

腾讯云消息队列 CKafka - 数据处理规则说明
文档简介:
概览:
在通过 CKafka 连接器处理数据流入流出任务时,通常需要对数据进行简易的清洗操作,如格式化原始数据、解析特定字段、数据格式转换等等。开发者往往需要自己搭建一套数据清洗的服务(ETL)。



概览
在通过 CKafka 连接器处理数据流入流出任务时,通常需要对数据进行简易的清洗操作,如格式化原始数据、解析特定字段、数据格式转换等等。开发者往往需要自己搭建一套数据清洗的服务(ETL)。
Logstash 是一款免费且开放的服务器端数据处理管道,能够从多个数据源采集数据,转换数据,然后将数据发送到相应的“存储库”中。 logstash 拥有丰富的过滤器插件,这使得 logstash 成为了被广泛使用的一款功能强大的数据转换工具。
然而搭建、配置、维护自己的 logstash 服务会增大开发和运维的难度,为此 Ckafka 提供了一套对标 logstash 的数据处理服务,开发者仅需通过控制台交互界面就可以新建自己的数据处理任务。数据处理服务允许用户编辑相应的数据处理规则,支持构建链式处理,同时可以预览数据处理的结果,帮助用户轻松高效的构建一套数据处理服务,满足数据清洗和转换的需求。
功能对标清单
|
Logstash
|
连接器数据处理服务
|
功能
|
|
Codec.json
|
✔
|
数据解析(JSON)
|
|
Filter.grok
|
✔
|
数据解析(正则匹配)
|
|
Filter.mutate.split
