文档简介:



本章节介绍如何在数据开发模块上进行MRS Spark Python作业开发。
案例一:通过MRS Spark Python作业实现统计单词的个数
前提条件:
具有OBS相关路径的访问权限。
数据准备:
- 准备脚本文件"wordcount.py",具体内容如下:
# -*- coding: utf-8 -*
import sys
from pyspark import SparkConf, SparkContext
def show(x):
print(x)
if __name__ == "__main__":
if len(sys.argv) < 2:
print ("Usage: wordcount <inputPath> <outputPath>")
exit(-1)
#创建SparkConf
conf = SparkConf().setAppName("wordcount")
#创建SparkContext 注意参数要传递conf=conf
sc = SparkContext(conf=conf)
inputPath = sys.argv[1]
outputPath = sys.argv[2]
lines = sc.textFile(name = inputPath)
#每一行数据按照空格拆分 得到一个个单词
words = lines.flatMap(lambda line:line.split(" "),True)
#将每个单词 组装成一个tuple 计数1
pairWords = words.map(lambda word:(word,1),True)
#使用3个分区 reduceByKey进行汇总
result = pairWords.reduceByKey(lambda v1,v2:v1+v2)
#打印结果
result.foreach(lambda t :show(t))
#将结果保存到文件
result.saveAsTextFile(outputPath)
#停止SparkContext
sc.stop()复制
需要将编码格式设置为“UTF-8”,否则后续脚本运行时会报错。
-
准备数据文件“in.txt”,内容为一段英文单词。
操作步骤 :
- 将脚本和数据文件传入OBS桶中,如下图。
上传文件至OBS桶

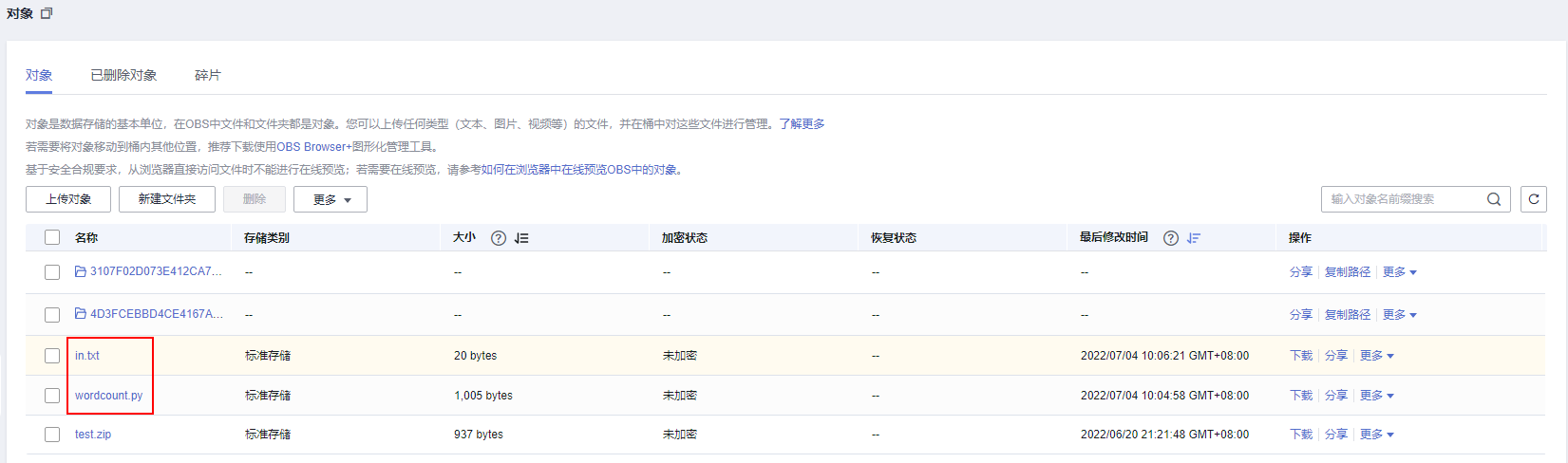
本例中,wordcount.py和in.txt文件上传路径为:obs://obs-tongji/python/
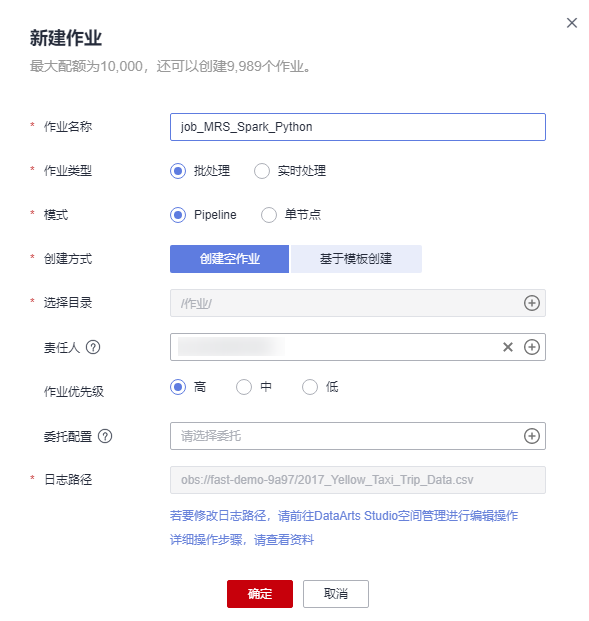
- 创建一个数据开发模块空作业,作业名称为“job_MRS_Spark_Python”。
新建作业

