

腾讯云消息队列 CKafka 新建数据流出任务 - 数据解析
文档简介:
在创建数据流出任务时,通常需要对数据进行简易的清洗操作,如格式化原始数据、解析特定字段、数据格式转换等等。CKafka 连接器提供简单的数据处理功能,通过传入数据和配置项,可以实现对数据格式化处理,然后返回处理完成的结构化数据,分发给离线/在线处理平台,构建数据源和数据处理系统间的桥梁。



在创建数据流出任务时,通常需要对数据进行简易的清洗操作,如格式化原始数据、解析特定字段、数据格式转换等等。CKafka 连接器提供简单的数据处理功能,通过传入数据和配置项,可以实现对数据格式化处理,然后返回处理完成的结构化数据,分发给离线/在线处理平台,构建数据源和数据处理系统间的桥梁。
本文介绍数据解析的基本规则和常见的数据解析案例,帮助您更好地了解 CKafka 连接器的数据处理功能。
数据解析规则说明
1. 在数据处理规则设置页面,单击预览 Topic 消息可以预览源数据。
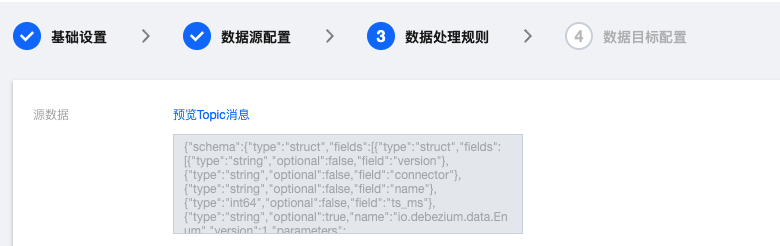
2. 开启对源数据进行数据处理按钮。
3. (可选)数据处理规则配置支持从本地导入模板,若已有提前准备好的规则模板,直接导入即可,若无则继续进行步骤4配置数据处理规则。