|
✔
|
数据解析(字符分割)
|
|
Filter.date
|
✔
|
日期格式处理
|
|
Filter.json
|
✔
|
解析内部json结构
|
|
Filter.mutate.convert
|
✔
|
数据修改(格式转换)
|
|
Filter.mutate.gsub
|
✔
|
数据修改(字符替换)
|
|
Filter.mutate.strip
|
✔
|
数据修改(去除首尾空格)
|
|
Filter.mutate.join
|
✔
|
数据修改(拼接字段)
|
|
Filter.mutate.rename
|
✔
|
字段修改(更改字段名)
|
|
Filter.mutate.update
|
✔
|
字段修改(更新字段)
|
|
Filter.mutate.replace
|
✔
|
字段修改(替换字段)
|
|
Filter.mutate.add_field
|
✔
|
字段修改(添加字段)
|
|
Filter.mutate.remove_field
|
✔
|
字段修改(删除字段)
|
|
Filter.mutate.copy
|
✔
|
字段修改(复制字段值)
|
|
Filter.mutate.merge
|
|
TODO
|
|
Filter.mutate.uppercase
|
|
TODO
|
|
Filter.mutate.lowercase
|
|
TODO
|
操作方法介绍
数据解析
logstash 处理方式:
// Codec.jsoninput {file {path => "/var/log/nginx/access.log_json""codec => "json"}}// Filter.grokfilter {grok {match => {"message" => "\s+(?<request_time>\d+(?:\.\d+)?)\s+"}}}// Filter.mutate.splitfilter {split {field => "message"terminator => "#"}}
连接器处理方式:
通过选择相应的数据解析模式 ,并一键点击即可预览:

日期格式处理
logstash 处理方式:
// Filter.datefilter {date {match => ["client_time", "yyyy-MM-dd HH:mm:ss"]}}
连接器处理方式:
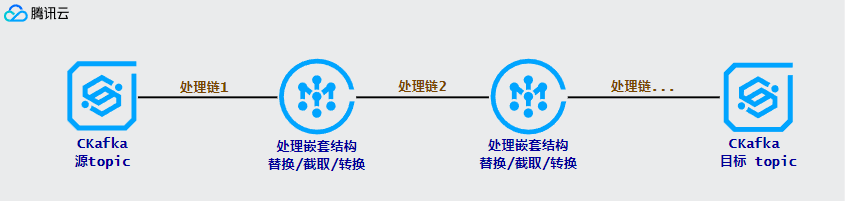
1.1 可以通过预设系统当前时间给某字段赋值:
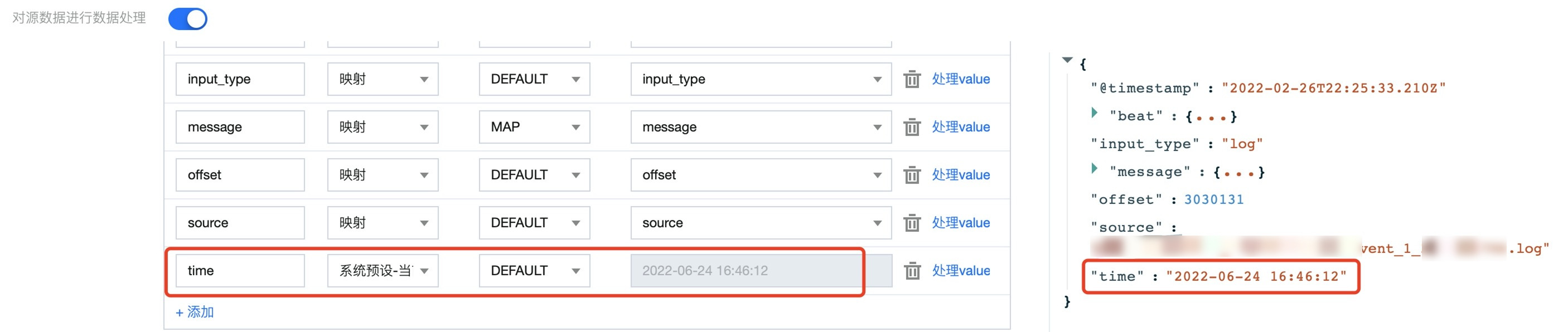
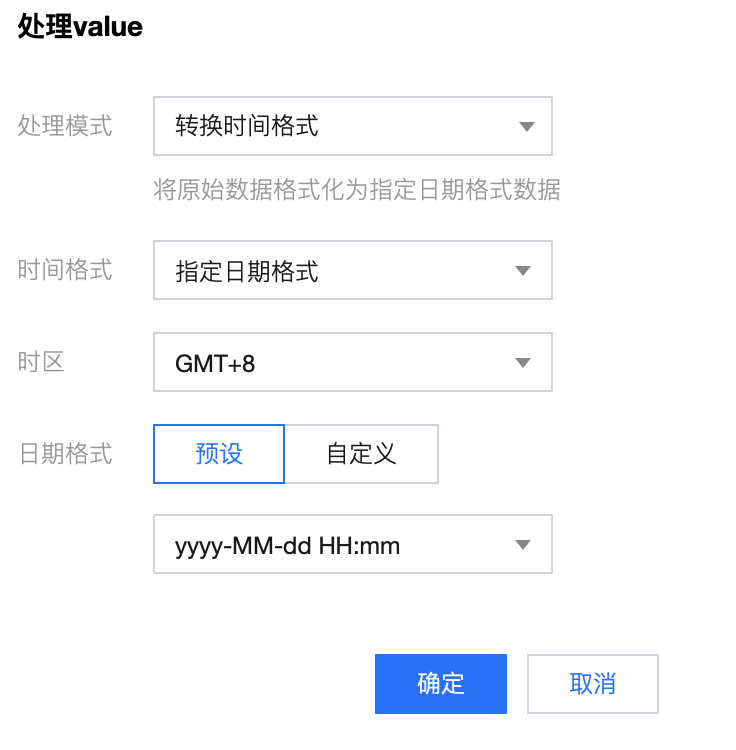
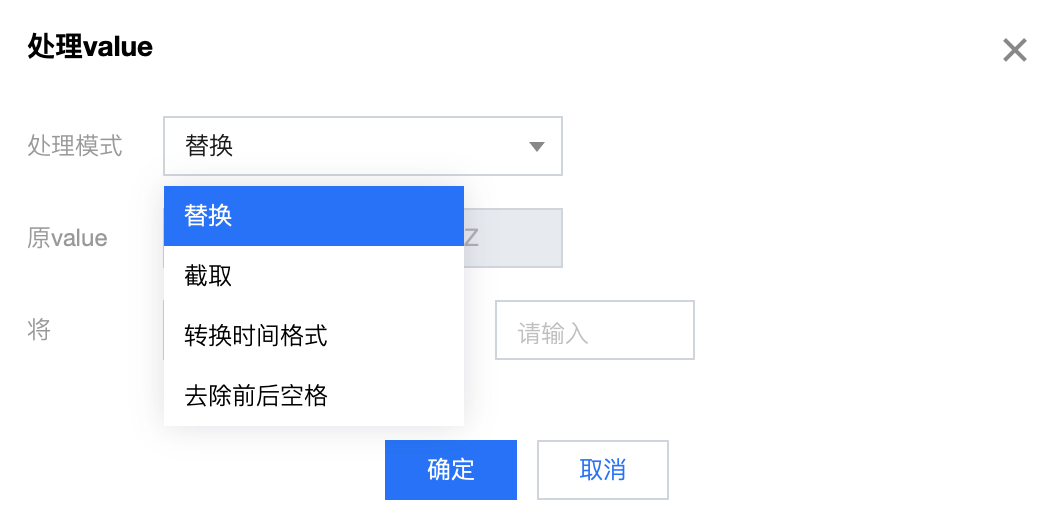
1.2 通过 处理 value 功能来对数据内容进行处理:
解析内部 JSON 结构
logstash 处理方式:
// Filter.jsonfilter {json {source => "message"target => "jsoncontent"}}
连接器处理方式:
通过对某字段选择 MAP 操作来对其进行解析,从而把特定字段解析为 JSON 格式:
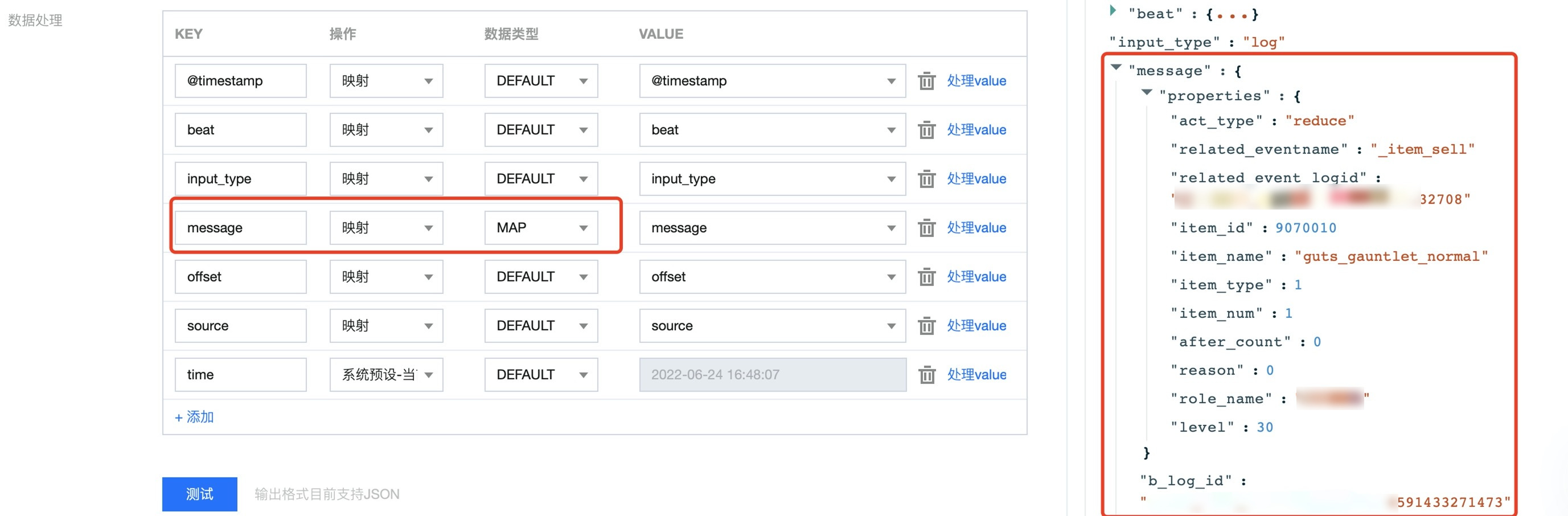
数据修改
logstash 处理方式:
// Filter.mutate.convertfilter {mutate {convert => ["request_time", "float"]}}// Filter.mutate.gsubfilter {mutate {gsub => ["urlparams", ",", "_"]}}// Filter.mutate.stripfilter {mutate {strip => ["field1", "field2"]}}// Filter.mutate.joinfilter {mutate {join => { "fieldname" => "," }}}
连接器处理方式:
通过选择相应的处理 value 功能一键定义规则:
1.1 通过选择数据格式一键更改相应字段的数据格式: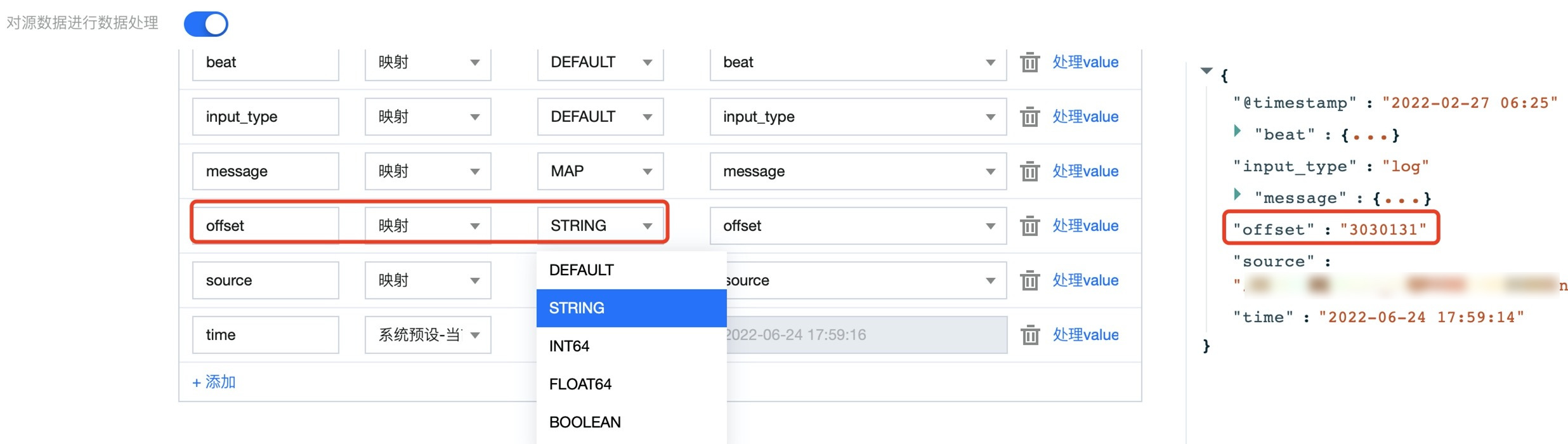
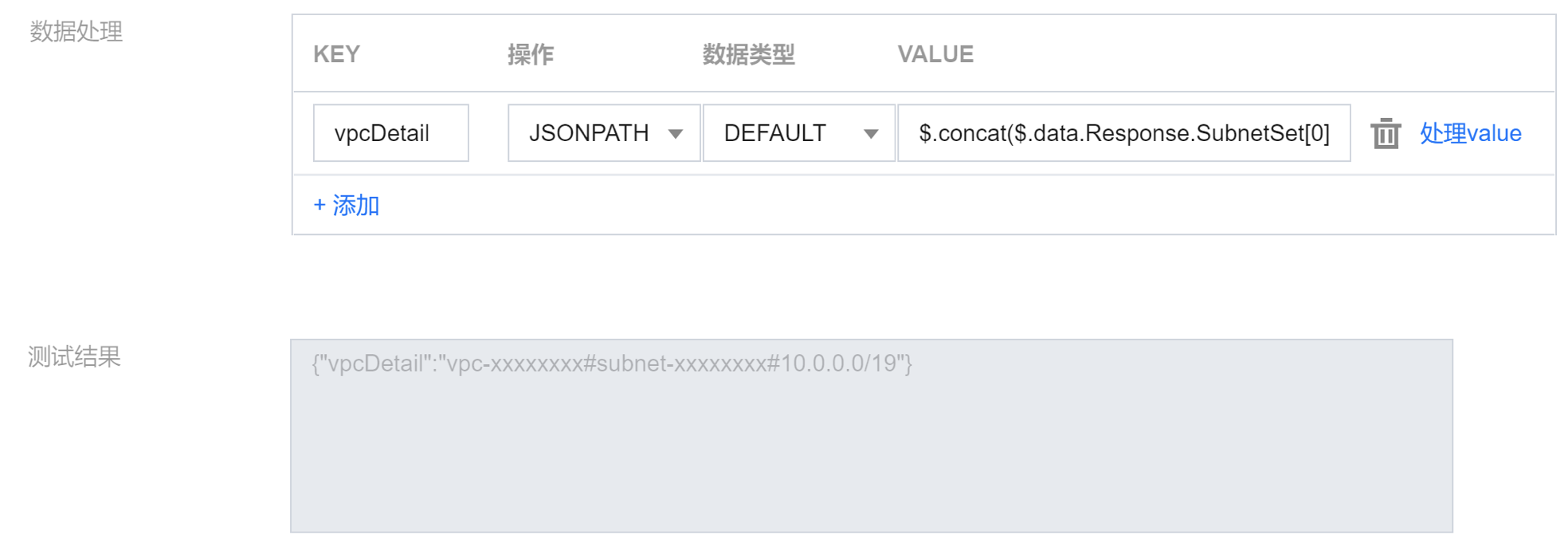
