




1)地址冲突
在启动broker时,出现“地址已在使用”,如:
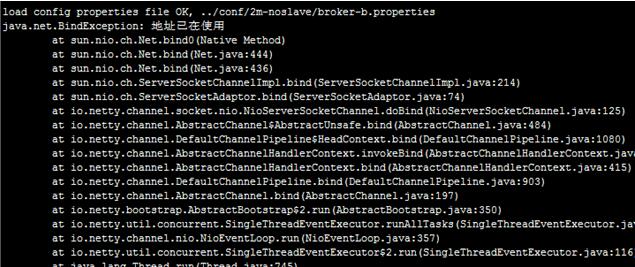
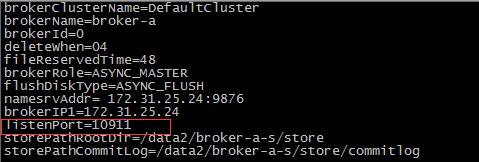
解决方案:修改配置文件里面的listenPort的值,然后重新启动。

2)brokerName不匹配
启动出现异常:broker-b does not match the expected group name: broker-a
原因:启动其他Master broker服务时,直接将之前使用过的store目录以及bdb目录复制过来,仅仅只是修改了brokerName,导致此问题出现。
解决方案:2.0以后版本brokerName一旦创建启动后就不能改变,否则只能删除store目录才能解决。
3)service not available
现象:发送消息一定量的时候,出现 create maped file failed, please make sure OS and JDK both 64bit。或者当topic的队列数位1024个的时候,会出现service not available now, maybe disk full,maybe your broker machine memory too small。
解决:使用ulimit-a命令查询系统参数,检查open files是否超过655350,max memory size是为否unlimited,若不是,需要重新根据安装手册的步骤,重新调整系统参数。

4)磁盘空间不足
当磁盘空间大于85%时,会出现“ CODE: 14 DESC: service not available now, maybe disk full, CL: 0.87 CQ: 0.87 INDEX: 0.87, maybe your broker machine memory too small.”的异常。
处理办法:
消息中间件有两种策略, 包括数据高安全性与服务高可靠性,分别如下
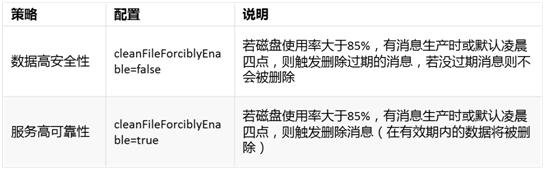
若磁盘使用率大于85%,策略为数据高安全性,且无过期文件,可以按实际需求,减少数据保存时间来触发消息删除,腾出磁盘空间
1. 使用updateBrokerConfig命令,修改fileReservedTime属性,此属性为消息保存时间,单位为小时。按需减少保存时间,则可以腾出磁盘空间。
2. 主备都需要同时修改
消息过期时间的配置可以参考文档RocketMQ配置文件详细说明.docx,fileReservedTime配置
5)通过deamon拉起broker时报错
deamon.log日志中报Fail to queryBrokerMaxOffset
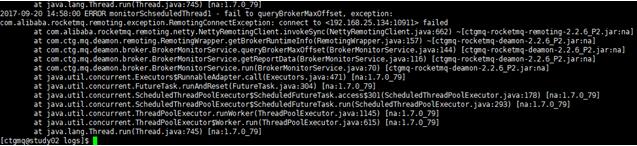
原因:
1. 配置文件错误。
2. 做过主备切换,然后手动干预或重启集群,启动进程的地址和角色与zookeeper中存储的不同,造成启动失败。
3. 上次启动失败后未清理错误数据
解决方法:
1. 删除zk中该集群的信息
2. 核对配置文件,确保端口和路径有效
3. 删除running目录
4. 重新通过自动部署或者手动部署启动进程
6)消费进度停滞不前
现象:通过consumerProgress命令查询消费进度某些队列无变化,而客户端正在正常消费
原因:某些队列有消息没有签收,导致服务端消费进度没有后移。
解决:
通过consumerProgress命令显示的consumer offset找到对应消息
1. 如果是BDB消费模式,重启应用即可或者通过以下api
void com.ctg.mq.api.IMQAckHandler.ackMessageSuccess(String msgID)签收卡住的消息即可。
2. 如果是原生有序消费模式,重启应用即可。
3. 如果是原生无序消费模式,启动一个同消费组的实例,会将该消息签收。
7)删除topic失败
现象:删除topic时出现topic **** is consuming by consumer ****,或者topic *** is publishing by producer ***异常
原因:删除topic必须没有生产者和消费者正在订阅该topic(与该topic相关的生产者消费者都必须离线),否则会失败。
解决:
可以通过一下方式查看是否还有客户端连接该topic:
管理平台->主题管理->详情->生产组|消费组->连接实例
如果使用命令行删除有序队列,需要使用集群删除,例如:
sh mqadmin deleteTopic -n 10.142.90.33:9876 -c mq_cluster -t mytesttopic
如果使用命令行删除无序队列,可以使用broker删除,例如:
sh mqadmin deleteTopic -n 10.142.90.33:9876 -b 10.142.90.33:10911 -t mytesttopic
8)启动broker时BDB报错
现象:启动broker时,报下面的错误
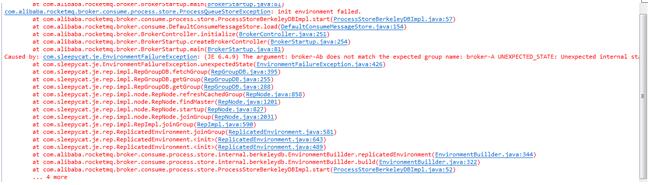
原因:可能是迁移了store目录或者更换了broker的组名、地址或端口。
解决:删除store目录下的consumeStore目录,重启broker即可解决。
9) 从broker已启动,但clusterList看不到
现象:从broker已启动,但无法加入到集群(clusterList查询不到)
原因:
(1)查看/etc/hosts文件,机器名与IP的映射关系是否填写有误
(2)查看防火墙设置(是否有端口未开放),listenPort 到 listenPort+2的端口都需要开放(如果主broker的listenPort=10911,那么10911、10912、10913都要开放)
10) 通过命令行创建有序topic,但是web管理台显示的是无序的
现象:通过updateTopic命令,加-o true创建有序topic,但是web端查询的时候显示是无序的。
原因:集群有多个namesrv,但是创建的时候只填了一个namesrv。
解决:
创建时加上这个broker集群的所有namesrv,中间用分号分割,例如:
sh mqadmin updateTopic -n “10.142.90.30:9876;10.142.90.28:9876” -t crmTopic -o true
11)消费者订阅关系不存在
现象:broker.log日志报错,the consumer's subscription not exist, group: consumerAepIdealLogGroup

