

文档简介:



云数据库ClickHouse可通过命令行客户端进行连接。
本节演示命令行客户端通过TCP端口9000连接云数据库ClickHouse。
1、根据ClickHouse版本下载对应客户端
2、使用下列命令连接集群。
clickhouse-client --host=<host> --port=<port> --user=<user> --password=<password>复制
参数说明:
host:集群节点ip地址。
port:host地址参数连接串上显示的端口号。
user:数据库用户名。
password:数据库用户密码。
更多详细的参数可以使用 clickhouse-client --help 查看。
3、示例
以一个2节点的单副本集群为例,演示命令行客户端操作,示例集群节点信息如下:集群名inst_2shards_1replicas
| ClickHouse节点IP | TCP端口 | HTTP端口 | 分片(shard) | 副本数量 |
|---|---|---|---|---|
| 192.168.90.207 | 9000 | 8123 | 1 | 1 |
| 192.168.90.208 | 9000 | 8123 | 2 | 1 |
(1)连接命令行客户端
clickhouse-client -h IP地址 --port TCP端口 -u 用户名 --password 密码复制
(2)创建表
集群模式下创建表分为两个步骤,第一步创建本地表,第二步是创建分布式表。如果只创建本地表而不创建分布式表,那么本地表的数据仅所在节点可见其它节点不可见。
a) 创建本地表
CREATE TABLE IF NOT EXISTS tutorial.events_local ON CLUSTER 'inst_2shards_1replicas' ( \
ts_date Date,\
ts_date_time DateTime,\
user_id Int64,\
event_type String,\
site_id Int64,\
groupon_id Int64,\
category_id Int64,\
merchandise_id Int64,\
search_text String\
)\
ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/tutorial/events_local','{replica}')\
PARTITION BY ts_date\
ORDER BY(ts_date,toStartOfHour(ts_date_time),site_id,event_type)\
SETTINGS index_granularity = 8192;复制
其中,ON CLUSTER语法表示分布式DDL,即执行一次就可在集群所有实例上创建同样的本地表。Tutorial和 events_local分别是数据库和本地表名,inst_2shards_1replicas是集群名。ReplicatedMergeTree是表引擎,PARTITION BY指定分区键。 集群标识符{cluster}、分片标识符{shard}和副本标识符{replica}来自复制表宏配置,即配置文件中一节的内容,配合 ON CLUSTER语法一同使用,可以避免建表时在每个实例上反复修改这些值。
b) 创建分布式表
