腾讯云消息队列 CKafka - 限流问题
文档简介:
限流机制说明:
Kafka 的限流机制是软限流,即当用户流量超过配额后,采用延时回包的方式进行处理,而不是给客户端返回报错。



限流机制说明
Kafka 的限流机制是软限流,即当用户流量超过配额后,采用延时回包的方式进行处理,而不是给客户端返回报错。
以 API 限流为例,举例如下:
硬限流:假设调用频率为100次/s,当每秒内客户端调用超过100次时,服务端就会返回错误,客户端就需要根据业务逻辑进行处理。
软限流:假设调用频率为100次/s,正常耗时是10ms。当每秒内客户端调用超过100次时:
如为110次,则本次请求耗时20ms。
如为200次,则耗时为50ms。此时对客户端就是友好的,不会因为突增流量或者流量波动产生报错告警,业务可以正常进行。
综上所述,在 Kafka 这种大流量的场景下,软限流是更符合用户体验的。
购买带宽和生产消费带宽的关系:
生产最大带宽(每秒)= 购买带宽 / 副本数
消费最大带宽(每秒)= 购买带宽
延时回包限流原理
CKafka 实例的底层限流机制是基于令牌桶原理实现的。将每秒分为多个桶,每个时间桶的单位为 ms。
限流策略会把每秒(1000ms)均分为若干个时间桶。例如分为10个时间桶,每个桶的时间则为100ms。每个时间桶的限流阈值就是总实例规格速度的1/10。如果某个时间桶内的 TCP 请求流量超过了该时间桶的限流阈值,会根据内部限流算法增加该请求的延时回包时间,使客户端无法快速收到 TCP 回包达到一段时间内的限流效果。
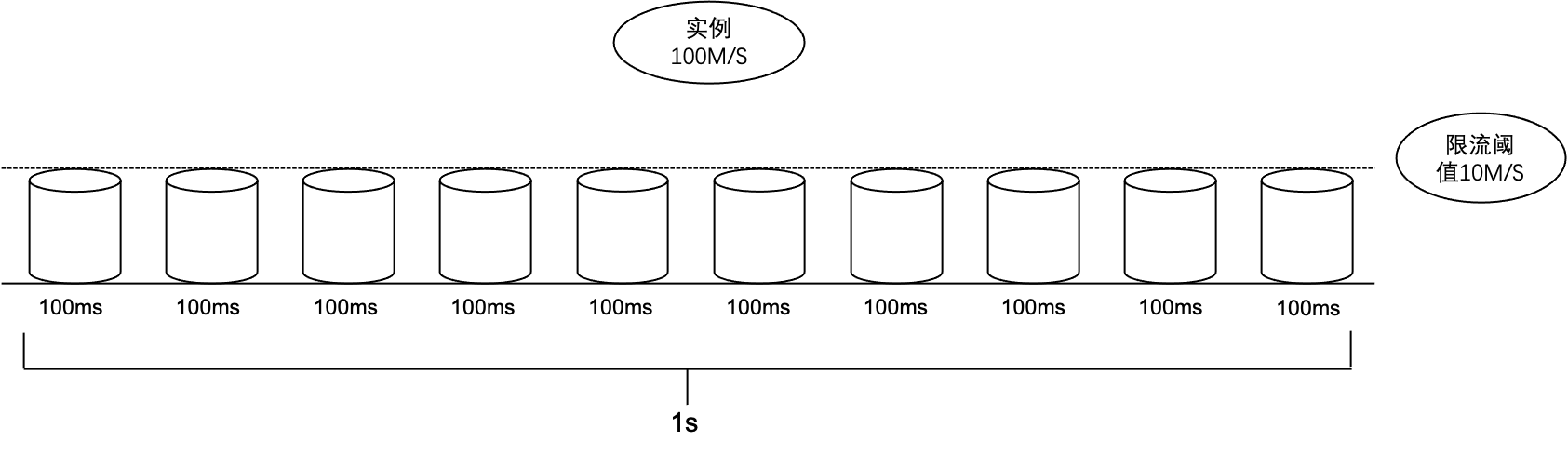
为什么监控生产/消费低于实例规格时会触发限流?