1.2 通过 JSONPATH 语法实现 join 的拼接功能,如是用 $.concat($.data.Response.SubnetSet[0].VpcId,"#",$.data.Response.SubnetSet[0].SubnetId,"#",$.data.Response.SubnetSet[0].CidrBlock)) 语法拼接 Vpc 和子网的属性,并且通过 # 字符加以分割。
1.3 结果如下:
字段修改
logstash 处理方式:
// Filter.mutate.renamefilter {mutate {rename => ["syslog_host", "host"]}}// Filter.mutate.updatefilter {mutate {update => { "sample" => "My new message" }}}// Filter.mutate.replacefilter {mutate {replace => { "message" => "%{source_host}: My new message" }}}// Filter.mutate.add_fieldfilter {mutate {split => { "hostname" => "." }add_field => { "shortHostname" => "%{[hostname][0]}" }}}// Filter.mutate.remove_fieldfilter {mutate {remove_field => ["field_name"]}}// Filter.mutate.copyfilter {mutate {copy => { "source_field" => "dest_field" }}}
连接器处理方式:
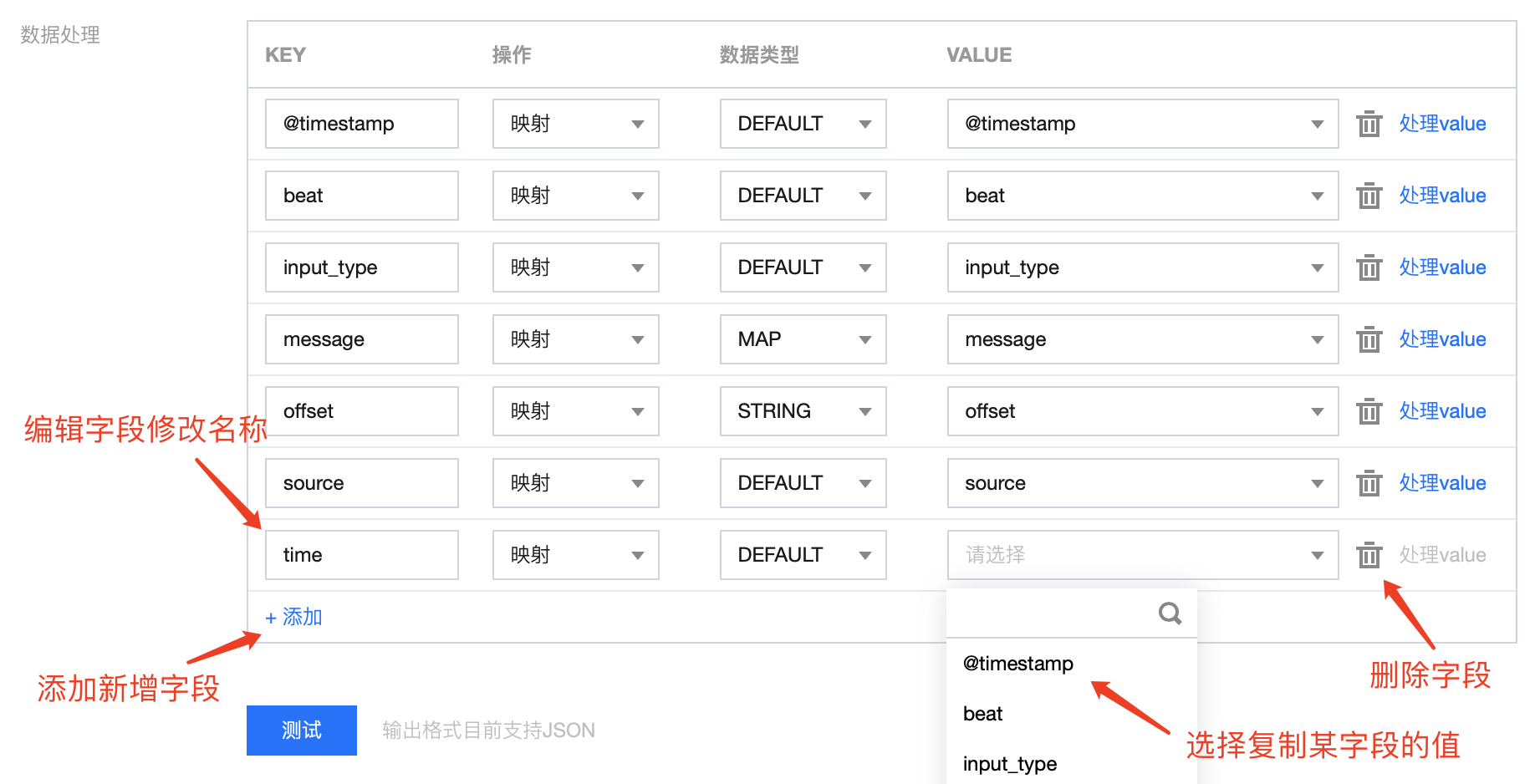
实际案例演示
案例1:多级字段解析
输入 message:
{"@timestamp": "2022-02-26T22:25:33.210Z","beat": {"hostname": "test-server","ip": "6.6.6.6","version": "5.6.9"},"input_type": "log","message": "{\"userId\":888,\"userName\":\"testUser\"}","offset": 3030131,}
目标 message :
{"@timestamp": "2022-02-26T22:25:33.210Z","input_type": "log","hostname": "test-server","ip": "6.6.6.6","userId": 888,"userName": "testUser"}
连接器配置方法:
1.1 处理链 1 配置如下:
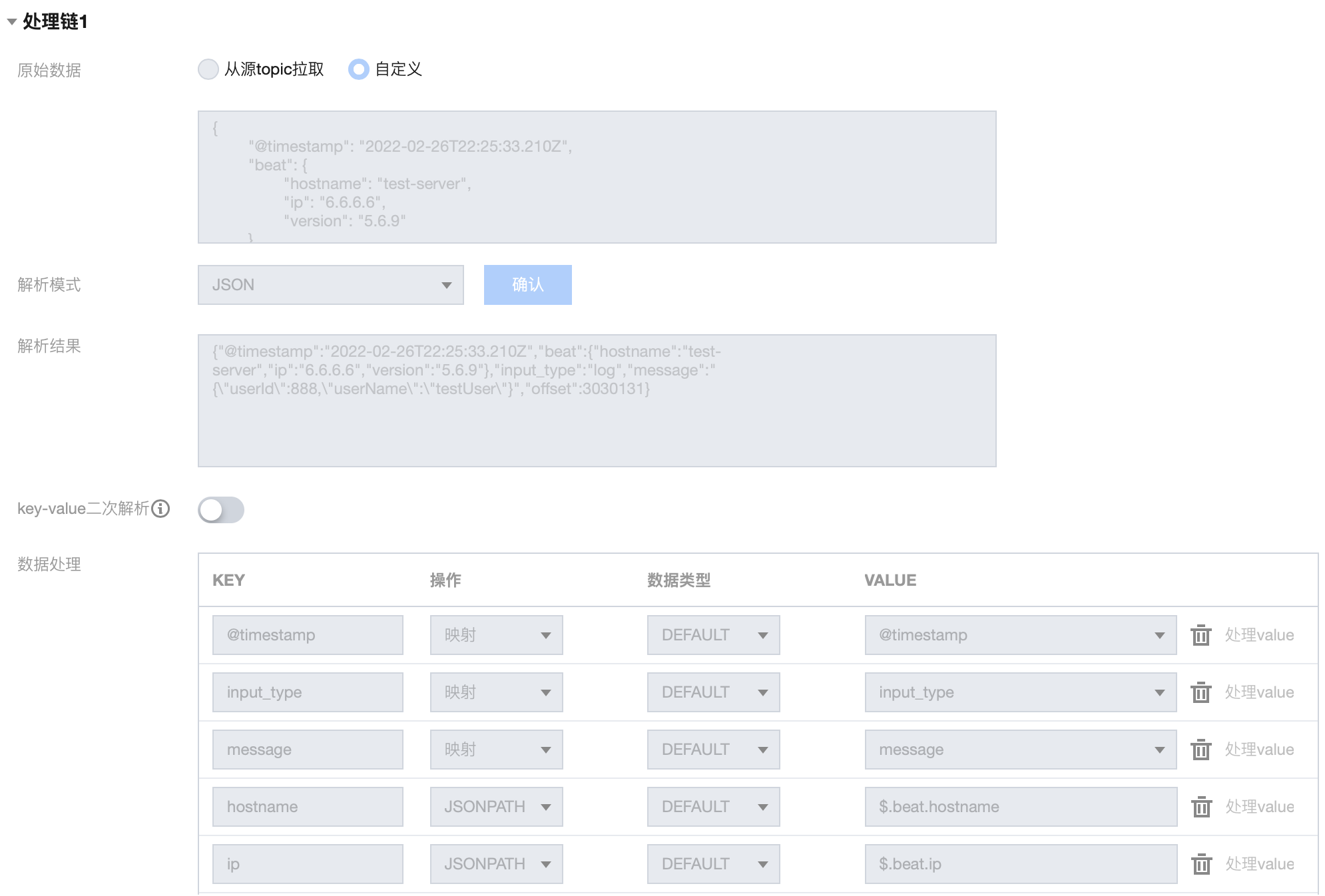
1.2 处理链 1 结果如下:
{"@timestamp": "2022-02-26T22:25:33.210Z","input_type": "log","message": "{\"userId\":888,\"userName\":\"testUser\"}","hostname": "test-server","ip": "6.6.6.6"}