- 进入到作业开发页面,拖动“MRS Spark Python”节点到画布中并单击,配置节点的属性。
配置MRS Spark Python节点属性

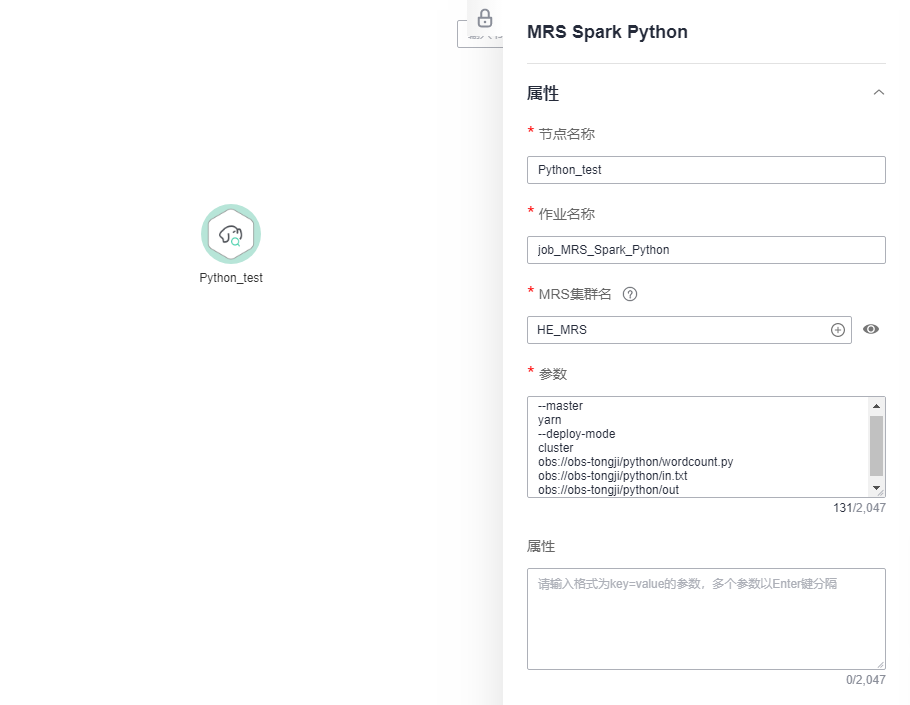
参数设置说明:
--master
yarn
--deploy-mode
cluster
obs://obs-tongji/python/wordcount.py
obs://obs-tongji/python/in.txt
obs://obs-tongji/python/out复制
其中:
obs://obs-tongji/python/wordcount.py为脚本存放路径;
obs://obs-tongji/python/in.txt为wordcount.py的传入参数路径,可以把需要统计的单词写到里面;
obs://obs-tongji/python/out为输出参数文件夹的路径,并且会在OBS桶中自动创建该目录(如已存在out目录,会报错)。
- 单击“测试运行”,执行该脚本作业。
- 待测试完成,执行“提交”。
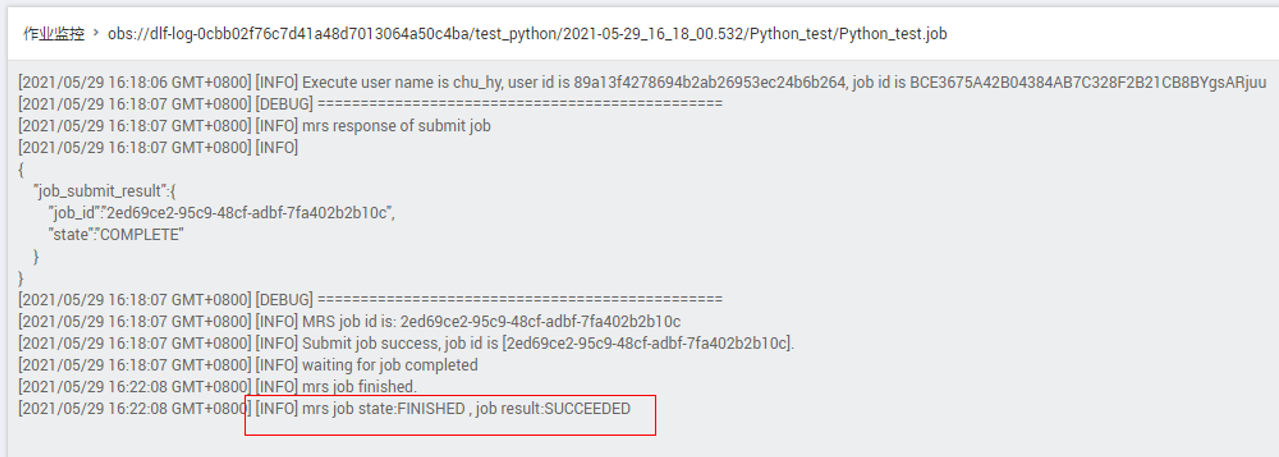
- 在“作业监控”界面,查看作业执行结果。
详见下图:查看作业执行结果