4. 选择原始数据来源,支持从源 Topic 拉取或者自定义,此处以从源 Topic 拉取为例。

5. 通过选择相应的数据解析模式并确认,可以查看数据解析结果,此处以 **JSON **模式为例。单击左侧解析数据可以在右侧生成结构化预览。
JSON
分隔符:支持 空格、制表符、,、;、|、:、自定义。
正则提取:您可以手动填写正则表达式,也支持使用正则表达式自动生成,参考文档正则表达式自动生成。
JSON 对象数组-单行输出:数组内每个对象的格式一致,解析时仅解析第一个对象,输出结果是单条的 json,是 map 类型。
JSON 对象数组-多行输出:数组内每个对象的格式一致,解析时仅解析第一个对象,输出结果为数组类型。
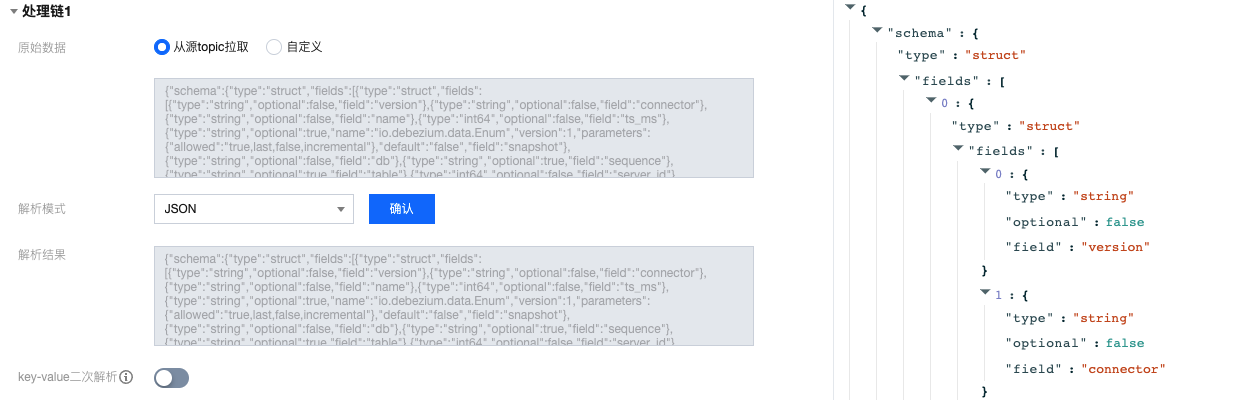
6. (可选)开启 key-value 二次解析后,将对 value 里的数据再次进行 key-value 解析。
7. (可选)添加处理链可对上面的处理结果再次进行处理。
8. 设置数据处理规则,此处可对字段进行编辑、删减,调整时间戳格式,并新增当前系统时间字段等等。
操作 = 系统预设:可以选择系统预设的 VALUE ,目前支持 DATE(时间戳)。
操作 = 映射:可以选择已有的 KEY,最终输出的 VALUE 值由指定的 KEY 映射而来。
操作 = 自定义:可以输入自定义 VALUE。