1.3 处理链 2 配置如下:
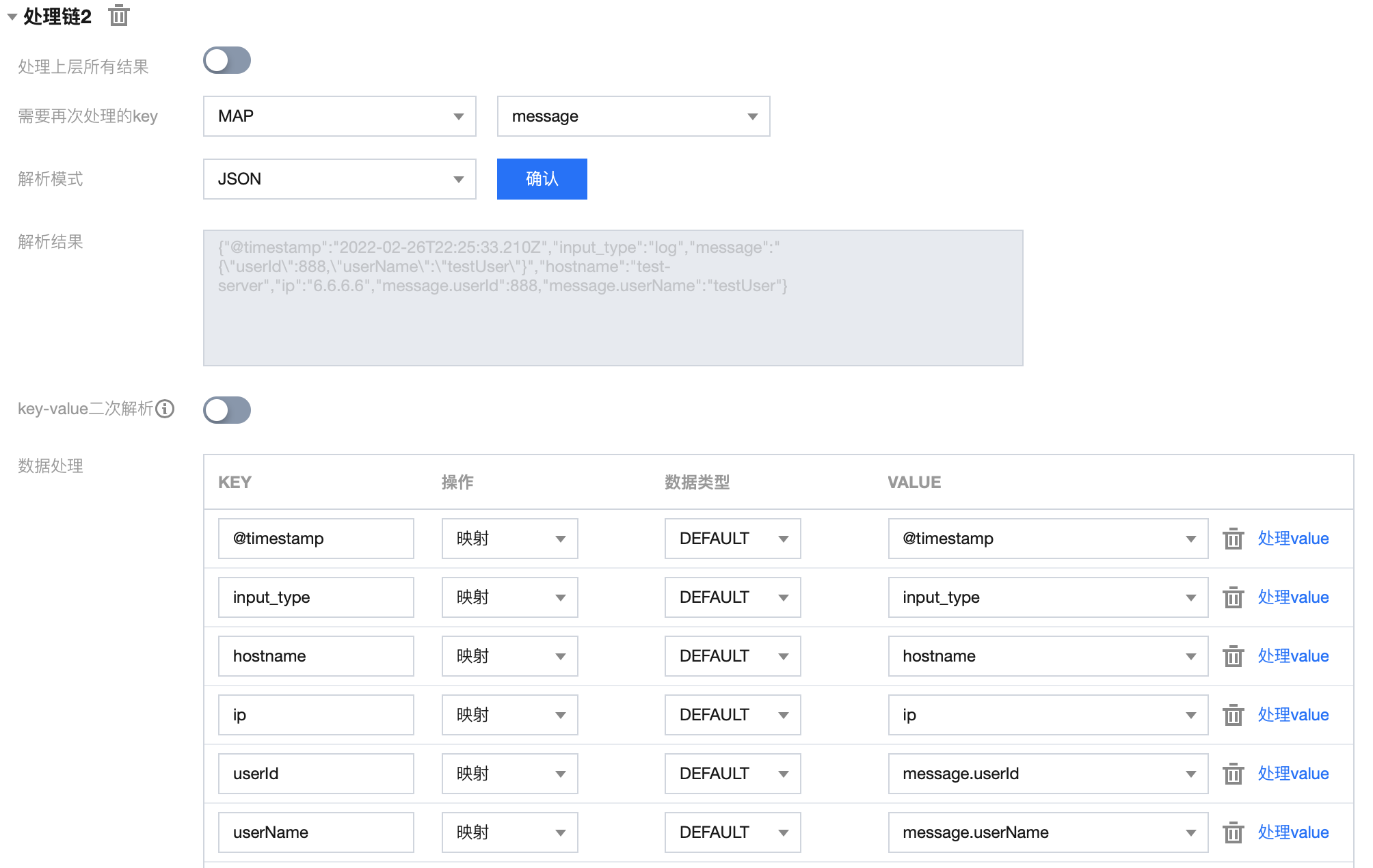
1.4 处理链 2 结果如下:
{"@timestamp": "2022-02-26T22:25:33.210Z","input_type": "log","hostname": "test-server","ip": "6.6.6.6","userId": 888,"userName": "testUser"}
案例2:非 JSON 数据解析
输入 message :
region=Shanghai$area=a1$server=6.6.6.6$user=testUser$timeStamp=2022-02-26T22:25:33.210Z
目标 message:
{"region": "Shanghai","area": "a1","server": "6.6.6.6","user": "testUser","timeStamp": "2022-02-27 06:25:33","processTimeStamp": "2022-06-27 11:14:49"}
连接器配置方法:
1.1 使用分隔符 $ 对原始 message 进行解析
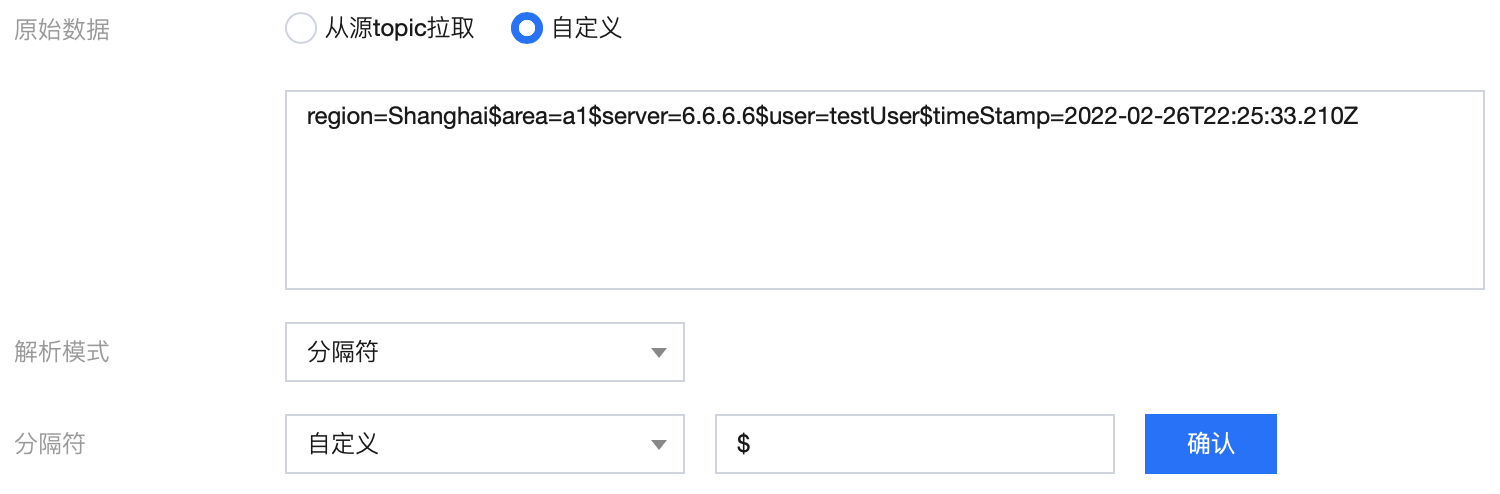