原因:使用同个订阅组,同时消费不同的topic,订阅关系会被覆盖。
解决:不能使用同个订阅组的消费组去订阅不同的topic,如果需要变换订阅关系,请关闭旧消费者。
12)使用clusterList查询 主TPS不为0,从TPS一直为0
这种情况最大的可能是从同步出错,可以做进一步的确认,查看store.log或者stoererror.log,一般会看到有持续的报错信息。这种情况可以删除从的store目录,重新进行同步。
前提:部署有高可用模块或者主的brokerRole=ASYNC_MASTER,否则停止从的时候,生产会报错。
操作步骤:
1.手工停止从broker(kill pid,注意不要加-9,如果自动拉起broker参数设置为true,则需要先关掉从的deamon)
2.删除或者备份从的store目录(为保险起见,空间允许的话,可以mv备份,不要直接删除)
3.手工启动broker(sh sh/broker_*.sh)
4.从broker启动完成后,用clusterList查看,可以看到从的TPS比较高,因为正在同步
13)主broker异常恢复
需要走异常恢复流程的一般是consumequeue生成有问题,导致无法拉取消息(注意有多种情况会导致无法拉取消息,不一定是consumequeue有问题,注意判断)、根据offset查询报错。
异常恢复流程:
1.停止需要恢复这一组broker的主从deamon,主从broker
2.删除主broker store目录下的checkpoint consumequeue consumeStore index(也可以mv 改下名字来备份)
3.检查store目录下的abort文存是否存在,如果不存在新建一个(touch abort)
4.启动主broker,查看store.log,可以看到打印恢复过程的日志,如果没有报错,说明恢复成功
5.如果commitlog文件比较多,可能恢复时间较长,可以通过查看store.log或者broker端口是否起来判断恢复是否完成
6.主broker起来后,通过消费或者根据offset查询消息来验证是否恢复成功
7.如果主broker恢复成功,启动从broker,启动主从deamon
14)RPC异常(所以服务端组件均可能出现)
异常信息

原因:使用非组件RPC协议访问导致,比如用http协议、或者telnet等,均可导致decode错误,
解决办法:无需解决,应服务端及客户端RPC请求均无影响。