操作 = JSONPATH:解析多层嵌套的 JSON 数据,用$符号开头,.符号定位到多层 JSON 的具体字段。
9. 单击 VALUE 栏旁边的处理 value 可以对 value 值进行处理,支持替换、截取、转换时间格式、去除前后空格和正则替换五种处理方式。
10. 单击测试,查看数据处理的测试结果。
11. (可选)开启过滤器,仅输出符合过滤器规则的数据。过滤器的匹配模式支持前缀匹配、后缀匹配、包含匹配(contains)、除外匹配(except)、数值匹配和IP匹配。详情参见 过滤器规则说明。
12. 选择输出格式:默认 JSON。支持 RAW 格式,若选择 RAW 格式时:
当输出行内容为 VALUE 时,VALUE 间分隔符默认为“无”选项。
当输出行内容为 KEY&VALUE 时,KEY/VALUE 分隔符和 VALUE 间分隔符均不能为“无”。
13. 设置投递失败的消息处理规则,支持丢弃、保留和投递到死信队列(需指定死信队列 Topic)。
14. (可选)数据规则配置完成后,可以直接在顶部点击导出为模板,在后续的数据任务中复制使用,减少重复配置的操作成本。
数据解析案例
案例1:多级字段解析
{"@timestamp": "2022-02-26T22:25:33.210Z","beat": {"hostname": "test-server","ip": "6.6.6.6","version": "5.6.9"},"input_type": "log","message": "{\"userId\":888,\"userName\":\"testUser\"}","offset": 3030131,}
{"@timestamp": "2022-02-26T22:25:33.210Z","input_type": "log","hostname": "test-server","ip": "6.6.6.6","userId": 888,"userName": "testUser"}
1. 处理链 1 配置如下:
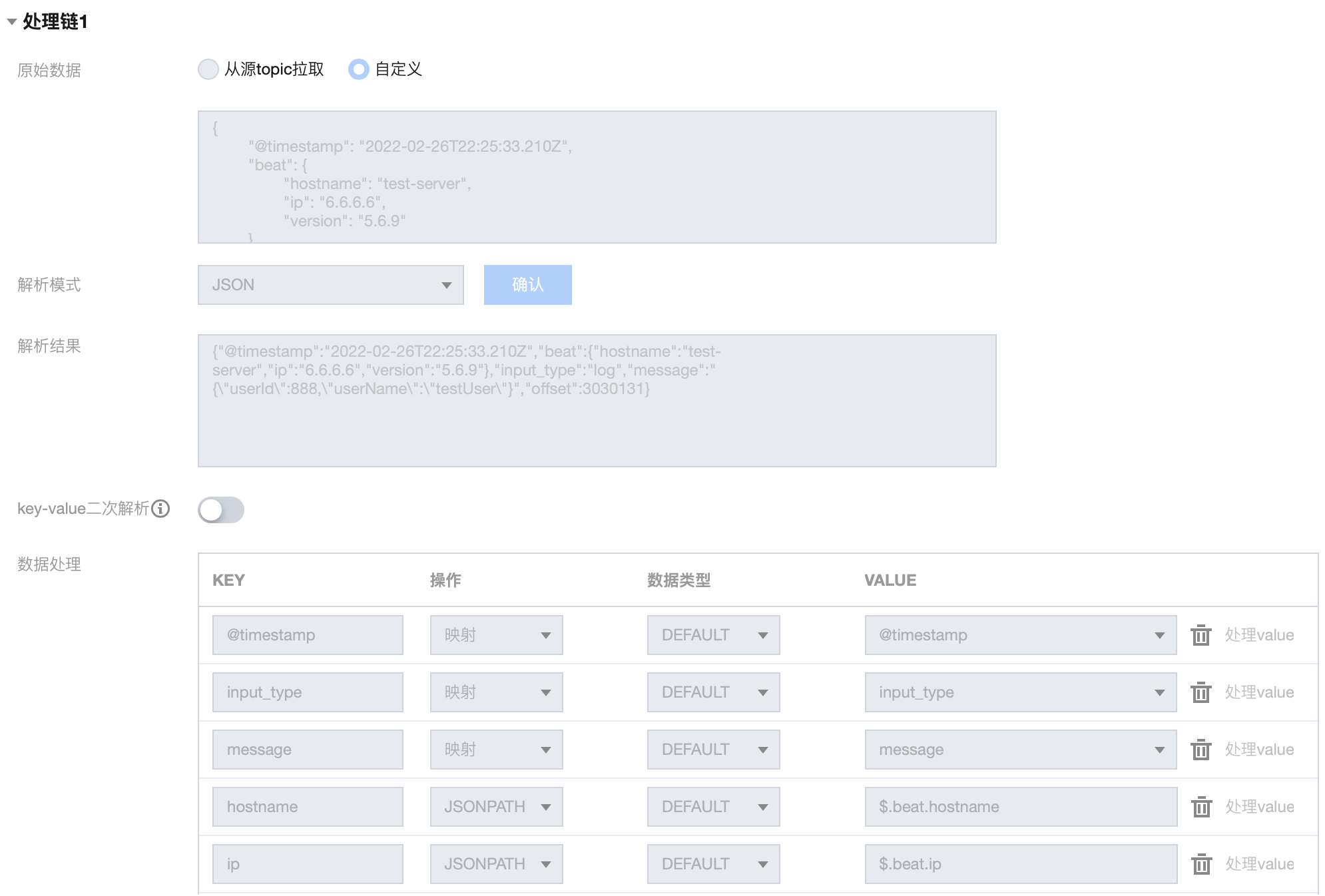
2. 处理链 1 结果如下:
{"@timestamp": "2022-02-26T22:25:33.210Z","input_type": "log","message": "{\"userId\":888,\"userName\":\"testUser\"}","hostname": "test-server","ip": "6.6.6.6"}
3. 处理链 2 配置如下:
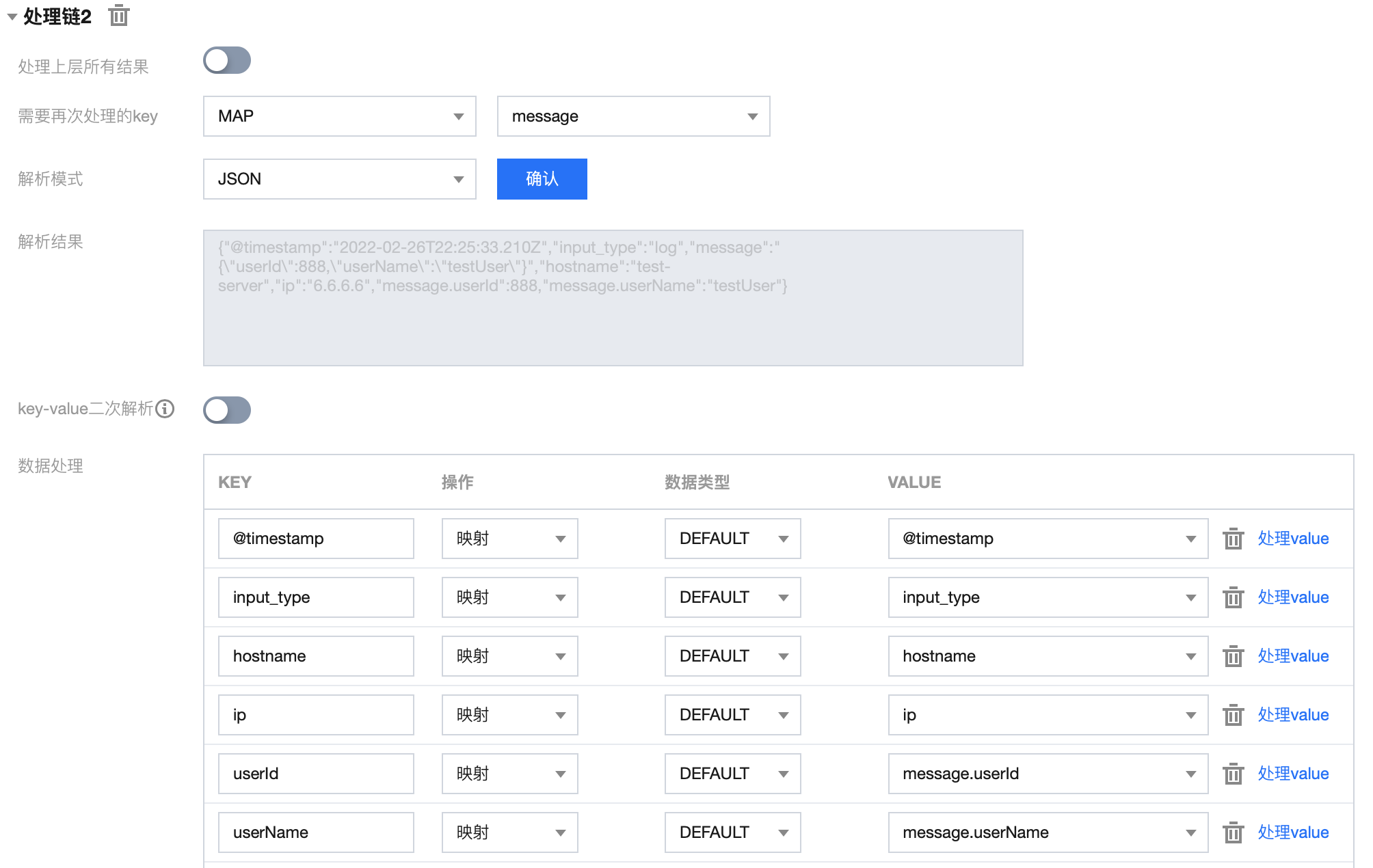
