

腾讯云容器服务实战教程 - 在 TKE 集群中使用 NodeLocal DNS Cache
文档简介:
操作场景:
通过在集群节点上以 Daemonset 的形式运行 NodeLocal DNS Cache,能够大幅提升集群内 DNS 解析性能,以及有效避免 conntrack 冲突引发的 DNS 五秒延迟。
本文接下来将详细介绍如何在 TKE 集群中使用 NodeLocal DNS Cache。



操作场景
通过在集群节点上以 Daemonset 的形式运行 NodeLocal DNS Cache,能够大幅提升集群内 DNS 解析性能,以及有效避免 conntrack 冲突引发的 DNS 五秒延迟。
本文接下来将详细介绍如何在 TKE 集群中使用 NodeLocal DNS Cache。
操作原理
通过 DaemonSet 在集群的每个节点上部署一个 hostNetwork 的 Pod,该 Pod 是 node-cache,可以缓存本节点上 Pod 的 DNS 请求。如果存在 cache misses ,该 Pod 将会通过 TCP 请求上游 kube-dns 服务进行获取。原理图如下所示:
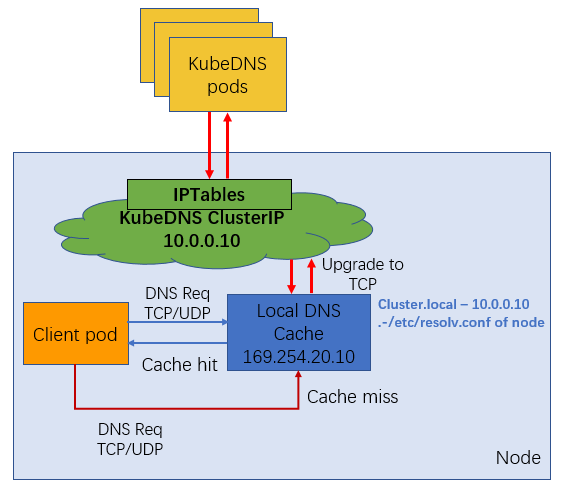
说明
NodeLocal DNS Cache 没有高可用性(High Availability,HA),会存在单点 nodelocal dns cache 故障(Pod Evicted/ OOMKilled/ConfigMap error/DaemonSet Upgrade),但是该现象其实是任何的单点代理(例如 kube-proxy,cni pod)都会存在的常见故障问题。
前提条件
已通过 容器服务控制台 创建了 Kubernetes 版本为 1.14 及以上的集群,且该集群中存在节点。
操作步骤
1. 一键部署 NodeLocal DNS Cache。YAML 示例如下:
---apiVersion: v1kind: ServiceAccountmetadata:name: node-local-dnsnamespace: kube-systemlabels:kubernetes.io/cluster-service: "true"addonmanager.kubernetes.io/mode: Reconcile---apiVersion: v1kind: ConfigMapmetadata:name: node-local-dnsnamespace: kube-systemdata:Corefile: |cluster.local:53 {errorscache {success 9984 30denial 9984 5}reloadloopbind 169.254.20.10forward . __PILLAR__CLUSTER__DNS__ {force_tcp}prometheus :9253health 169.254.20.10:8080}in-addr.arpa:53 {errorscache 30reloadloopbind 169.254.20.10forward . __PILLAR__CLUSTER__DNS__ {force_tcp}prometheus :9253}ip6.arpa:53 {errorscache 30reloadloopbind 169.254.20.10forward . __PILLAR__CLUSTER__DNS__ {force_tcp}prometheus :9253}.:53 {errorscache 30reloadloopbind 169.254.20.10forward . /etc/resolv.conf {force_tcp}prometheus :9253}---apiVersion: apps/v1kind: DaemonSetmetadata:name: node-local-dnsnamespace: kube-systemlabels:k8s-app: node-local-dnsspec:updateStrategy:rollingUpdate:maxUnavailable: 10%selector:matchLabels:k8s-app: node-local-dnstemplate:metadata:labels:k8s-app: node-local-dnsannotations:prometheus.io/port: "9253"prometheus.io/scrape: "true"spec:serviceAccountName: node-local-dnspriorityClassName: system-node-criticalhostNetwork: truednsPolicy: Default # Don't use cluster DNS.tolerations:- key: "CriticalAddonsOnly"operator: "Exists"- effect: "NoExecute"operator: "Exists"- effect: "NoSchedule"operator: "Exists"containers:- name: node-cacheimage: ccr.ccs.tencentyun.com/hale/k8s-dns-node-cache:1.15.13resources:requests:cpu: 25mmemory: 5Miargs: [ "-localip", "169.254.20.10", "-conf", "/etc/Corefile", "-setupiptables=true" ]securityContext:privileged: trueports:- containerPort: 53name: dnsprotocol: UDP- containerPort: 53name: dns-tcpprotocol: TCP- containerPort: 9253name: metricsprotocol: TCPlivenessProbe:httpGet:host: 169.254.20.10path: /healthport: 8080initialDelaySeconds: 60timeoutSeconds: 5volumeMounts:- mountPath: /run/xtables.lockname: xtables-lockreadOnly: false- name: config-volumemountPath: /etc/coredns- name: kube-dns-configmountPath: /etc/kube-dnsvolumes:- name: xtables-lockhostPath:path: /run/xtables.locktype: FileOrCreate- name: kube-dns-configconfigMap:name: kube-dnsoptional: true- name: config-volumeconfigMap:name: node-local-dnsitems:- key: Corefilepath: Corefile.base
2. 将 kubelet 的指定 dns 解析访问地址设置为 步骤1 中创建的 local dns cache。本文提供以下两种配置方法,请根据实际情况进行选择:
依次执行以下命令,修改 kubelet 启动参数并重启。
sed -i '/CLUSTER_DNS/c\CLUSTER_DNS="--cluster-dns=169.254.20.10"' /etc/kubernetes/kubelet
systemctl restart kubelet
根据需求配置单个 Pod 的 dnsconfig 后重启。YAML 核心部分参考如下:
需要将 nameserver 配置为169.254.20.10。
为确保集群内部域名能够被正常解析,需要配置 searches。
适当降低 ndots 值有利于加速集群外部域名访问。
当 Pod 没有使用带有多个 dots 的集群内部域名的情况下,建议将值设为2。
dnsConfig:nameservers: ["169.254.20.10"]searches:- default.svc.cluster.local- svc.cluster.local- cluster.localoptions:- name: ndotsvalue: "2"
配置验证
本次测试集群为 Kubernetes 1.14 版本集群。在通过上述步骤完成 NodeLocal DNSCache 组件部署之后,可以参照以下方法进行验证:
1. 选择一个 debug pod,调整 kubelet 参数或者配置 dnsConfig 后重启。
2. Dig 外网域名,尝试在 coredns pod 上抓包。
3.显示169.254.20.10正常工作即可证明 NodeLocal DNSCache 组件部署成功。如下图所示:

