

腾讯云计算加速套件 TACO Kit - TACO Train 加速 Stable Diffusion 模型训练
文档简介:
操作场景:
本文将演示如何使用 GPU 云服务器,训练 AI 绘画模型,结合 TACO Train 的加速能力助力您获得 4 倍以上的性能提升。



操作场景
本文将演示如何使用 GPU 云服务器,训练 AI 绘画模型,结合 TACO Train 的加速能力助力您获得 4 倍以上的性能提升。
操作步骤
购买高性能计算实例
购买实例,其中实例、存储及镜像请参见以下信息选择,其余配置请参见 通过购买页创建实例 按需选择。
实例:选择 GPU 型 HCCPNV4h、GPU 计算型 GT4。
镜像:建议选择公共镜像,支持自动安装 GPU 驱动。若选择 HCC 机型,公共镜像当中已安装 RDMA 网卡驱动。
操作系统请使用 CentOS 7.6、Ubuntu 18.04 或 TencentOS 2.4(TK4)。
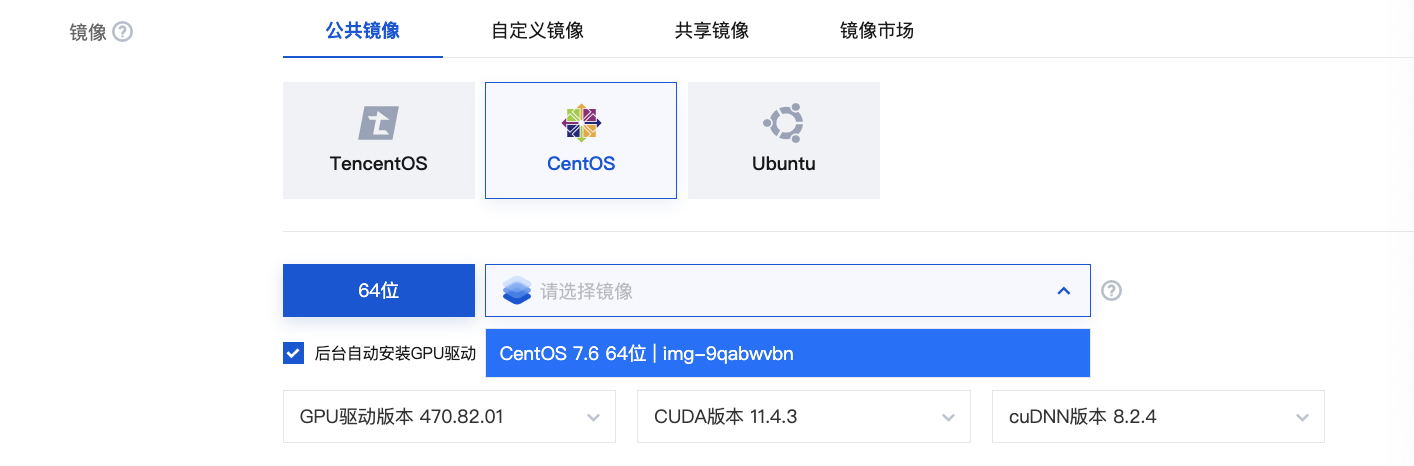
若您选择公共镜像,则请勾选后台自动安装 GPU 驱动,实例将在系统启动后预装对应版本驱动。如下图所示:
安装docker和NVIDIA docker
1. 参见 使用标准登录方式登录 Linux 实例,登录实例。
2. 执行以下命令,安装 docker。