4. 处理链 2 结果如下:
{"@timestamp": "2022-02-26T22:25:33.210Z","input_type": "log","hostname": "test-server","ip": "6.6.6.6","userId": 888,"userName": "testUser"}
案例2:非 JSON 数据解析
region=Shanghai$area=a1$server=6.6.6.6$user=testUser$timeStamp=2022-02-26T22:25:33.210Z
{"region": "Shanghai","area": "a1","server": "6.6.6.6","user": "testUser","timeStamp": "2022-02-27 06:25:33","processTimeStamp": "2022-06-27 11:14:49"}
1. 使用分隔符 $ 对原始 message 进行解析:
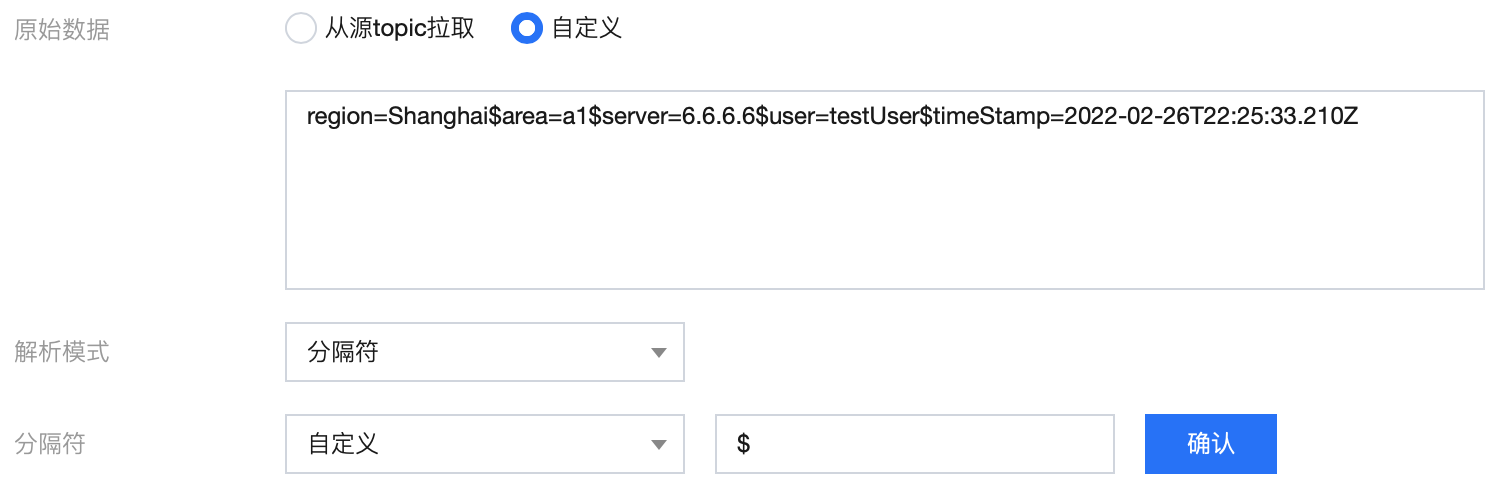
2. 初步解析结果:
{"0": "region=Shanghai","1": "area=a1","2": "server=6.6.6.6","3": "user=testUser","4": "timeStamp=2022-02-26T22:25:33.210Z"}
