operator 组件,否则云原生 AI 功能将无法使用。
- 若您是子用户,队列关联的用户中有您才能使用该队列新建任务。
- 安装组件 CCE Deep Learning Frameworks Operator 时,系统安装了 Pytorch 深度学习框架。
操作步骤
- 登录百度智能云官网,并进入管理控制台。
- 选择“产品服务 > 云原生 > 容器引擎 CCE”,单击进入容器引擎管理控制台。
- 单击左侧导航栏中的 集群管理 > 集群列表 。
- 在集群列表页面中,单击目标集群名称进入集群管理页面。
- 在集群管理页面单击 云原生AI > 任务管理 。
- 在任务管理页面单击 新建任务 。
- 在新建任务页面中,完成任务基本信息配置:
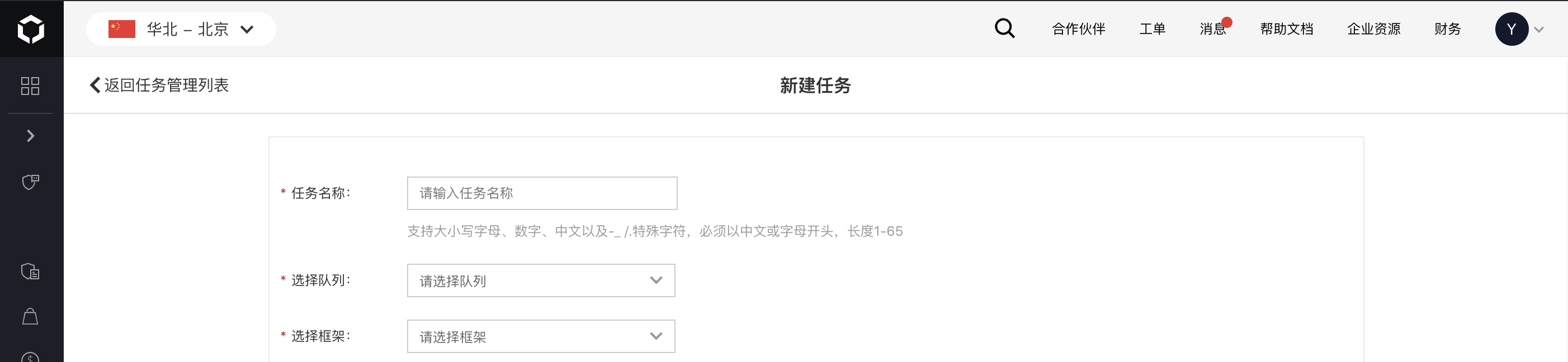
- 任务名称:自定义任务名称,支持大小写字母、数字、以及-_ /.特殊字符,必须以中文或字母开头,长度 1-65。
- 队列:选择新建任务关联的队列。
- 框架:选择任务对应的深度学习框架“Pytorch”。
- 参考 yaml 模板完成配置:
apiVersion: "kubeflow.org/v1"
kind: "PyTorchJob"
metadata:
name: "pytorch-dist-mnist-gloo"
spec:
pytorchReplicaSpecs:
Master:
replicas: 1
restartPolicy: OnFailure
template:
metadata:
annotations:
sidecar.istio.io/inject: "false"
# if your libcuda.so.1 is in custom path, set the correct path with the following annotation
# kubernetes.io/baidu-cgpu.nvidia-driver-lib: /usr/lib64
spec:
schedulerName: volcano
containers:
- name: pytorch
image: registry.baidubce.com/cce-public/kubeflow/pytorch-dist-mnist-test-with-data:1.0
args: ["--backend", "gloo"]
# Comment out the below resources to use the CPU.
resources:
requests:
cpu: 1
memory: 1Gi
limits:
baidu.com/v100_32g_cgpu: "1"
# for gpu core/memory isolation
baidu.com/v100_32g_cgpu_core: 10
baidu.com/v100_32g_cgpu_memory: "2"
# if gpu core isolation is enabled, set the following preStop hook for graceful shutdown.
# `mnist.py` needs to be replaced with the name of your gpu process.
lifecycle:
preStop:
exec:
command: ["/bin/sh", "-c", "kill -10 `ps -ef | grep mnist.py | grep -v grep
| awk '{print $2}'` && sleep 1"]
Worker:
replicas: 1
restartPolicy: OnFailure
template:
metadata:
annotations:
sidecar.istio.io/inject: "false"
spec:
schedulerName: volcano
containers:
- name: pytorch
image: registry.baidubce.com/cce-public/kubeflow/pytorch-dist-mnist-test-with-data:1.0
args: ["--backend", "gloo"]
resources:
requests:
cpu: 1
memory: 1Gi
limits:
baidu.com/v100_32g_cgpu: "1"
# for gpu core/memory isolation
baidu.com/v100_32g_cgpu_core: 20
baidu.com/v100_32g_cgpu_memory: "4"
# if gpu core isolation is enabled, set the following preStop hook for graceful shutdown.
# `mnist.py` needs to be replaced with the name of your gpu process.
lifecycle:
preStop:
exec:
command: ["/bin/sh", "-c", "kill -10 `ps -ef | grep mnist.py | grep -v grep
| awk '{print $2}'` && sleep 1"]
- 点击“确定”按钮,完成任务的新建。