1.2 初步解析结果:
{"0": "region=Shanghai","1": "area=a1","2": "server=6.6.6.6","3": "user=testUser","4": "timeStamp=2022-02-26T22:25:33.210Z"}
1.3 使用分隔符 = 对结果二次解析:

1.4 二次解析结果:
{"0": "region=Shanghai","1": "area=a1","2": "server=6.6.6.6","3": "user=testUser","4": "timeStamp=2022-02-26T22:25:33.210Z","0.region": "Shanghai","1.area": "a1","2.server": "6.6.6.6","3.user": "testUser","4.timeStamp": "2022-02-26T22:25:33.210Z"}
1.5 对字段进行编辑、删减,调整时间戳格式,并新增当前系统时间字段:
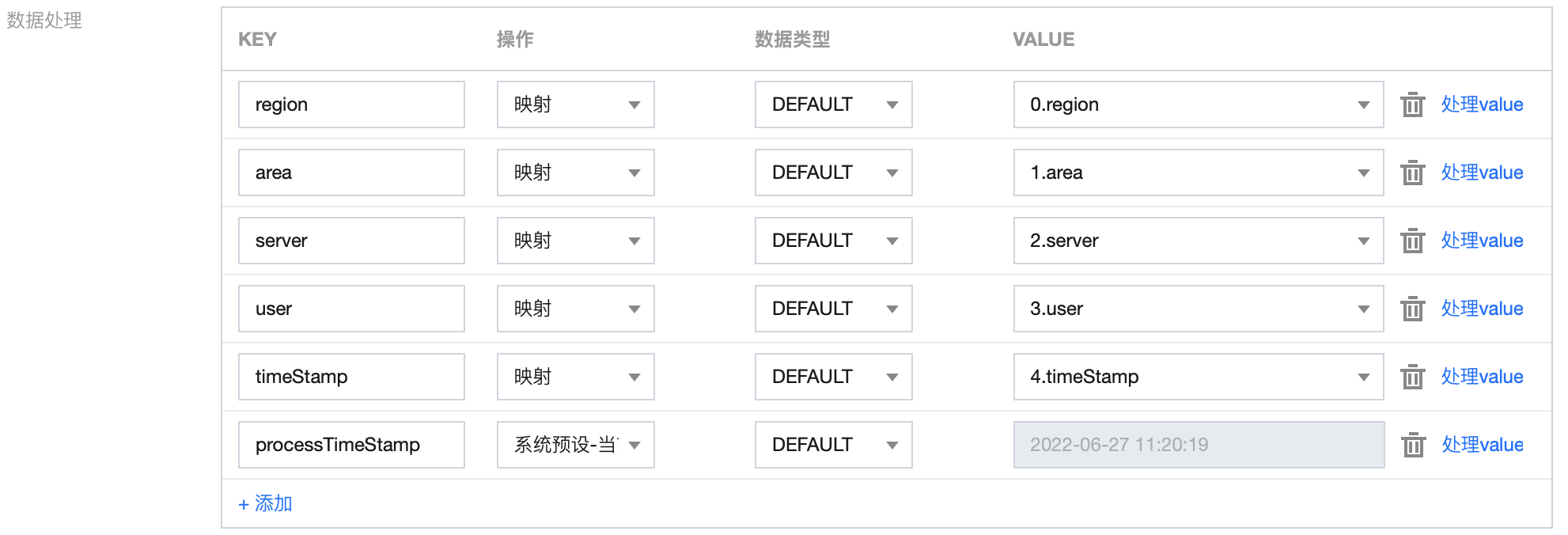

最终结果:
{
"region": "Shanghai",
"area": "a1",
"server": "6.6.6.6",
"user": "testUser",
"timeStamp": "2022-02-27 06:25:33",
"processTimeStamp": "2022-06-27 11:14:49"
}