作业日志中显示已运行成功
详见下图:作业运行日志

详见下图:作业运行状态


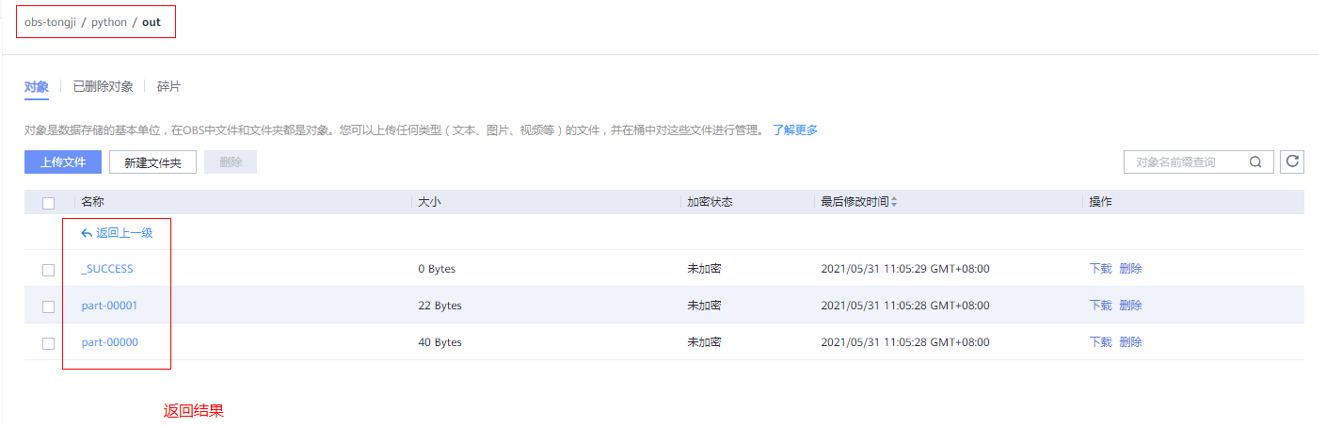
- 查看OBS桶中返回的记录。(没设置返回可跳过)
详见下图:查看OBS桶返回记录

