




接口描述
统计图像中的人体个数和流动趋势,主要适用于低空俯拍、出入口场景,以人体头肩为主要识别目标,核心功能:
- 静态人数统计:传入单帧图像,检测图片中的人体头肩,返回图中总人数。
- 动态人数统计和跟踪:传入监控视频抓拍图片序列,进行人体追踪,返回每个人体框的坐标和所属ID;并根据目标轨迹判断进出区域行为,进行动态人数统计,返回区域进出人数。同时可输出渲染结果图(含统计值和跟踪框渲染)。(注:抽帧频率需>2fps,否则无法有效跟踪,建议5fps,接口默认保证5qps,每天赠送5万次免费调用量,以便充分测试。)
渲染图示例:

在线调试
您可以在 示例代码中心 中调试该接口,可进行签名验证、查看在线调用的请求内容和返回结果、示例代码的自动生成。
请求说明
请求示例
HTTP 方法:POST
请求URL:https://aip.baidubce.com/rest/2.0/image-classify/v1/body_tracking
URL参数:
| 参数 | 值 |
|---|---|
| access_token | 通过API Key和Secret Key获取的access_token,参考“Access Token获取” |
Header如下:
| 参数 | 值 |
|---|---|
| Content-Type | application/x-www-form-urlencoded |
Body中放置请求参数,参数详情如下:
请求参数
| 参数 | 是否必选 | 类型 | 可选值范围 | 说明 |
|---|---|---|---|---|
| dynamic | 是 | string | true,false | true:动态人流量统计,返回总人数、跟踪ID、区域进出人数; false:静态人数统计,返回总人数 |
| case_id | 当dynamic为True时,必填 | int32 | - | 任务ID(通过case_id区分不同视频流,自拟,不同序列间不可重复即可) |
| case_init | 当dynamic为True时,必填 | string | true,false | 每个case的初始化信号,为true时对该case下的跟踪算法进行初始化,为false时重载该case的跟踪状态。当为false且读取不到相应case的信息时,直接重新初始化 |
| image | 是 | string | - | 图像数据,base64编码后进行urlencode,要求base64编码和urlencode后大小不超过4M。图片的base64编码是不包含图片头的,如(data:image/jpg;base64,),支持图片格式:jpg、bmp、png,最短边至少50px,最长边最大4096px。 |
| show | 否 | string | true,false | 是否返回结果图(含统计值和跟踪框渲染),默认不返回,选true时返回渲染后的图片(base64),其它无效值或为空则默认false |
| area | 当dynamic为True时,必填 | string | 小于原图像素范围 | 静态人数统计时,只统计区域内的人,缺省时为全图统计。 动态人流量统计时,进出区域的人流会被统计。 逗号分隔,如‘x1,y1,x2,y2,x3,y3...xn,yn',按顺序依次给出每个顶点的xy坐标(默认尾点和首点相连),形成闭合多边形区域。 服务会做范围(顶点左边需在图像范围内)及个数校验(数组长度必须为偶数,且大于3个顶点)。只支持单个多边形区域,建议设置矩形框,即4个顶点。坐标取值不能超过图像宽度和高度,比如1280的宽度,坐标值最小建议从1开始,最大到1279。 |
请求代码示例
提示一:使用示例代码前,请记得替换其中的示例Token、图片地址或Base64信息。
提示二:部分语言依赖的类或库,请在代码注释中查看下载地址。
人流量统计(动态版) curl -i -k 'https://aip.baidubce.com/rest/2.0/
image-classify/v1/body_tracking?access_token=【调用鉴权接口获取的token】
' --data 'area=1,1,719,1,719,719,1,719&case_id=1&case_init=false&dynami
c=true&image=【图片Base64编码,需UrlEncode】' -H 'Content-Type:application/x-www-form-urlencoded'
area参数设置说明
进出区域方向:从区域外走到区域内就是in,相反就是out,详见下方示例。
示例1:
如下图,area区域框三条边贴着图像左方边缘,从图像右方往左走到框里就是in,从图像左方往右走出框就是out,相当于只有图像中间那条线起作用。
如果想要从图像左方向右走是in,就把框画在图像右半部分,上、下、右三条边贴着图像边缘。

