

文档简介:



Q:天翼云鲁班大数据平台产品在什么时候进入开通状态?
A:包月订购的天翼云鲁班大数据平台产品:当您支付费用且系统扣款成功后,将自动为您开通服务。
Q:密码是否做了安全验证?
A:用户密码拥有安全验证。
Q:折线图的数据,如何在DataV上刷新出现?
A:查询出折线图数据,如图1。
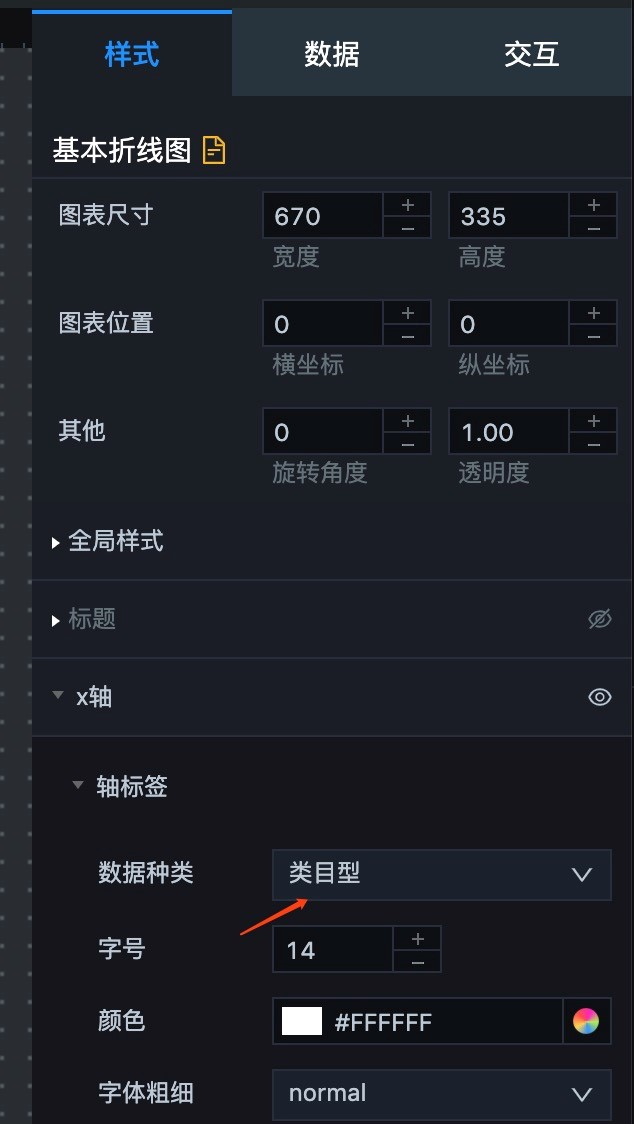
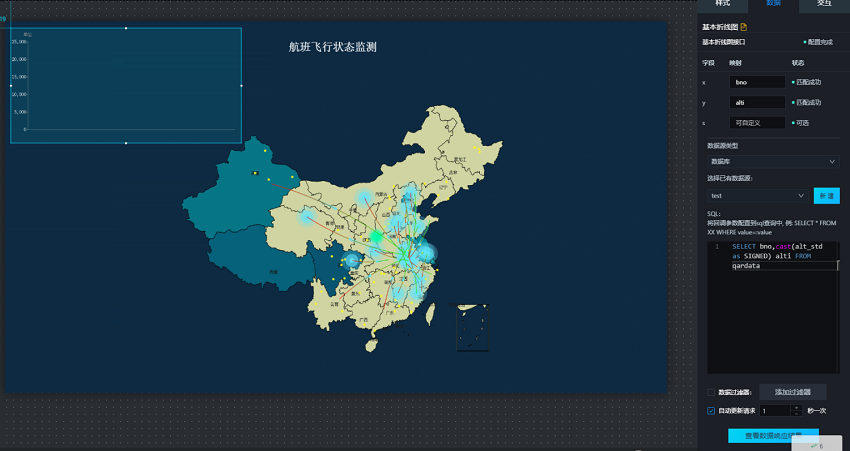 2. 在样式里设置图标尺寸,图标位置,以及数据种类,映射好之后数据就会映射成折线图。
2. 在样式里设置图标尺寸,图标位置,以及数据种类,映射好之后数据就会映射成折线图。
Q:在Visualis中定义Widget,能在DataV中使用吗?
A:不能。
Q:pyspark写代码的时候,sparkContext怎么初始化?
A:平台已经创建了全局的sparkContext===> sc,直接使用就好,不需要在创建。下列黄色行不需要,写了会报错。
代码示例:
from pyspark import SparkContext, SparkConf
conf = SparkConf().setAppName( "first app").setMaster("local")
sc = SparkContext(conf=conf)
sc = SparkContext("local", "first app")
words = sc.parallelize (["scala", "java", "hadoop", "spark", "akka", "spark vs hadoop", "pyspark", "pyspark and spark"])
#count()
counts = words.count()
print "Number of elements in RDD -> %i" % (counts)
#collect()
coll = words.collect()
print "Elements in RDD - %s" % (coll)
#foreach()
def function1(x):
""" # 针对RDD中每个元素的函数 """
print(x)
fore = words.foreach(function1)
#filter(function)函数
words_filter = words.filter(lambda x: 'spark' in x)
filtered = words_filter.collect()
print "Fitered RDD -> %s" % (filtered)
#map(function)函数
words_map = words.map(lambda x: (x, 1))
mapping = words_map.collect()
print "Key value pair -> %s" % (mapping)
#reduce(function)函数
from operator import add
nums = sc.parallelize([1, 2, 3, 4, 5])
adding = nums.reduce(add)
print "Adding all the elements -> %i" % (adding)
#join(other, numPartitions=None)函数
x = sc.parallelize([("spark", 1), ("hadoop", 4)])
y = sc.parallelize([("spark", 2), ("hadoop", 5)])
joined = x.join(y)
final = joined.collect()
print "Join RDD -> %s" % (final)
#cache()函数
words.cache()
caching = words.persist().is_cached
print "Words got chached > %s" % (caching)
Q:在执行hql时,如何配置指定hive连接信息?
A:整个平台是一套系统,用户不用关心底层存储,hive直接访问,不需要指定hive的信息,hadoop的文件上传和下载都已经做了图形化封装,直接拖拽即可,不需要指定namenode。
Q:hql和shell的格式有要求么,hql多条可写在一起还是写在多个hql中,shell是按照shell脚本规则写?
A:hql 的开发面,是标准的SQL开发编辑器,只要符合SQL规范即可,因此可以多条写在同一个文件里。
Q:页面的参数是什么参数,可否给个例子?
A:页面的参数,类似shell脚本传参,在参数地方设置的参数,在开发页面可以通过${ 参数名 } 获取。例: 参数设置: name = "zhangsan" scala编辑界面:println( ${ name } )。