3. 使用分隔符 = 对结果二次解析:

4. 二次解析结果:
{"0": "region=Shanghai","1": "area=a1","2": "server=6.6.6.6","3": "user=testUser","4": "timeStamp=2022-02-26T22:25:33.210Z","0.region": "Shanghai","1.area": "a1","2.server": "6.6.6.6","3.user": "testUser","4.timeStamp": "2022-02-26T22:25:33.210Z"}
5. 对字段进行编辑、删减,调整时间戳格式,并新增当前系统时间字段:
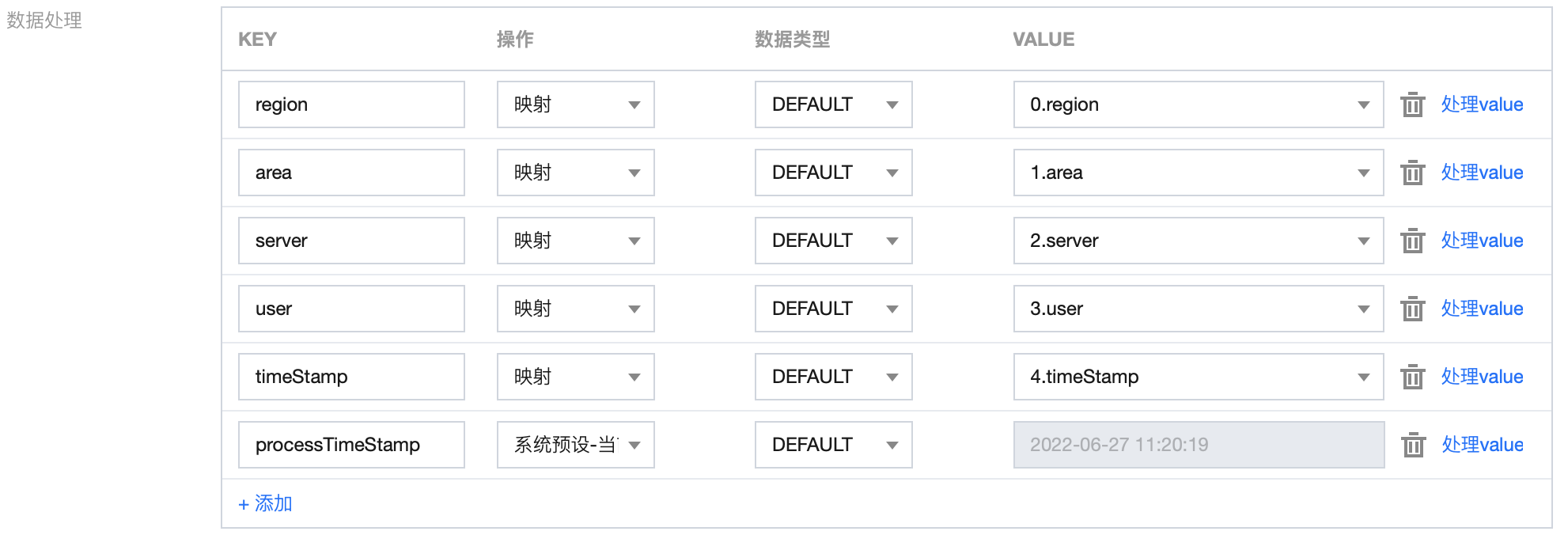
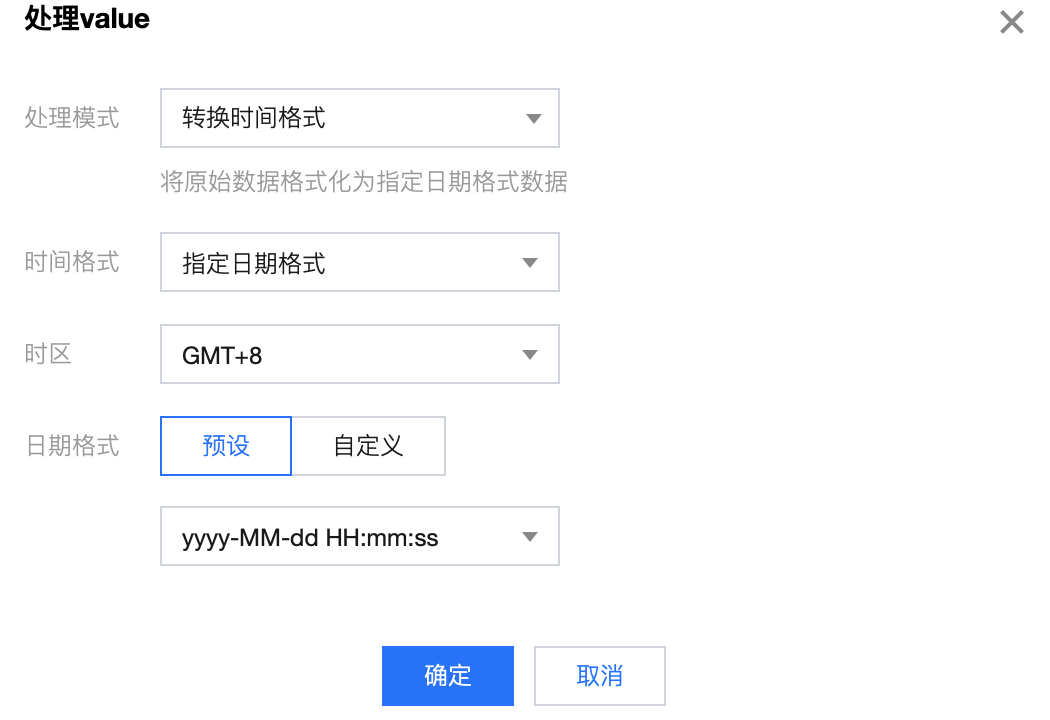
{"region": "Shanghai","area": "a1","server": "6.6.6.6","user": "testUser","timeStamp": "2022-02-27 06:25:33","processTimeStamp": "2022-06-27 11:14:49"}
