

天翼云边缘容器集群(ECK专有版)工作负载管理 - 使用GPU
文档简介:
介绍如何调度使用GPU。
前提条件:
1.创建GPU类型节点。
2.安装GPU组件。
创建工作负载时,申请GPU资源,按如下方法配置,指定工作负载可使用GPU的数量。
1.登录边缘容器集群控制台。
2.在控制台左侧导航栏中,单击 集群管理 。



介绍如何调度使用GPU。
前提条件:
1.创建GPU类型节点。
2.安装GPU组件。
创建工作负载时,申请GPU资源,按如下方法配置,指定工作负载可使用GPU的数量。
1.登录边缘容器集群控制台。
2.在控制台左侧导航栏中,单击 集群管理 。
3.在集群列表页面中,单击目标集群右侧操作列下的 详情 。
4.在控制台左侧导航栏中,单击 工作负载>无状态 。
5.在无状态负载列表,单击左上角的 创建无状态负载 。
6.在容器配置页面,勾选GPU配额,并指定使用的比例和大小,在调度时ECK会自动将负载调度到有GPU的节点。
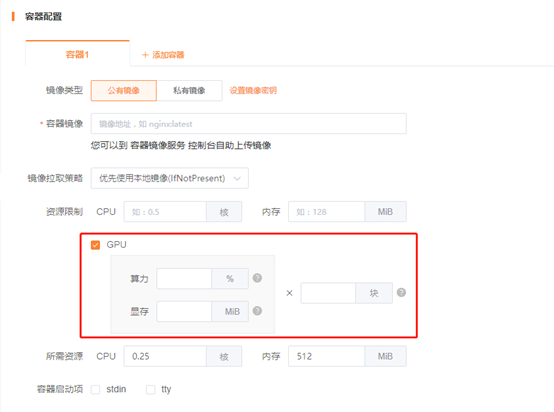
| 配置项 | 描述 |
|---|---|
| 容器块数 | 支持配置容器最多可占用几GPU卡。 |
| 算力 | 容器可占用每块GPU算力的最大比例。 |
| 显存 | 容器可占用每块GPU算力的最大比例。 |
也可以通过在yaml文件添加以下内容实现GPU资源配置:
- apiVersion: apps/v1
kind: Deployment
metadata:
name: ''
labels:
app: ''
annotations:
kubernetes.io/change-cause: ''
namespace: default
spec:
replicas: 2
selector:
matchLabels:
app: ''
template:
metadata:
labels:
app: ''
annotations: {}
spec:
initContainers: []
containers:
- name: ''
image: ''
imagePullPolicy: IfNotPresent
command: []
args: []
env: []
envFrom: []
stdin: false
tty: false
gpuChecked: true
resources:
requests:
cpu: 0.25
memory: 512Mi
ideal.com/vcuda-core: 80
ideal.com/vcuda-memory: 200
ideal.com/gpu: 2
limits:
ideal.com/vcuda-core: 80
ideal.com/vcuda-memory: 200
ideal.com/gpu: 2
volumeMounts: []
ports: []
livenessProbe: null
readinessProbe: null
startupProbe: null
lifecycle: null
securityContext:
privileged: false
imagePullSecrets: []复制
GPU节点标签
创建GPU节点后,ECK会给节点打上对应标签,不同类型的GPU节点有不同标签,利用GPU节点标签可以灵活地将应用调度到具有GPU设备的节点上。
选择一个GPU节点,执行以下命令,查看该GPU节点的标签。
kubectl describe node fj-xiamen-4.172.16.0.6复制
返回值:
Name: fj-xiamen-4.172.16.0.6
Roles: <none>
Labels: apps.openyurt.io/desired-nodepool=06b59c8e-d0a4-44be-8f27-e8219f2a51f6
apps.openyurt.io/nodepool=06b59c8e-d0a4-44be-8f27-e8219f2a51f6
beta.kubernetes.io/arch=amd64
beta.kubernetes.io/os=linux
gpu-model=NVIDIA-GeForce-RTX-3060
kubernetes.io/arch=amd64
kubernetes.io/hostname=fj-xiamen-4.172.16.0.6
kubernetes.io/os=linux
node-type=gpu
nvidia-device-enable=enable
openyurt.io/is-edge-worker=false复制
在使用GPU时,可以根据标签让Pod与节点亲和,从而让Pod选择正确的节点,如下所示。
apiVersion: apps/v1
kind: Deployment
metadata:
name: gpu-test
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: gpu-test
template:
metadata:
labels:
app: gpu-test
spec:
nodeSelector:
gpu-model: NVIDIA-GeForce-RTX-3060
containers:
- image: nginx:perl
name: container-0
resources:
requests:
cpu: 250m
memory: 512Mi
nvidia.com/gpu: 1 # 申请GPU的数量
limits:
cpu: 250m
memory: 512Mi
nvidia.com/gpu: 1 # GPU数量的使用上限
imagePullSecrets:
- name: default-secret