案例二:通过MRS Spark Python作业实现打印输出"hello python"
前提条件:
具有OBS相关路径的访问权限。
数据准备:
准备脚本文件"zt_test_sparkPython1.py",具体内容如下:
from pyspark import SparkContext, SparkConf
conf = SparkConf().setAppName("master"). setMaster("yarn")
sc = SparkContext(conf=conf)
print("hello python")
sc.stop()复制
操作步骤:
- 将脚本文件传入OBS桶中。
- 创建一个数据开发模块空作业。
- 进入到作业开发页面,拖动“MRS Spark Python”节点到画布中并单击,配置节点的属性。
参数设置说明:
--master
yarn
--deploy-mode
cluster
obs://obs-tongji/python/zt_test_sparkPython1.py复制
其中:zt_test_sparkPython1.py 为脚本所在路径
- 单击“测试运行”,执行该脚本作业。
- 待测试完成,执行“提交”。
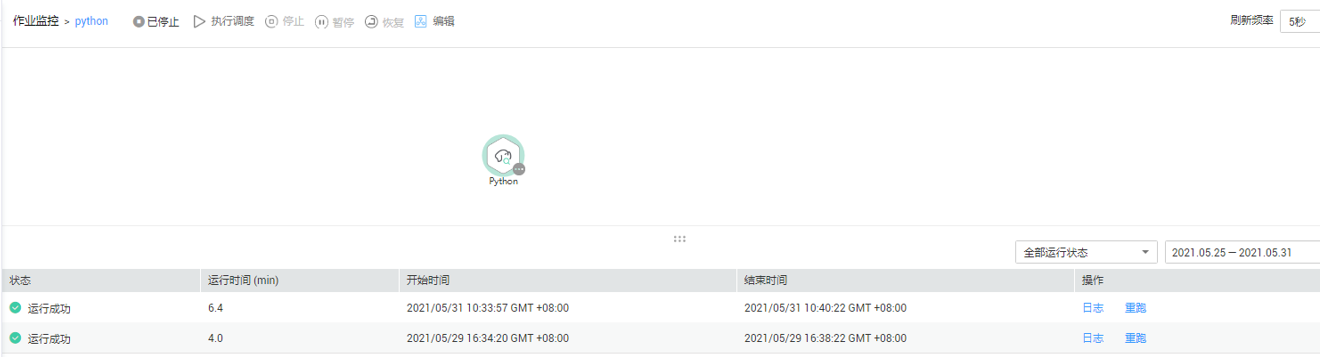
- 在“作业监控”界面,查看作业执行结果。
详见下图:查看作业执行结果

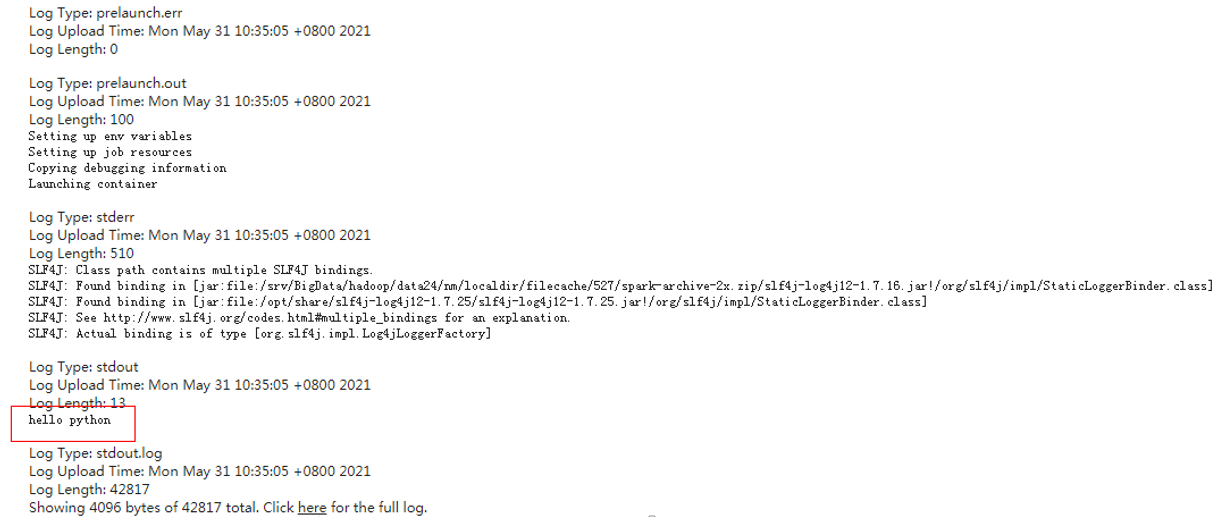
- 日志验证。
运行成功后,登录MRS manager后在YARN上查看日志,发现有hello python的输出。
详见下图:查看YARN上日志