

文档简介:



概述
在数据库的使用过程中,如果遇到误操作导致的数据删除、数据篡改等问题,可以通过RDS克隆实例功能实现数据修复。克隆实例的数据恢复方式分为如下两种:
- 按时间点恢复:将数据恢复到指定时间点的数据快照(精确到秒),适合误操作后的数据恢复场景,恢复过程包含全量恢复和增量恢复
- 按备份集恢复:将数据恢复到指定备份集的数据快照,适合业务压测和集群拆分扩展等需求,恢复过程仅进行全量恢复
使用说明
前置条件
- RDS实例运行状态正常
- 主实例备份状态正常、备份集正常
注意事项
- 克隆实例的创建过程需要先下载备份数据和增量binlog日志,然后进行全量数据恢复和增量数据恢复,因此数据量越大、写入并发越高则创建克隆实例的耗时越长
- 克隆实例的数据是所选时间点的静态快照,不包含克隆实例所选时间点之后新写入的增量数据
- 克隆实例创建成功后,需要导出克隆实例中待恢复表的数据,并与线上数据进行比对校验,提取需要恢复的数据内容,然后谨慎操作恢复数据到线上生产环境
- 常见的数据恢复过程举例:
| 时间点 | 操作日志 |
|---|---|
| 09:18 | 误操作删除了部分数据 |
| 10:10 | 感知到数据异常问题 |
| 10:15 | 操作RDS克隆实例功能,恢复的时间点指定到09:18 |
| 12:10 | 克隆实例恢复完成(注意:克隆实例中不包含09:18后新写入的数据) |
| 12:30 | 经过数据比对和校验,将误操作涉及到的部分数据恢复到线上 |
使用克隆实例功能恢复数据案例
-
确定克隆实例的操作目标(恢复范围)
因在09:18:02的时候,做了一个误操作, 误将表t_order的字段status=0的数据误删除,需要恢复t_order表数据到09:18:02时刻的快照,使用克隆实例的按时间点恢复功能,选择还原时间点:2019-07-02 09:18:02
-
选择按照时间点克隆实例(已经确认有成功的历史备份)
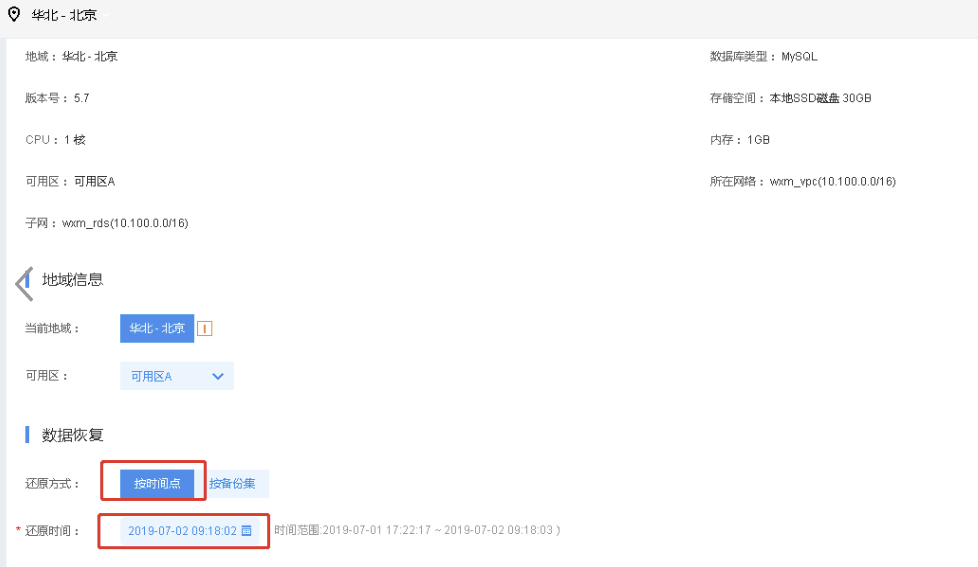
- 克隆实例完成后,检查克隆实例上的数据是否符合预期
-
确认恢复出来的数据快照符合预期后,将数据恢复到线上,为了不直接替换线上表,先将克隆实例的t_order表改名
rename table t_order to t_order_bk_091802;
-
从克隆实例导出数据,并且导入到线上实例,示例如下:
主库ip:10.100.0.7 克隆实例ip:10.100.0.14 #在bcc上开启screen,避免大表导出导入过程中session中断 screen -S mysql_importdata #设置linux session时间,避免导出后linux进程因为闲置退出 export TMOUT=0 #数据导出并通过管道同时导入 # --set-gtid-purged=OFF 导出的数据时,不导出gtid,避免导入时,从库因为gtid已经执行而跳过,导致恢复的数据只在主库存在 # --skip-lock-tables 不加锁,避免锁住线上表 # --quick 避免导出的数据写入缓存,影响线上服务 # --hex-blob 将blob数据转为16进制,避免导入后数据不一致 # --single-transaction 通过单一事务保证数据一致 # --tz-utc=0 执行utf时区,保证时间数据一致 mysqldump -h 10.100.0.14 -uxx -ppassword --set-gtid-purged=OFF --skip-lock-tables --quick --hex-blob
-
--single-transaction --tz-utc=0 baidu_dba t_order_bk_091802 | mysql -h 10.100.0.7 -uXXX -pXXX dba_baidu baidu_dba
-
数据校验
查询新表和克隆实例恢复出来的表之间的数据差异,判断恢复后需要补入哪些数据。具体校验方法可根据客户业务需要校验(比如可以将数据导出到文件,通过文件进行diff)
如本例,通过校验,发现id在1~172631范围的数据误删除,需要恢复
-
补入原表的新数据
#将原表数据补入新的线上表 begin; insert into t_order(data,status) select data,status from t_order_bk_091802 where id>=1 and id <=172631
-
; #补入后再检查 select status, count(1),min(id),max(id) from t_order where id>=1 and id <=172631 ; #符合预期,提交事务 commit;
常见问题和解决办法
-
bcc上使用mysqldump导出报错: 比如: mysqldump: unknown variable 'set-gtid-purged=OFF'
原因:排除掉选项字母写错,密码写错等原因,主要的问题就是使用mysqldump版本太低,需要升级,例如:
mysqldump --version mysqldump Ver 10.13 Distrib 5.1.73, for redhat-linux-gnu (x86_64) #这是默认的版本太低,需要升级
解决: 下载最新版的mysql到bcc上编译安装,或者从其他曾经安装过高版本mysql的bcc上复制一份 mysqldump 和mysql文件.
-
导出命令报错: ./mysqldump: Permission denied
原因:一般是 mysqldump没有执行权限.授权执行即可
解决:chmod a+x mysqldump
-
数据校验如何做
解决: 若已知的误操作的sql,可以将误操作的sql,改写为查询sql,然后对比数据;或者将数据查询出来输出到文本文件,然后进行文本比对