CREATE TABLE IF NOT EXISTS tutorial.events_all ON CLUSTER ‘inst_2shards_1replicas’\
AS tutorial.events_local\
ENGINE = Distributed(inst_2shards_1replicas,tutorial,events_local,rand());复制
创建分布式表是读时检查的机制,也就是说对创建分布式表和本地表的顺序并没有强制要求。
(3)插入数据
insert into events_all (ts_date,ts_date_time,user_id,event_type,site_id,groupon_id,category_id,
merchandise_id,search_text)values('2020-08-01','2020-08-01 09:30:01',10009,'event1',10,20,30,40,'search text');
insert into events_all (ts_date,ts_date_time,user_id,event_type,site_id,groupon_id,category_id,
merchandise_id,search_text)values('2020-08-02','2020-08-02 09:30:01',10009,'event1',10,20,30,40,'search text');
insert into events_all (ts_date,ts_date_time,user_id,event_type,site_id,groupon_id,category_id,
merchandise_id,search_text)values('2020-08-03','2020-08-02 09:30:01',10009,'event2',10,20,30,40,'search text');
insert into events_all (ts_date,ts_date_time,user_id,event_type,site_id,groupon_id,category_id
,merchandise_id,search_text)values('2020-08-04','2020-08-03 10:30:01',10009,'event3',10,20,30,40,'search text');
insert into events_all (ts_date,ts_date_time,user_id,event_type,site_id,groupon_id,category_id,
merchandise_id,search_text)values('2020-08-05','2020-08-04 11:30:01',10009,'event4',10,20,30,40,'search text');复制
(4)查看分布式表
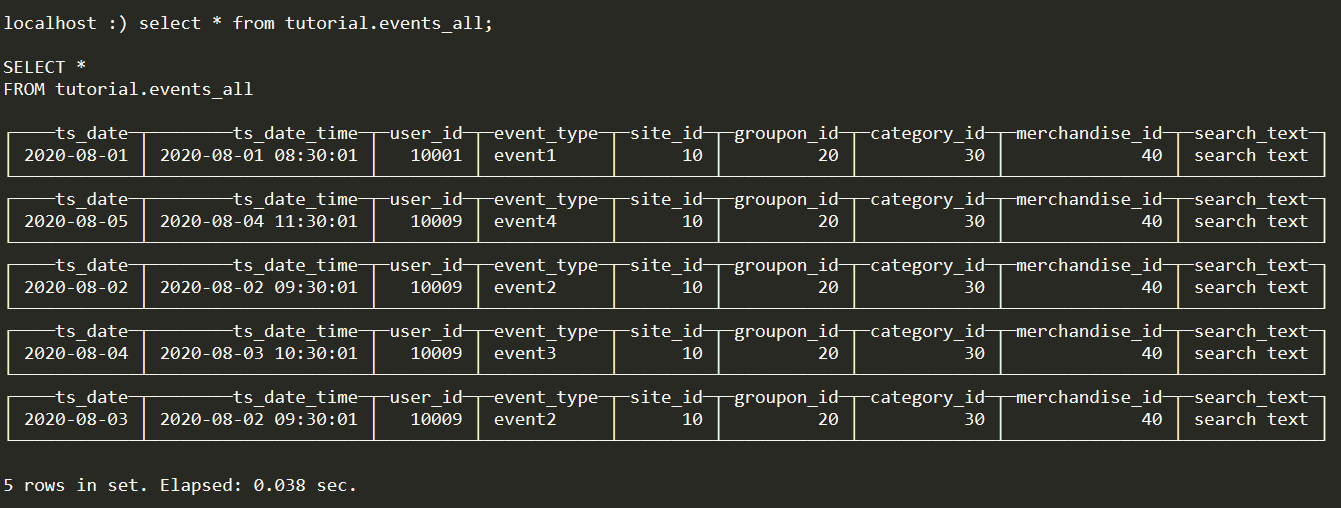
(5)查看本地表
查看192.168.90.207节点
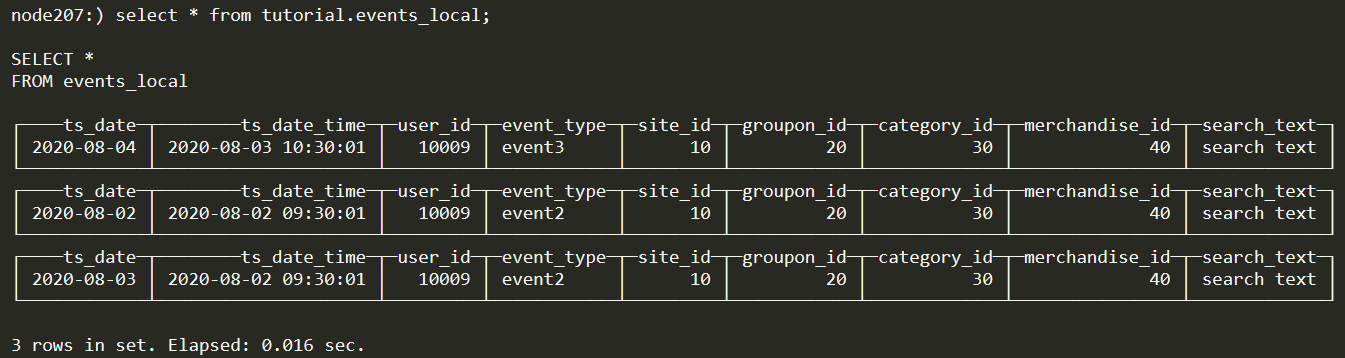
查看192.168.90.208节点
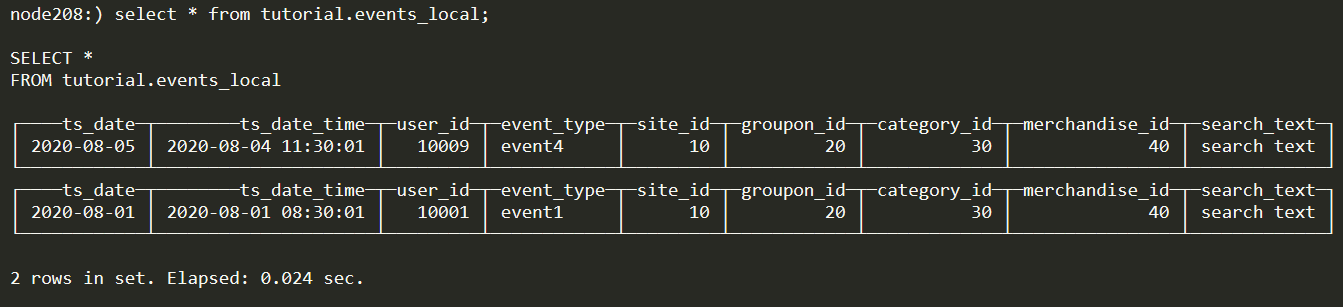
可以发现数据分布在不同的节点上。由此说明数据实际上保存在各个节点的本地表中,而分布式表可以看做一个视图,将本地表的数据联合起来。