同理,上下方向,如果area区域框三条边贴着图像下方边缘,从图像上方往下走到框里就是in,从图像下方往上走出框就是out,相当于只有图像中间那条线起作用。如果想要从图像下方向上走是in,就把框画在图像上半部分,上、左、右三条边贴着图像边缘。
示例2:
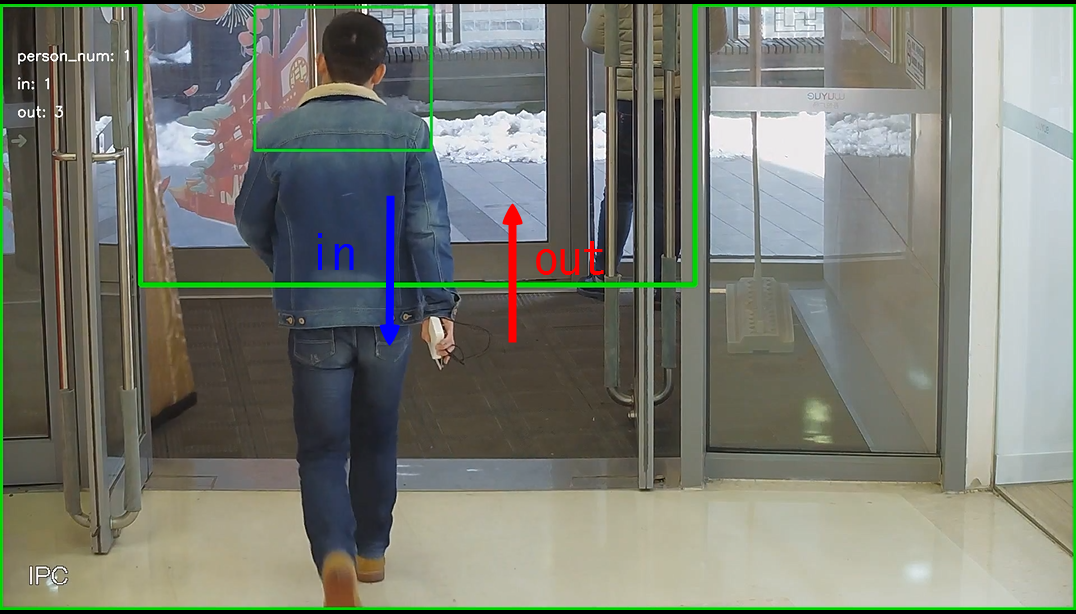
如下图,area区域是一个不规则多边形,将画面中门口以外的部分都框起来了,蓝色箭头的方向代表in,人从门外走进区域框里,红色箭头的方向代表out,人走出区域框,走向门外。
返回说明
返回参数
| 字段 | 是否必选 | 类型 | 说明 |
|---|---|---|---|
| person_num | 是 | int | 检测到的人体框数目 |
| person_info | 否 | object[] | 每个框的具体信息 |
| +location | 否 | object | 跟踪到的人体框位置 |
| ++left | 否 | int | 人体框左坐标 |
| ++top | 否 | int | 人体框顶坐标 |
| ++width | 否 | int | 人体框宽度 |
| ++height | 否 | int | 人体框高度 |
| +ID | 否 | int | 人体的ID编号,ID的取值逻辑为:每个case从1开始,不同人体向上递增但不一定连续 |
| person_count | 否 | object | 进出区域的人流统计 |
| +in | 否 | int | 当前帧进入区域的瞬时人数,一般情况下,当人体头肩检测框刚好完全进入area区域框时,该画面帧的in计数1;如要计算某一段时间内进入区域的累计人数,可基于连续帧图片的返回结果计算得到 |
| +out | 否 | int | 当前帧进入区域的瞬时人数,一般情况下,当人体头肩检测框刚好完全离开area区域框时,该画面帧的out计数1;如要计算某一段时间内进入区域的累计人数,可基于连续帧图片的返回结果计算得到 |
| image | 否 | string | 结果图,含跟踪框和统计值(渲染jpg图片byte内容的base64编码,得到后先做base64解码再以字节流形式imdecode) |
渲染结果图说明
画面里刚出现的人体头肩检测框都是红色,被跟踪锁定之后会变成其他颜色(颜色随机,不同颜色没有特定规律),模型根据同颜色框的运动轨迹来判断进出移动方向;人体被跟踪锁定后,检测框上方会出现人体的ID编号,ID的取值逻辑为:每个case从1开始,不同人体向上递增但不一定连续。
返回示例
未检测到任何人:
{
"person_num":0,
"person_info":[]
“person_count”:
{
"in":0,
"out":0
}
}
检测到2个人,无轨迹,无人进出区域:
{
"person_num":2,
"person_info":[]
“person_count”:
{
"in":0,
"out":0
}
}
检测到2个人和2条轨迹,1人离开区域:
{
"person_num":2,
"person_info":
[
{
"ID":3
"location":
{
"left": 100,
"top": 200,
"width": 200,
"height": 400,
}
}
{
"ID": 5
"location":
{
"left": 400,
"top": 200,
"width": 200,
"height": 400,
}
}
]
“person_count”:
{
"in":0,
"out":1
}
}