curl -s -L http://mirrors.tencent.com/install/GPU/taco/get-docker.sh | sudo bash
若您无法通过该命令安装,请尝试多次执行命令,或参见 Docker 官方文档 Install Docker Engine 进行安装。
3. 执行以下命令,安装 nvidia-docker2。
curl -s -L http://mirrors.tencent.com/install/GPU/taco/get-nvidia-docker2.sh | sudo bash
若您无法通过该命令安装,请尝试多次执行命令,或参见 NVIDIA 官方文档 Installation Guide & mdash 进行安装。
启动训练环境
#!/bin/bashdocker run \-itd \--gpus all \--privileged --cap-add=IPC_LOCK \--ulimit memlock=-1 --ulimit stack=67108864 \--net=host \--ipc=host \--name=sd \ccr.ccs.tencentyun.com/qcloud/taco-train:torch20-cu117-bm-0.7.2docker exec -it sd bash
该镜像包含的软件版本信息如下:
OS:Ubuntu 20.04.5 LTS
python: 3.8.10
CUDA toolkits: V11.7.99
cuDNN: 8.5.0
pytorch: 2.0.0+cu117
DeepSpeed: 0.8.2
Transformers: 4.27.1
xformers: 0.0.17+6967620.d20230323
diffusers: 0.15.0.dev0 (main branch untill March/24/2023)
开始测试
cd /workspace/text_to_imagebash run.sh
测试代码来自 stable diffusers 官方的 examples。
说明:
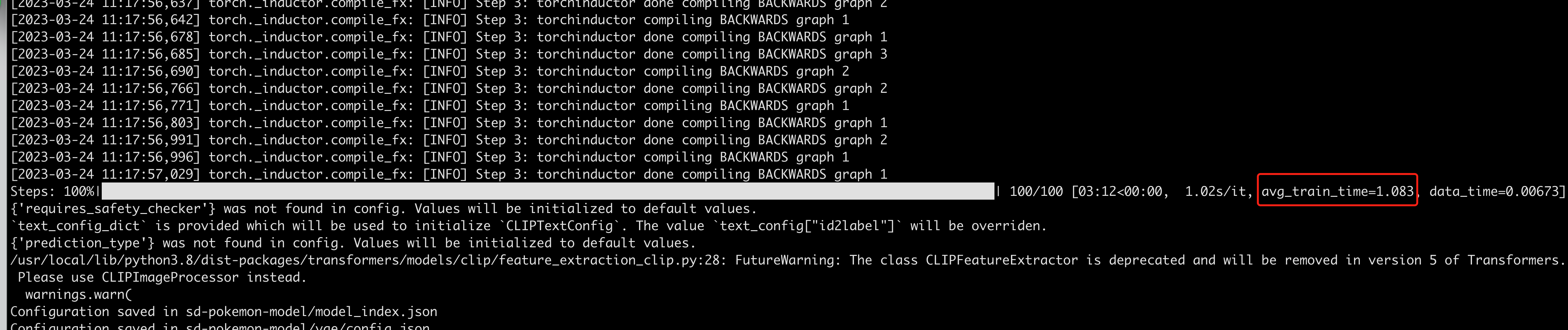
1. 原始的测试代码打印了单步的耗时,波动较大,这里对每步的训练耗时做了平均,方便性能对比。
2. 第一次运行训练脚本会下载预训练模型,耗时5分钟左右。
3. 模型和数据集信息来自 huggingface 官网。
训练过程中的输出如下:
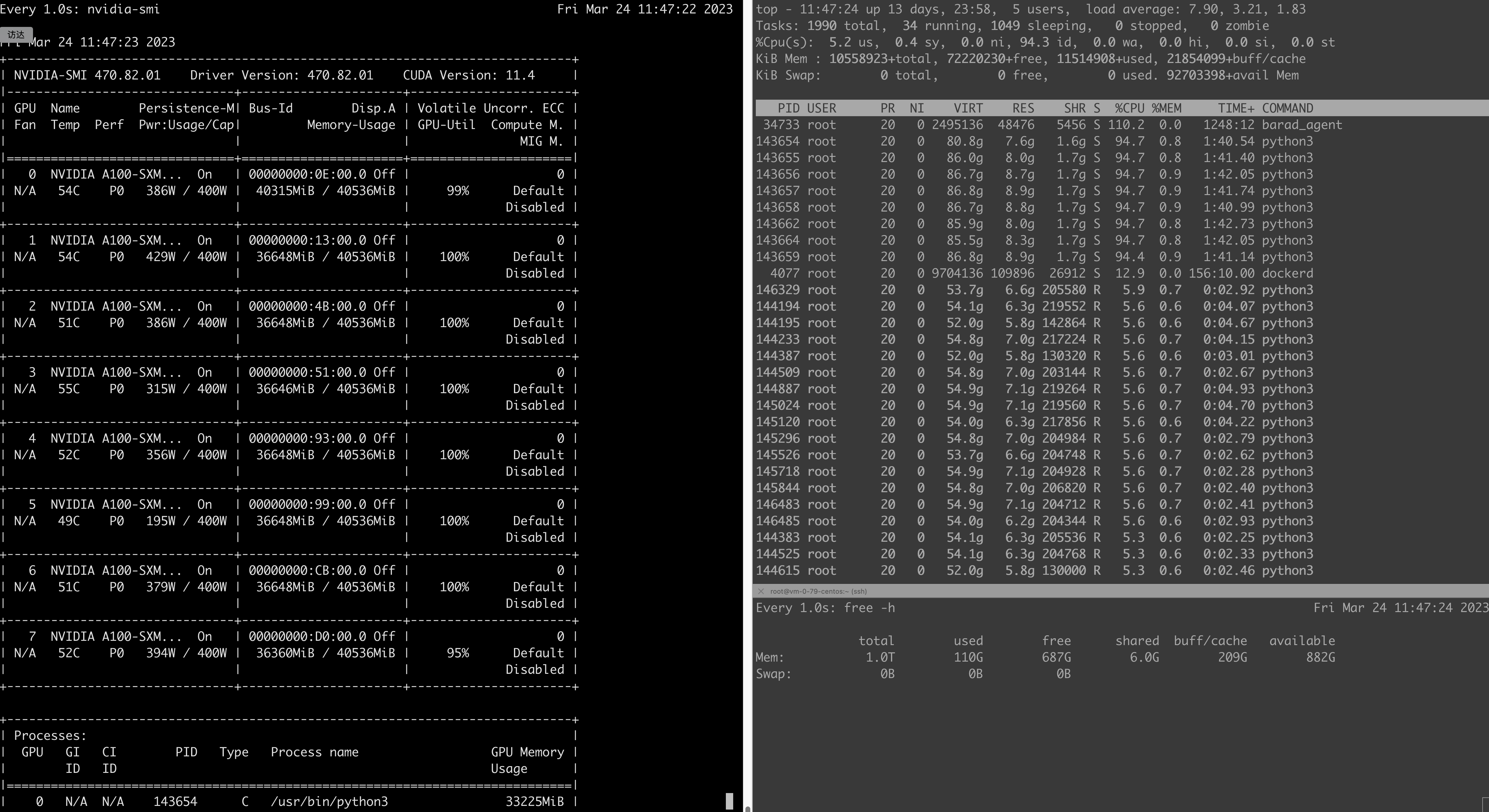
训练过程中的GPU/CPU/内存状态如下:
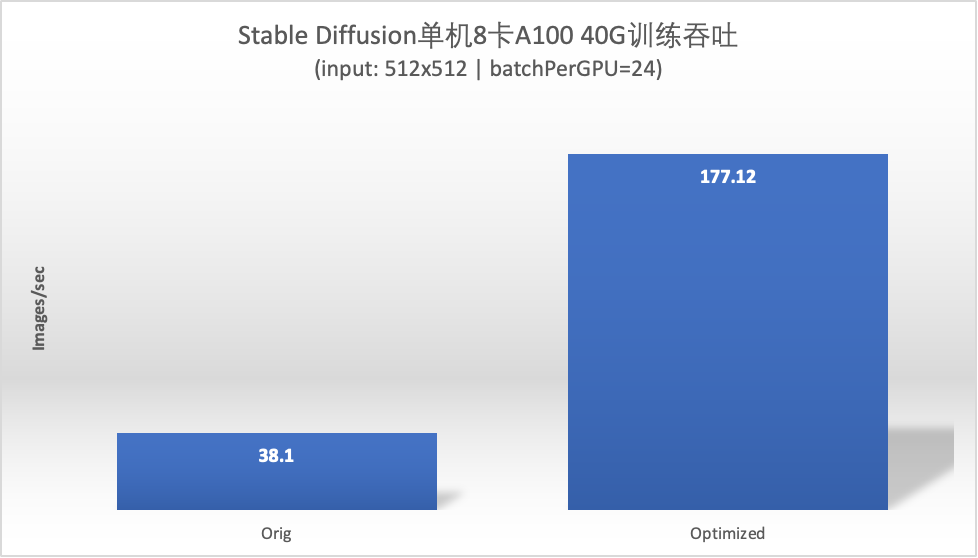
性能加速效果
总结
本文基于腾讯云高性能计算实例评测运行了官方Stable diffusion训练脚本,运行过程中通过性能分析挖掘了若干个训练性能优化方向并加以实施,最终取得了4倍多的性能提升。