如上原理所述,因为限流是以ms为单位的,控制台监控平台数据是按每秒采集,分钟维度聚合(最大值或者平均值)。
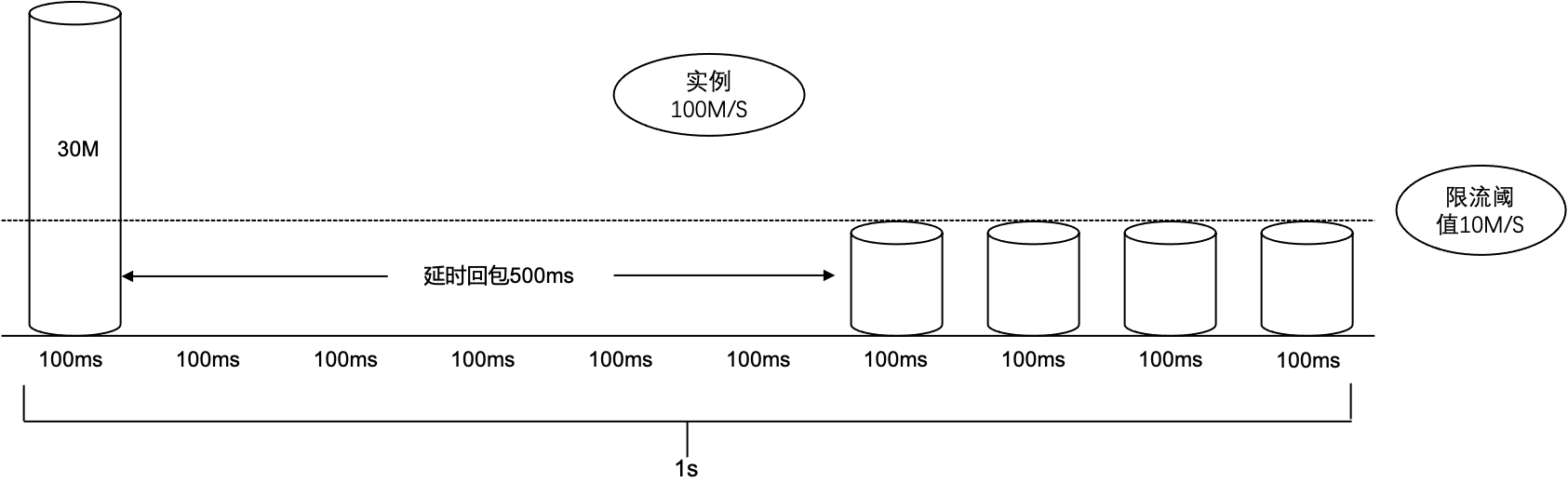
按令牌桶原理可知,单个桶不会强制限制流量。如果实例 A 的带宽规格为100MB/s,那么每个100ms的时间桶的限流阈值为 100MB/10 = 10MB/桶,假设实例A的生产流量在某秒的第一个100ms时间桶达到了30MB (时间桶限流阈值的3倍)。那么这时会触发 broker 限流策略增加延时回包时间,假设原先正常 TCP 返回时间是100ms,超限后可能会增加500ms才返回。最终这秒的流量 :30MB × 1 + 0MB × 5 + 10MB × 4 = 70MB,即这秒内的流量速度为70MB/s小于实例规格100MB/s。
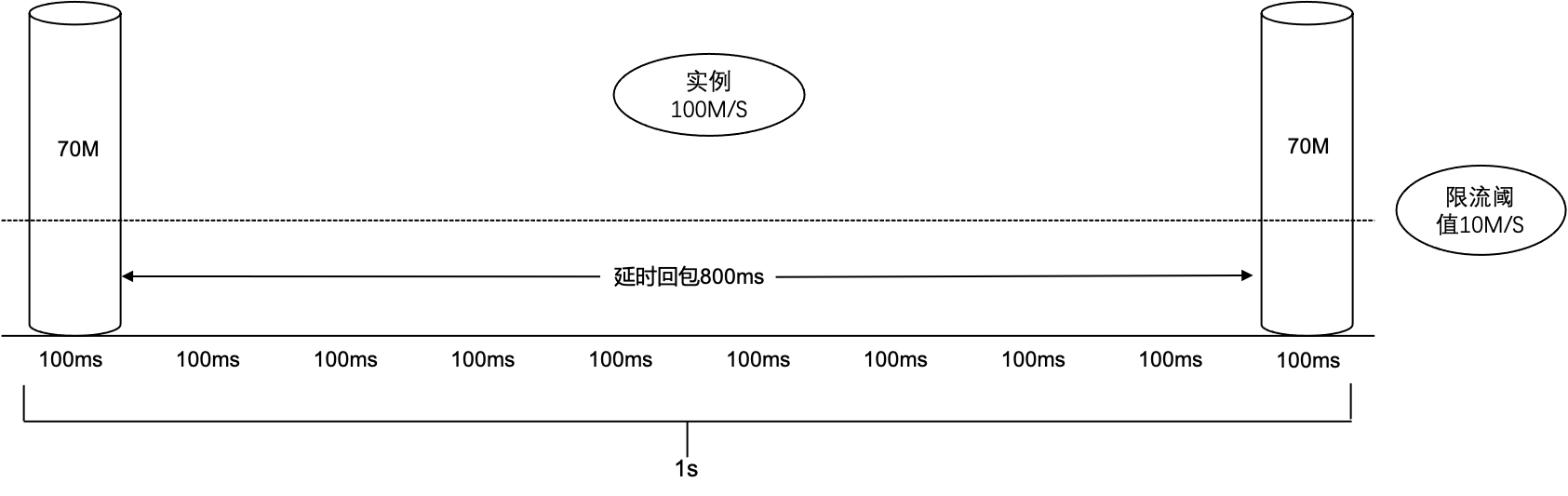
为什么生产/消费峰值流量会高于实例规格?
再次假设实例A的带宽规格为100MB/s,那么每个100ms的时间桶的限流阈值为10MB,假设实例A的生产流量在某秒的第一个100ms时间桶达到了70MB(时间桶限流阈值的7倍)。那么这时会触发 broker 限流策略增加延时回包时间,假设原先正常 TCP 返回时间是100ms,超限后可能会增加800ms延时才返回,在第900ms回包后客户端立刻又在第10个时间桶打入了70MB流量。最终这秒的流量 (70MB × 1 + 0MB × 8 + 70MB × 1) = 140MB,即这秒内的流量速度为140MB/s大于实例规格100MB/s。
限流次数为什么会暴增?
限流次数是以 TCP 请求统计的,如果实例A在某秒第一个时间桶流量打超了,那么超限后这个时间桶的剩余时间内所有的TCP请求都会被限制并统计限流次数。
CKafka 如何进行限流?
为保证服务的稳定性,CKafka 在消息出入上都做了流量管控。
用户所有副本流量之和超过购买时的峰值流量时,会发生限流。
在生产端发生限流时,CKafka 会延长一个 TCP 链接的回应时间,延迟时间取决于用户瞬时流量超过限制的大小。和道路交通管制的原理有点类似,流量超得越多,延时算法得出来的延时值越高,最高5分钟。
在消费端发生限流时,CKafka 会缩小每次 fetch.request.max.bytes 的大小,控制消费端的流量。
如何判断 CKafka 是否发生限流?
1. 在实例列表上,每个集群都有对应的健康度展示。当健康度显示为“警告”字样时,可以将鼠标移至其上查看弹出的详细数据。这个数据会展示当前用户的峰值流量以及发生限流的次数,用户可以根据这里的数据判断该实例是否发生过限流。
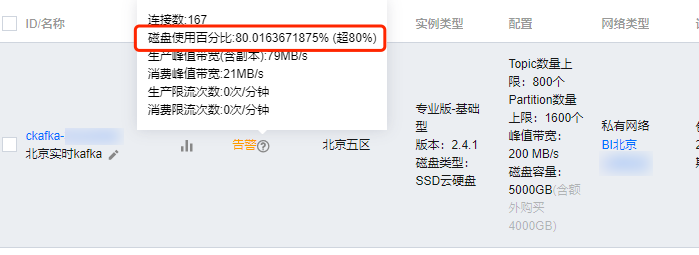
2. 用户可以打开监控数据查看流量的最大值,如果 (流量的最大值 × 副本数) > 购买时的峰值带宽,则表明至少发生过一次限流。可通过配置限流告警得知是否发生限流。
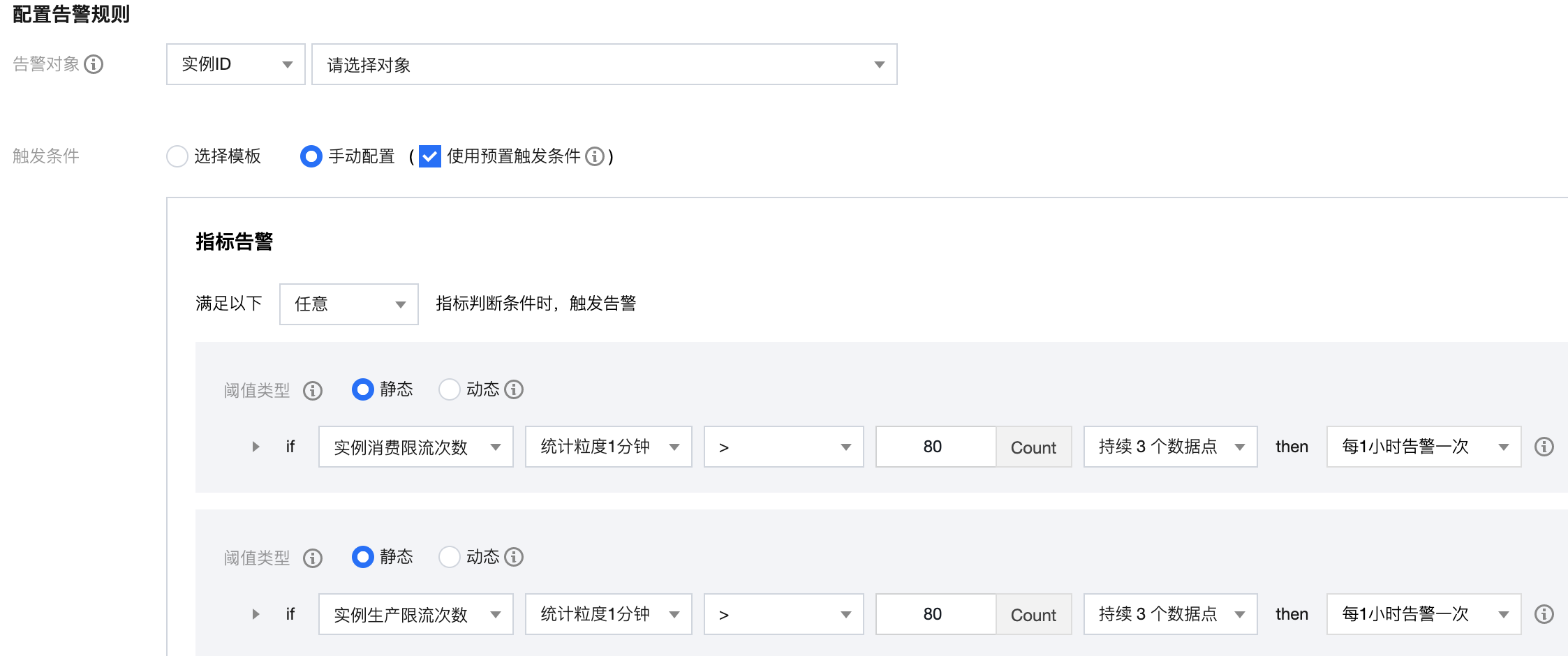
3. 在 CKafka 控制台的监控页面查看实例监控,当限流次数大于0,证明发生过限流。